






1 auc指标
- AUC的两种意义
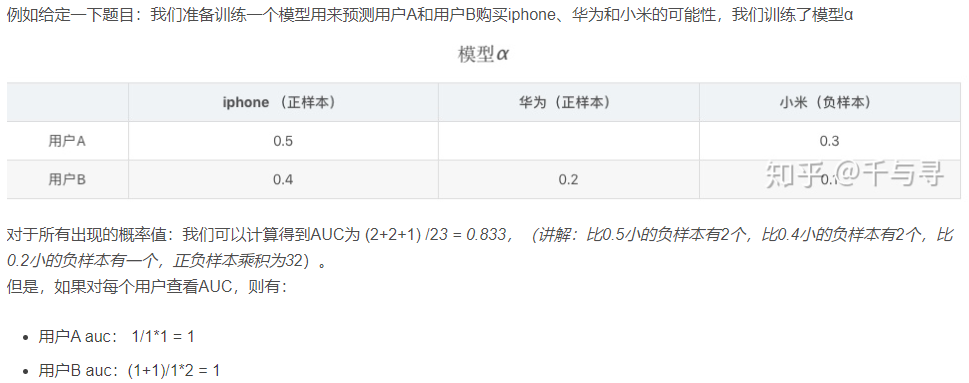
- 一个是ROC曲线的面积
- 另外一个是统计意义。从统计学角度理解,AUC等于随机挑选一个正样本和负样本时,模型对正样本的预测分数大于负样本的预测分数的概率。下图为搜广推场景下的一个计算auc的例子

2 GAUC指标
- 就是在推荐系统里按照用户分别求auc,然后加权平均
3 点击率 (CTR)
点击率是指用户点击推荐内容的概率。CTR 是衡量推荐项目吸引用户点击的有效性的关键指标。预测点击率的重要性包括:
- 优化内容曝光: 通过预测哪些项目可能会获得更高的点击率,推荐系统可以优化内容的排列和曝光策略,从而提高整体的用户互动。
- 提升转化率: 在电商和广告领域,高点击率通常与高转化率相关联。精准预测点击率有助于推送更可能导致实际购买或完成目标行为的推荐。
- 算法训练: CTR 预测模型通常用作学习用户偏好和行为的基础,帮助改进算法的准确性和相关性。
4 点击时长
点击时长是用户在点击某个推荐内容后在该页面上停留的时间。这个指标可以提供用户对推荐内容兴趣和满意度的深入见解。其重要性包括:
- 衡量用户满意度:用户在内容上花费的时间越长,通常意味着他们对内容越满意。长时间的停留可能表明内容与用户需求高度相关或具有较高质量。
- 改善内容质量:通过分析点击时长,推荐系统可以识别哪些类型的内容更能吸引用户深度参与,从而调整内容推荐策略,优先推荐可能引发长时间参与的内容。
- 增强用户粘性:提供能够引起用户长时间停留的内容有助于增加用户对平台的整体粘性和忠诚度。
5 整合CTR和点击时长
将点击率和点击时长的预测结合起来,可以为推荐系统提供一个更全面的评估框架。例如,一个内容即使点击率很高,如果点击后的停留时间很短,可能表明内容虽然具有吸引点击的外表,但实际内容质量并不高。相反,如果一个内容点击率不高,但点击后用户的停留时间长,这可能表明内容质量高,只是缺乏足够的曝光。
6 不确定性加权损失(Uncertainty Weighted Loss)
这种方法是由 Kendall, Yarin, et al. 在论文 “Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics” 中提出的。其核心思想是为每个任务引入一个可学习的权重参数,这些权重参数反映了每个任务在总损失中的相对重要性,这些权重是根据任务的不确定性动态调整的。
在多任务学习中,如果我们有两个任务,比如预测点击率和预测点击时长,传统的方法可能是简单地将这两个任务的损失函数相加。然而,这种方法未能考虑到不同任务的固有难度和不确定性。在不确定性加权的方法中,损失函数被修改为:
T
o
t
a
l
L
o
s
s
=
1
2
σ
C
T
R
2
L
o
s
s
C
T
R
+
1
2
σ
D
u
r
a
t
i
o
n
2
L
o
s
s
D
u
r
a
t
i
o
n
+
l
o
g
σ
C
T
R
+
l
o
g
σ
D
u
r
a
t
i
o
n
\mathrm{Total~Loss}=\frac{1}{2\sigma_{\mathrm{CTR}}^{2}}\mathrm{Loss}_{\mathrm{CTR}}+\frac{1}{2\sigma_{\mathrm{Duration}}^{2}}\mathrm{Loss}_{\mathrm{Duration}}+\mathrm{log}\sigma_{\mathrm{CTR}}+\mathrm{log}\sigma_{\mathrm{Duration}}
Total Loss=2σCTR21LossCTR+2σDuration21LossDuration+logσCTR+logσDuration
其中,
σ
CTR
\sigma_{\text{CTR}}
σCTR 和
σ
Duration
\sigma_{\text{Duration}}
σDuration 是与每个任务相关的不确定性参数,这些参数可以通过训练得到。这里的
σ
\sigma
σ 值越大,表明对应任务的不确定性越高,因此该任务的损失权重就越低。
使用 uncertain_loss 的优势在于:
- 自动调整权重:每个任务的损失贡献是根据其不确定性动态调整的,这有助于在训练过程中自动平衡不同任务的贡献。
- 提升模型性能:通过考虑任务的固有不确定性,模型可以更加聚焦于那些“更确定”的任务,从而提高整体性能。
- 灵活性高:这种方法不仅限于两个任务,也可以扩展到多个任务的场景。
7 混排模型不同类型的结果的采样比例对指标影响
混排模型通常涉及对多种类型的搜索结果(如文本、图片、视频、广告等)进行整合和排序,目的是提供一个综合且相关性高的结果列表。调整这些不同类型结果的采样比例,可以影响模型学习的偏好和优化方向。
-
影响模型的偏差和方差
不同类型结果的采样比例直接影响训练数据的代表性和多样性。如果某一类型的结果被过度采样,模型可能会过于偏向于这类结果,从而在处理其他类型结果时性能下降。相反,如果采样比例较为均衡,模型能够更好地学习到各类型结果的特点,提高泛化能力。 -
改变优化目标
在混排模型中,不同类型的结果可能对应不同的业务目标。例如,电商搜索中的商品列表和推广广告可能有不同的转化率和盈利模式。调整这些结果的采样比例,实际上是在调整模型优化的重点,可能会影响到整体的业务效益和用户满意度。 -
影响模型的评估指标
在实际应用中,模型的评估指标(如点击率、转化率、用户停留时间等)可能会因为不同类型结果的权重分布而变化。例如,如果模型更多地展示了用户偏好点击的结果类型,点击率可能会提高;如果展示了更多内容丰富或用户感兴趣的结果,用户的停留时间可能会增长。 -
处理类别不平衡问题
在某些情况下,不同类型的结果在数据集中可能本身就存在不平衡(如某类结果非常稀少)。这时,调整采样比例是一种常见的处理类别不平衡的方法,可以帮助模型更好地学习到少数类的特征,避免被多数类完全主导。
8 PNR指标
在推荐系统中,PNR(Positive-Negative Ratio)指标是一种用来衡量推荐列表中正例与负例的比例。这个指标主要用于评估推荐系统的质量,尤其是在二分类问题中,比如用户点击与否、喜欢与不喜欢等场景。
PNR 定义为推荐列表中正例(用户感兴趣的项目)和负例(用户不感兴趣的项目)的数量比。具体公式为: P N R = N p o s i t i v e N n e g a t i v e \mathrm{PNR}=\frac{N_\mathrm{positive}}{N_\mathrm{negative}} PNR=NnegativeNpositive
PNR对于理解推荐列表的多样性和平衡性具有重要意义。一个健康的推荐系统不仅仅是推荐用户可能感兴趣的项目(正例),同时也应避免过度推荐那些用户可能不感兴趣的项目(负例)。通过监控PNR,可以帮助推荐系统设计者调整算法,以达到更好的推荐效果。















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









