






一、数据库属性CHAR和VARCHAR的区别 1.CHAR的长度是固定的,而VARCHAR的长度是可以变化的, 比如,存储字符串“abc",对于CHAR (10),表示你存储的字符将占10个字节(包括7个空字符),而同样的VARCHAR (10)则只占用3个字节的长度,10只是最大值,当你存储的字符小于10时,按实际长度存储。 2.CHAR的效率比VARCHAR的效率稍高。 3.推荐用VARCHAR2代替VARCHAR。因为Oracle今后会将VARCHAR作为其他用途。VARCHAR2目前和VARCHAR是完全相同的数据类型。 二、数据表创建的基本语句: 1.如何通过SQL语句创建联合主键 CREATE TABLE tb_emp ( NAME VARCHAR(30), deptId INT(11), salary FLOAT, PRIMARY KEY(NAME,deptId) ) (注:单个主键也可以通过这种方式添加) 2.如何关联外键 CREATE TABLE tb_emp1 ( id INT(11) PRIMARY KEY, NAME VARCHAR(30) NOT NULL, deptId INT(11), CONSTRAINT fk_emp_dept1 FOREIGN KEY(deptId) REFERENCES tb_emp(id) ) (CONSTRAINT:约束条件,NOT NULL:指定非空) (注:子表的外键必须关联父表的主键,且关联字段的数据类型必须一致,不一致则出现错误错误码: 1005 Can't create table 'test.tb_emp1' (errno: 150)) 3.UNIQUE和PRIMARY KEY 一个表中可以有多个字段声明为UNIQUE,只能有一个PRIMARY KEY,UNIQUE可以空,PRIMARY KEY不能为空 4.主键的自动增长 在主键后添加 PRIMARY KEY AUTO_INCREMENT。 5.查看表的两种方式DESC和SHOW CREATE TABLE DESC 表名:查看表的基本结构, SHOW CREATE TABLE 表名:查看表的详细结构语句。 三、数据库修改语句的基本使用 1.修改表名 ALTER TABLE food RENAME TO foodtest 2.修改字段的数据类型 ALTER TABLE tb_emp MODIFY NAME VARCHAR(25)(字段数据类型原为VARCHAR(30),修改后为VARCHAR(25)) (当数据已经存储在数据库中,不要轻易修改数据类型) 3.修改字段名 ALTER TABLE tb_emp CHANGE name dept_name VARCHAR(30) (name为旧字段名,dept_name为新字段名) (可以把旧名新名设置成一致,修改字段数据类型,以此达到修改字段数据类型的效果) 4.添加字段 ALTER TABLE tb_emp ADD column1 FLOAT AFTER dept_name (FIRST:指定字段放在第一行,AFTER 字段:指定字段放在某字段后面) 5.删除字段 ALTER TABLE tb_emp DROP column1 6.修改字段的排列位置 ALTER TABLE tb_emp MODIFY dept_name VARCHAR(30) AFTER deptId (可选为FIRST,指定放在第一行,AFTER为放在某字段后) 7.删除表的外键约束 ALTER TABLE tb_emp DROP FOREIGN KEY fk_emp_dept 8.删除数据表 DROP TABLE tb_emp (如果作为父表有外键约束,需先删除外键约束才能删除父表,否则报错) 四、 创建索引 1.创建普通索引 CREATE TABLE tb_dept ( id INT(11) PRIMARY KEY, NAME VARCHAR(30), deptId INT(11), salary FLOAT, INDEX(salary) //指定名称,索引名称为dept_salary,长度为20 //INDEX dept_salary(salary(20)) ) (为salary建立索引,默认索引名称为salary) 2.创建唯一索引(与普通索引不同的是列值必须唯一) CREATE TABLE tb_dept ( id INT(11), NAME VARCHAR(30), deptId INT(11), salary FLOAT, UNIQUE INDEX UniqIdx(id) ) (创建了一个名为UniqIdx的索引) 3.创建组合索引 CREATE TABLE tb_dept ( id INT(11), NAME VARCHAR(30), deptId INT(11), salary FLOAT, INDEX MultiIdx(id,name,deptId) ) (建立组合索引,查询时遵循“最左前缀”原则,即可以使用到索引的字段组合有:(id,name,deptId)、(id,name)、id) 4.在已有的表上建立索引 方法一: //为列deptId添加索引名为dept_id,长度为30的索引 ALTER TABLE tb_dept ADD INDEX dept_id(deptId(30)) //唯一索引 ALTER TABLE tb_dept ADD INDEX dept_id(deptId(30)) 方法二: CREATE INDEX dept_id ON tb_dept(deptId(30))CREATE UNIQUE INDEX dept_id ON tb_dept(deptId(30)) 五、删除索引 方法一: ALTER TABLE tb_dept DROP INDEX dept_id 方法二: DROP INDEX dept_id ON tb_dept 六、插入数据 1.插入一条记录 方法一: INSERT INTO tb_dept(id,NAME,deptId) VALUES(1,'jack',2) 方法二: //使用这种方法字段的值必须一一对应 INSERT INTO tb_dept VALUES(1,'jack',2) 2.同时插入多条记录 INSERT INTO tb_dept(id,NAME,deptId) VALUES(1,'jack',2),(2,'tom',3),(3,'cherry',4) 3.将查询结果插入另一个表中(将从tb_dept表中查询到的数据插入到tb_dept1中) (注意:使用这种表转移的方式 要保证主键的唯一性,否则报错) INSERT INTO tb_dept1(id,NAME,deptId) SELECT id,NAME,deptId FROM tb_dept (插入数据时,如果想省略某字段,那么该字段需允许为空值或数据库建表时给出默认值,否则报错) 七、更新数据 //将id=1的字段的名字修改为bob. UPDATE tb_dept SET NAME='bob' WHERE id=1 //将id为1~3的字段的age修改为20 UPDATE tb_dept SET age=20 WHERE id BETWEEN 1 AND 3 (UPDATE和DELETE时不一定要使用WHERE指定某字段,此时删除的是整个表的数据) 八、删除数据 //删除id为1的字段 DELETE FROM tb_dept WHERE id=1 //删除id区间在2~3的字段 DELETE FROM tb_dept WHERE id BETWEEN 2 AND 3 //删除表中的所有记录 DELETE FROM tb_dept 九、查询数据 1.普通查询语句 SELECT * FROM tb_dept SELECT * FROM tb_dept WHERE salary<3000 (一般情况下,除非要使用表中的所有字段数据,否则最好不要使用通配符*) 2.带IN关键字查询语句 //IN关键字的使用,查询满足指定范围的记录 SELECT id,age FROM tb_dept WHERE age IN (23,20) //根据age进行排序,如果排序的字段为字符串,则根据字母的先后顺序排列 SELECT id,age FROM tb_dept WHERE age IN (23,20) ORDER BY age 3.BETWEEN AND的使用 SELECT id,age FROM tb_dept WHERE age BETWEEN 20 AND 30 ORDER BY age 4.LIKE字符匹配查询 //查询结果为jack、jason SELECT * FROM tb_dept WHERE NAME LIKE 'J%' //查询结果为jack SELECT * FROM tb_dept WHERE NAME LIKE 'J___' (%匹配的是多个字符,_一次只能匹配一个字符) 5.查询空值并按age的逆序排序 SELECT * FROM tb_dept WHERE age IS NOT null ORDER BY age DESC 6.AND连接查询条件 SELECT * FROM tb_dept WHERE age>26 AND id>3 7.OR连接查询条件 SELECT * FROM tb_dept WHERE id=1 OR id=7 (OR和IN的实现效果一样) 8.查询结果去掉重复值,使用DISTINCT SELECT DISTINCT age FROM tb_dept 9.对于查询结果实现多列排序 SELECT id,age FROM tb_dept ORDER BY id,age (如果第一个排序条件可以成立,那么第二个排序条件会失效) 10.ORDER BY后接DESC为逆序,默认为ASC升序 11.使用LIMIT限制查询结果的数量 //查询前4行 SELECT * FROM tb_dept LIMIT 4 //从第二行开始,查询两行(第二第三行) SELECT * FROM tb_dept LIMIT 1,2 //第二种写法,效果一样,限制查询两条记录,从第二行开始(1代表第二行) SELECT * FROM tb_dept LIMIT 2 OFFSET 1 十、分组查询 1.按age进行分组,求总数total SELECT age,COUNT(*) AS total FROM tb_dept BY age 2.按age进行分组,并显示每个年龄对应的姓名(使用GROUP_CONCAT关键字) SELECT age,GROUP_CONCAT(NAME) AS NAMES FROM tb_dept GROUP BY age 3.使用HAVING关键字过滤分组后的结果(当NAME的数量大于一个时才显示) SELECT age,GROUP_CONCAT(NAME) AS NAMES FROM tb_dept GROUP BY age HAVING COUNT(NAME)>1 (WHERE和HAVING都是用来过滤数据的,HAVING在数据分组后进行过滤,WHERE在分组前用来选择记录。 WHERE过滤的数据不在包括在分组中) 4.统计总数(使用WITH ROLLUP关键字) SELECT age,COUNT(*) AS total FROM tb_dept GROUP BY age WITH ROLLUP 5.使用两个字段进行分组(先使用第一个字段分组,再使用第二个字段进行分组) SELECT age, NAME,COUNT(*) AS total FROM tb_dept GROUP BY age,NAME 十一、使用集合函数查询 1.COUNT() //使用COUNT(*)时将会包含NULL值 SELECT COUNT(*) AS dept_num FROM tb_dept //使用COUNT(字段名)时将忽略空值 SELECT COUNT(age) AS dept_num FROM tb_dept 2.SUM()(不能计算字符串的数量) SELECT SUM(age) AS age_sum FROM tb_dept 3.AVG() SELECT AVG(age) AS age_num FROM tb_dept //与分组一起使用,计算每个分组的平均值 SELECT age,AVG(age) AS avg_age FROM tb_dept GROUP BY age 4.MAX()和MIN()(可与分组一起使用) SELECT MAX(age) AS max_age FROM tb_dept SELECT MIN(age) AS min_age FROM tb_dept 十二、连接查询 1.内连接查询(查询两个表中的属性,两个表中有相同的字段,WHERE可以用ON替代) SELECT emp_id,tb_emp.name,tb_dept.NAME FROM tb_dept INNER JOIN tb_emp WHERE tb_emp.dept_id=tb_dept.dept_id2.左外连接(查询左表所有记录和右表中与连接字段相等的记录)
1.带ANY,SOME关键字的子查询//在部门表和员工表中,查询所有的部门,包括没有员工的部门 SELECT tb_dept.NAME,tb_emp.name FROM tb_dept LEFT OUTER JOIN tb_emp ON tb_emp.dept_id=tb_dept.dept_id3.右外连接(返回右表中的所有记录和右表中连接字段相等的记录) //在部门表和员工表中,查询所有的员工,包括没有部门的员工 SELECT tb_emp.name,tb_dept.NAME FROM tb_dept RIGHT OUTER JOIN tb_emp ON tb_emp.dept_id=tb_dept.dept_id
4.复合条件查询,...AND tb_dept.dept_id IN (1,2) ORDER BY tb_dept.dept_id,可以与左、右外连接查询结合 十三、子查询
//在表一中查询一个数据,它比表二其中一个数据大(满足其中一个条件)
//tb1(1,5,13,27);tb2(6,11,14,20)
SELECT num1 FROM tb1 WHERE num1>ANY (SELECT num2 FROM tb2)
2.带ALL关键字的子查询
//在表一中查询一个数据,它比表二任意一个数据都大(满足所有一个条件)
//tb1(1,5,13,27);tb2(6,11,14,20)
SELECT num1 FROM tb1 WHERE num1>ALL (SELECT num2 FROM tb2)
3.带EXISTS关键字的子查询
//如果子查询有返回行,此时外层查询将进行查询,如果没有返回行,则不进行查询。子查询只做判断
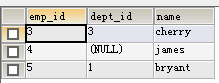
SELECT * FROM tb_dept WHERE dept_id>2 AND EXISTS (SELECT NAME FROM tb_emp WHERE emp_id=5)
4.带IN关键字的子查询
//在tb_emp表中查询emp_id,NAME,dept_id,条件是dept_id IN(返回的dept_id),用IN因为返回值可能有多个
SELECT emp_id,NAME,dept_id FROM tb_emp WHERE dept_id IN(SELECT dept_id FROM tb_dept WHERE num=20)
5.可用比较运算符>,<,=,!=代替IN,形成带比较运算符的子查询(注意,子查询的返回值需要唯一)
SELECT emp_id,NAME,dept_id FROM tb_emp WHERE dept_id !=(SELECT dept_id FROM tb_dept WHERE num=26)
十四、合并查询结果
//在tb_emp表中查询所有emp_id大于2的结果,在tb_dept表中查询所有dept_id大于2的结果,并将结果整合在一起
SELECT * FROM tb_emp WHERE emp_id>2 UNION SELECT * FROM tb_dept WHERE dept_id>2
(注:如果查询结果不会有重复行或者有重复行也没影响,则使用UNION ALL,不会删除重复行,不排序)
十五、为表取别名
1.为表取别名
//将tb_dept取别名为d,tb_emp取别名为e
SELECT e.name,d.NAME FROM tb_dept AS d RIGHT OUTER JOIN tb_emp AS e ON e.dept_id=d.dept_id AND d.dept_id IN (1,2)
十六、使用正则表达式查询
^:匹配文本的开始,
$:匹配文本的结束,
.:匹配任何单个字符
*:匹配零个或多个
+:匹配一个或多个
'字符串':匹配包含指定字符串的文本
字符串{n,}:匹配前面的字符串至少n次
字符串{n,m}:匹配前面的字符串至少n次,至多m次
//查询包含am或ry的字符串
SELECT * FROM tb_emp WHERE NAME REGEXP 'ry|am'
(注:ch+:肯定是以ch开头,ch*:以c开头,不一定有h)
//结果字符串中存在a.b
SELECT * FROM tb_emp WHERE NAME REGEXP '[^c-z1-5]'
以上为基本的增删改查语句,有错误的地方请指正!
下面是一道被坑的笔试题,其实不难,熟悉基本的语句然后结合在一起就能解决!
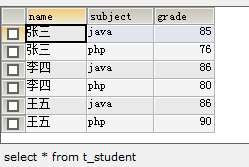
表中有三个学生,张三李四对应两个科目,王五对应三个科目。
要求查询所有科目的分数都大于80分的学生。
分析:
首先,1.要查询的学生名有重复值,所以考虑用到DISTINCT去除重复,
2.要查询所有科目分数大于80分的学生,即查询的学生中分数不能小于80,
总结为:查询学生的名字,查询的名字中,不包含有科目分数小于80的学生
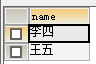
SELECT DISTINCT NAME FROM t_student WHERE NAME NOT IN(SELECT NAME FROM t_student WHERE grade<80)
结果:
陆续更新中。。。















12-15
 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









