



Text-to-SQL任务
Text-to-SQL,它涉及将自然语言问题自动转换为结构化 SQL 语句。
该领域存在的问题:
- text-to-sql任务中对最佳提示模板和设计框架没有达成共识
- 现有的基准不能充分探索llm在Text-to-SQL过程的各个子任务上的性能
本文的贡献:
- 构建了一个数据集。
- 制定了五个评估任务,评估LLM在text2sql中的性能
- 提出了针对每个任务量身定制的最佳上下文学习解决方案。
评估方法
本文构建了一个Text-to-SQL数据集:通过考虑问题复杂性、数据库大小和先决条件知识来减轻过度拟合的风险。
设计五种不同的任务:文本到 SQL、SQL 调试、SQL 优化、模式链接和 SQL 到文本
包含的评估方法:
- 将提示分成不同的部分,并在每一个可能的组合中测量LLM的性能
- 测试一系列LLM,包括含有不同大小参数的通用模型以及coding-specific模型
- 系统评估不同信息粒度对模型的影响,并确定最佳上下文学习策略,比如zero-shot,few-shot等
任务解释
P
M
(
Y
∣
P
(
Q
,
S
)
)
=
∏
i
=
1
∣
Y
∣
P
M
(
Y
i
∣
P
(
Q
,
S
)
,
Y
1
:
i
−
1
)
.
\mathbb{P}_{\mathcal{M}}(\mathcal{Y}|\mathcal{P}(\mathcal{Q}, \mathcal{S})) = \prod_{i=1}^{|\mathcal{Y}|} \mathbb{P}_{\mathcal{M}}(\mathcal{Y}_i | \mathcal{P}(\mathcal{Q}, \mathcal{S}), \mathcal{Y}_{1:i-1}).
PM(Y∣P(Q,S))=i=1∏∣Y∣PM(Yi∣P(Q,S),Y1:i−1).
在一个基于LLM的text-to-sql 任务中,LLM 用于促进自然语言问题转换为可执行 SQL 查询。
Q
\mathcal{Q}
Q是自然语言问题,
S
\mathcal{S}
S是数据库模式,
Y
\mathcal{Y}
Y是SQL的query,
∣
Y
∣
|\mathcal{Y}|
∣Y∣是query的长度,
Y
i
\mathcal{Y}_i
Yi代表query中的第i个token。这里模型预测第i个token,与GPT中预训练的方法类似。
数据库
本文构建了BigTable-0.2k数据集,它是BIRD数据集的增强和延申。
- 从BIRD数据集识别出不同难度的查询
- 编辑和修改查询中表和列的名字和过滤条件,使查询多样化
- 原数据集涉及四个或更多表的查询实例不足,因此将三表查询扩展到四个
评估
Text2SQL
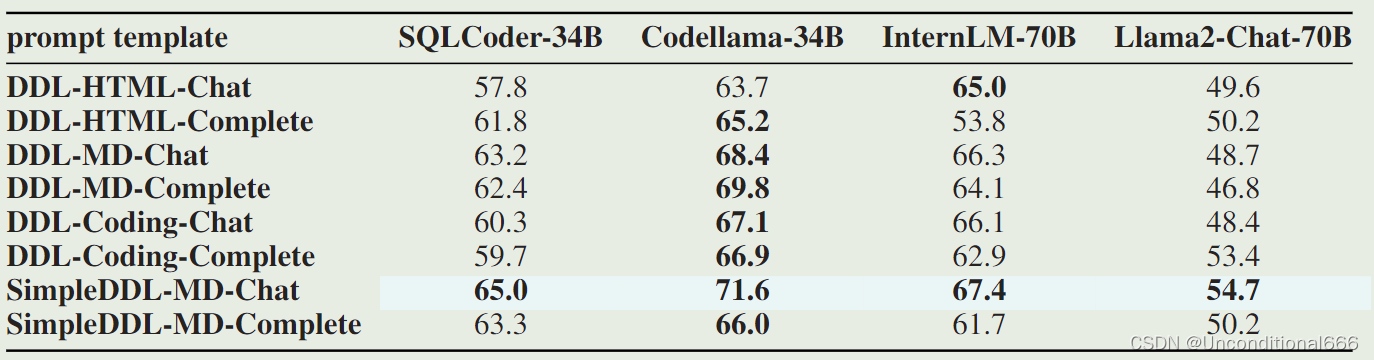
提示模板“SimpleDDL-MD-Chat”在 Text-to-SQL 任务中实现了最佳性能。
- DDL/SimpleDDL 前缀:
- DDL:提供详细的数据库结构信息,包括列类型和主/外键。
- SimpleDDL:仅提供表和列名的简化结构。
- MD/HTML/Coding 中缀:
- MD:使用 Markdown 语法包装提示模板。
- HTML:使用 HTML 片段包装提示模板。
- Coding:使用代码注释块包装提示模板。
- Complete/Chat 后缀:
- Complete:基于 “SELECT” 子句完成 SQL 语句。
- Chat:直接回答问题。
随着用户查询中涉及的表和列数量的增加,LLM 的 Text-to-SQL 挑战显着升级。

SQL debugging
生成的SQL错误分两种:语法错误,结果错误。更高级的模型表现出更大比例的结果错误。
结果错误分类:表查询错误(多余,缺少,错误),列选择错误(多余,缺少,错误),连接列错误(涉及join的错误),条件过滤错误,数据处理错误。
SQL debug策略:
- 重新生成:用相同提示重新生成。
- w\Wrong SQL:让LLM基于错误的SQL生成新的
- w\Wrong SQL+语法error info:让LLM基于错误的SQL和语法报错信息生成新的
- w\Wrong SQL +所有error info:让LLM基于错误的SQL和全部报错信息生成新的
- w/ Wrong SQL + 所有error info + Comment:让LLM基于错误的SQL和全部报错信息以及人工添加标注生成新的。
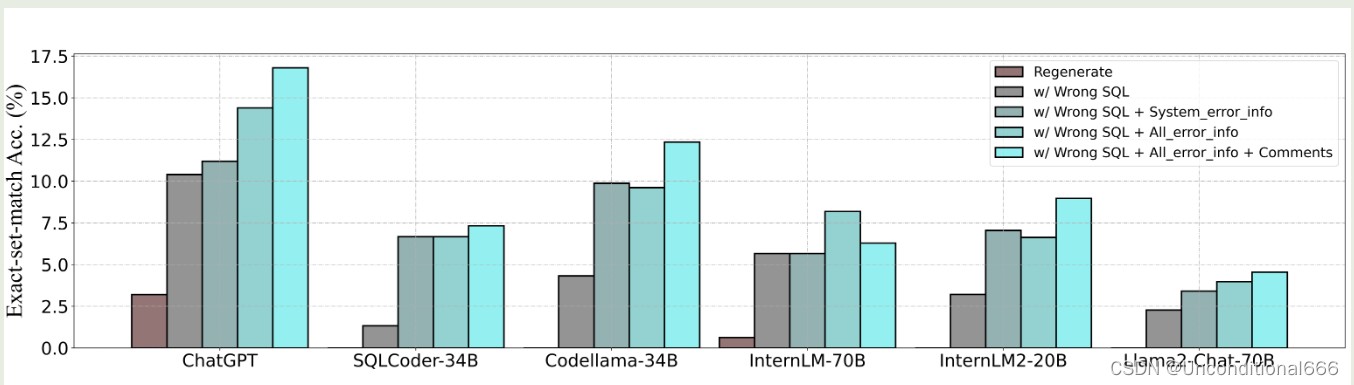
上图结果说明,详细的错误信息和相应的注释极大地增强了llm的能力,使它们能够有效地纠正错误。
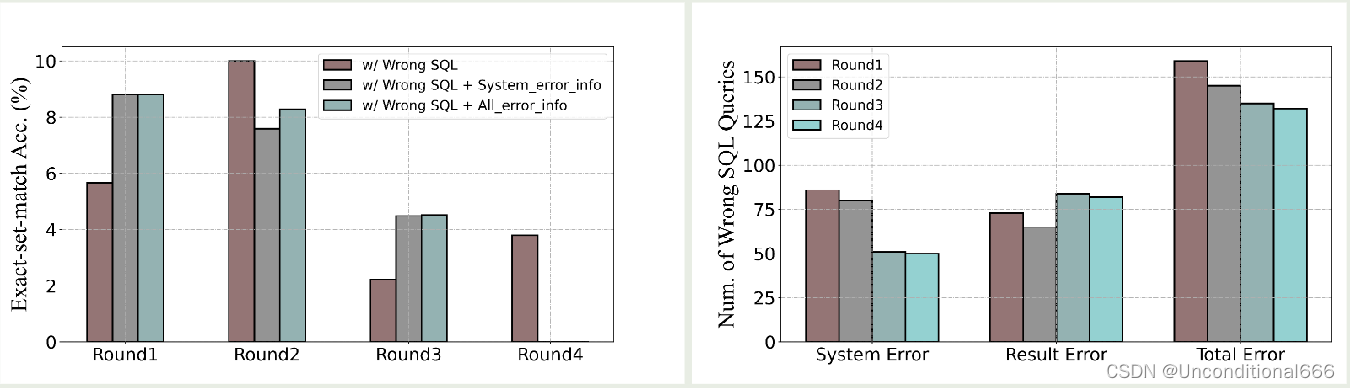
上图结果说明,多轮自调试有助于 LLM 的纠错,但存在性能边界,1-2 轮调试是最佳选择。
SQL optimization
本节探讨LLM能否优化SQL查询,模型将初始查询Y转化为优化形式,目的是保持相同结果同时优化效率。
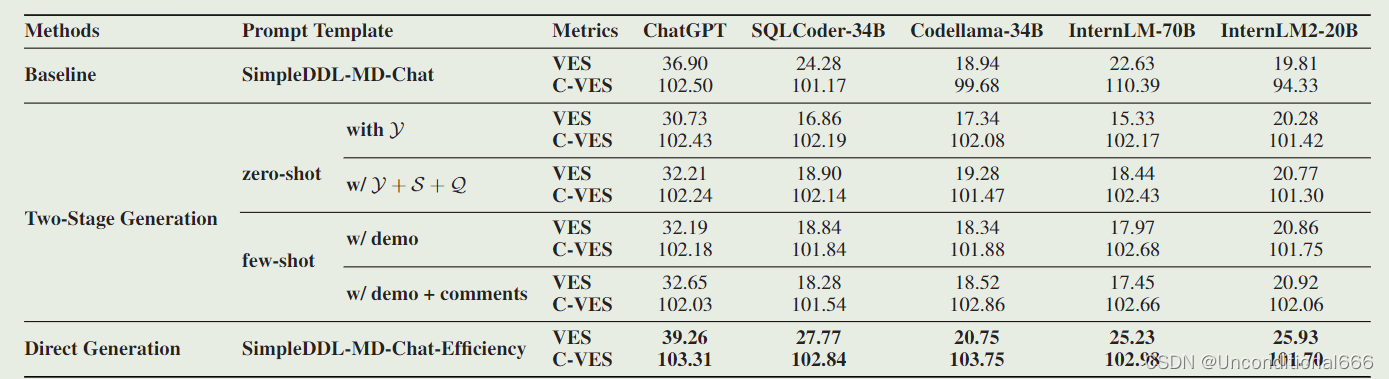
上图说明,直接指示 LLM 生成高效的 SQL 语句似乎可以提高准确性。所有两阶段的方法都经历了下降。
SQL-to-Text
将SQL转换为其原始自然语言的问题。通过将生成的 SQL 语句转换回文本并将它们与原始用户问题的语义并列,我们可以评估生成的 SQL 语句的准确性。它也可以帮助研究人员评估不同 LLM 的语义理解能力,从而促进开发更有效的 Text-to-SQL 方法。

上图说明,利用通用模型对 SQL 语句进行语义描述是更好的选择。
Schema Linking
模式链接被认为是生成正确 SQL 查询的关键先决条件。它涉及将问题中的实体引用与相应的模式表或列对齐,要求模型理解数据库的结构和值,以及用户问题的语义。
模式连接的目标是检索所有GT表但避免检索过多的表。指标为RES(Retrieval Efficiency Score)。
RES
=
∑
n
=
1
N
1
(
T
n
,
T
^
n
)
⋅
R
(
T
n
,
T
^
n
)
N
,
\text{RES} = \frac{\sum_{n=1}^{N} \mathbb{1}(T_n, \hat{T}_n) \cdot R(T_n, \hat{T}_n)}{N},
RES=N∑n=1N1(Tn,T^n)⋅R(Tn,T^n),
where
1 ( T n , T ^ n ) = { 1 , if T n ⊆ T ^ n 0 , if T n ⊈ T ^ n , \mathbb{1}(T_n, \hat{T}_n) = \begin{cases} 1, & \text{if } T_n \subseteq \hat{T}_n \\ 0, & \text{if } T_n \not\subseteq \hat{T}_n \end{cases}, 1(Tn,T^n)={1,0,if Tn⊆T^nif Tn⊆T^n,
and
R
(
T
n
,
T
^
n
)
=
∣
T
n
∣
∣
T
^
n
∣
,
R(T_n, \hat{T}_n) = \sqrt{\frac{|T_n|}{|\hat{T}_n|}},
R(Tn,T^n)=∣T^n∣∣Tn∣,
T
n
T_n
Tn和
T
^
n
\hat{T}_n
T^n是第n个例子中GT表和检索到的表。
schema linking 评估方法:
Zero Shot:让模型在没有示例的情况下从相关到不相关排序表。
Few Shot:提供少量示例,让模型检索最重要的表。
PreSQL:生成初步SQL查询,解析出表和列,用于schema链接。
Few Shot + PreSQL:结合Few Shot和PreSQL的方法结果,增强检索能力。

code-specific模型在利用 PreSQL 方法时表现出色,而通用模型通过 Few-Shot + PreSQL 方法产生最佳结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









