







 论文介绍了Structural-RNN模型,它基于时空图来捕捉人体与环境物体间的关联,用于人体运动预测。模型在mocap数据集上的实验表明,它能有效地进行短期预测,并且通过共享因子减少了参数数量,提高了泛化能力。
论文介绍了Structural-RNN模型,它基于时空图来捕捉人体与环境物体间的关联,用于人体运动预测。模型在mocap数据集上的实验表明,它能有效地进行短期预测,并且通过共享因子减少了参数数量,提高了泛化能力。
论文: Structural-RNN: Deep Learning on Spatio-Temporal Graphs
论文地址: https://arxiv.org/pdf/1511.05298.pdf
作者提出一种基于st-graph的RNN混合模型Structural-RNN(S-RNN),该模型特点是捕捉人体与周围环境中物体之间的相关性从而对人物未来的运动对预测。不用于其他模型针对mocap数据集进行学习,S-RNN还适用于对于真实环境下的数据学习,例如视频或图片。这里将重点讨论针对mocap数据集的训练以及效果。
Table of Contents(目录)
Background (论文背景)
Spatio-temporal graph
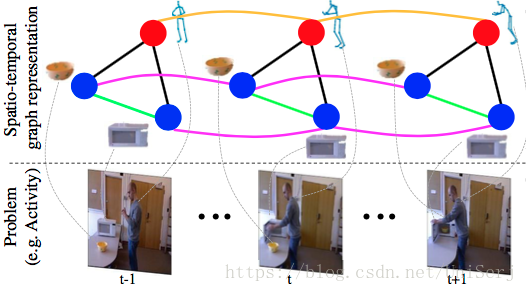
Spatio-temporal graph是S-RNN模型的基础,它是一种用于描述高层级时空关系结构的工具,图中的结点代表了问题的元素,边代表了它们之间在时间和空间上的联系。如图中人物与两个关键物体。
Factor graph parameterization
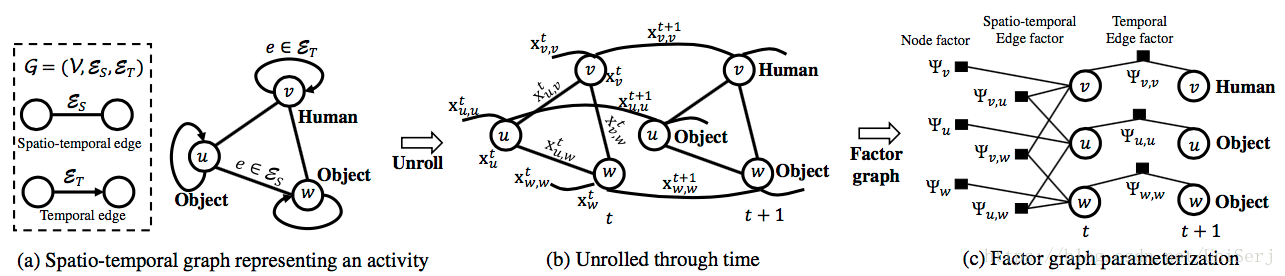
为了能将st-graph的特性实际应用在人体运动预测上,作者对其进行了一系列操作:
- 首先,如图中(a)是一个基本的st-graph代表了一个活动,由两个物体与一个人物3个结点,6条边组成。其中3条自链接的为时间相关的边,剩下为时间空间相关的边。
- 之后,将st-graph沿着时间方向,即时间相关的边横向展开,如图中(b)所示,在时间点t,3个结点之间由sp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2251
2251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









