







参考资料
运行环境
- JDK8
- Hadoop3.1.3
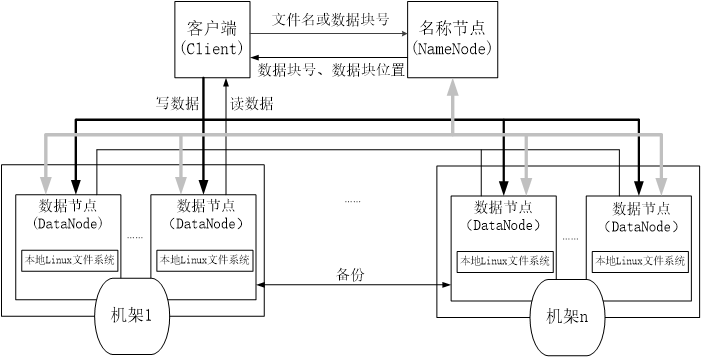
一、HDFS 体系结构
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)
所有的HDFS通信协议都是构建在TCP/IP协议基础之上的
名称节点和数据节点之间则使用数据节点协议进行交互
二、HDFS 存储原理
2.1 冗余数据保存
HDFS采用多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分不到不同的DataNode节点。优点有:
- 加快数据传输速度
- 容易检查数据错误
- 保证数据可靠性
2.2 数据存取策略
2.2.1 数据存放
第一个副本:放置在上传文件的数据节点,若是集群外提交,则随机挑选资源相对充足的节点
第二个副本:放置在与第一个副本不同的机架的节点上
第三个副本:防止在于第二个副本相同机架的其他节点上
更多副本:随机节点
2.2.2 数据读取
HDFS提供一个API可确定数据节点的机架ID,Client可以通过调用API查询。
当 Client读取HDFS数据时,从NN获得Block不同副本的存放位置列表,列表包含了副本所在的DN,然后可调用API确定Client和这些DN所属的机架ID
当发现某个Block副本的机架ID和Client对应的 机架ID相同时就优先选择该副本读取数据,若没有就随机选择一个副本。
2.3 数据错误与恢复
2.3.1 NN出错
NN存储了FsImage和EditLog信息,若损坏则根据2NN中的FsImage和Editlog数据进行恢复。
2.3.2 DN出错
- 每个
DN会定期向NN发送“心跳”信息,以汇报自身的状态 - 当
DN故障,会被标记为“宕机”,NN不会再发送I/O请求 NN会定期检查,防止出现Block的副本数小于冗余因子的情况,若发生就数据冗余复制,生成新副本。
HDFS与其他分布式文件系统最大区别就是:可调整冗余数据的位置。
2.3.3 数据出错
可能造成的原因: 网络传输问题 或 磁盘错误 等
Client读取数据后会采用 校验算法(crc、mdk5等)对文件进行校验,以确定读取到正确数据
Client 读取HDFS文件时,先读取信息文件,利用该文件对每个读取的Block进行校验
若出错,那么Client会请求到另一个DN读取该文件的Block,并且向NN报告该Block有错
NN会定期检查并重新复制这些 Block
三、HDFS 读写过程
通过HDFS Java API 的实现来理解HDFS读写流程,可参考文章 【Hadoop | HDFS 学习笔记(二)| HDFS Java API 环境搭建 | Java操作HDFS文件系统 | 多案例】
实现代码(uri为在HDFS需操作的文件路径):
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in = fs.open(new Path(uri));
FSDataOutputStream out = fs.create(new Path(uri));
首先了解这几个类的作用:
| 类名 | 描述 |
|---|---|
FileSystem |
通用文件系统的抽象基类,可被分布式文件系统集成,支持Hadoop文件系统相关操作 |
DistrubutedFileSystem |
是FileSystem在HDFS文件系统中的具体实现类 |
FSDataInputStream |
HDFS的输入流对象,用于获取HDFS文件的数据 |
FSDataOutputStream |
HDFS的输出流对象,用于将数据写入到HDFS文件 |
在3.x版本中,输入输出流对象的使用都封装到了 org.apache.hadoop.fs.FileUtil里,比如在执行CopyFromLocalFile方法时,笔者通过调试发现了底层调用的部分:
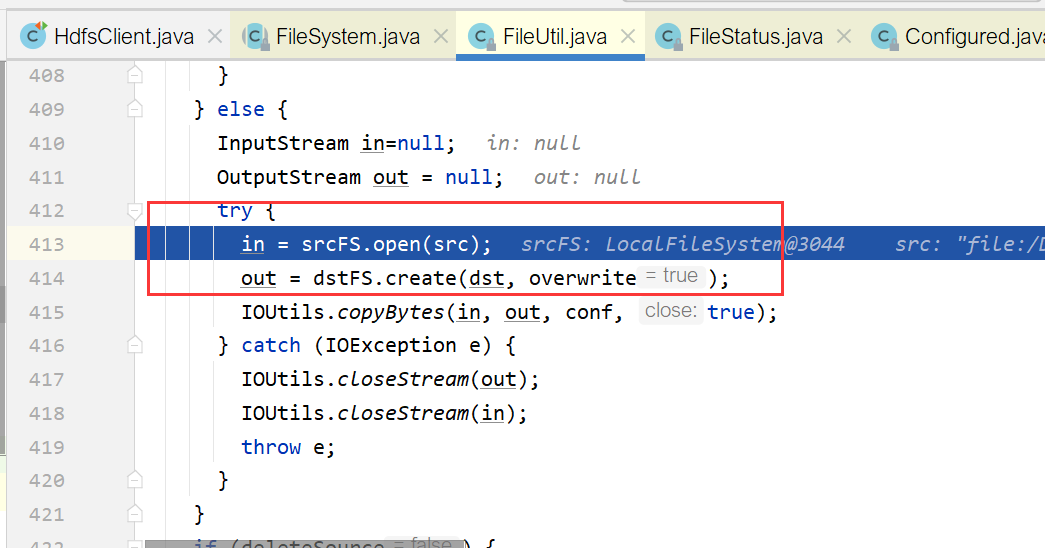
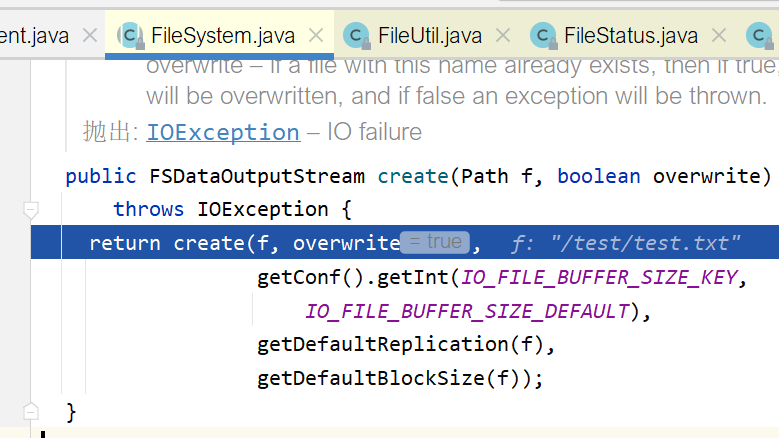
通过调试能更好的理解这个调用的流程,不过由于目前的知识面比较浅,暂时只能粗略调试。
3.1 读流程
过程与分析

主要分为4个步骤:
Client通过DistributedFileSystem向NN请求读取/下载文件,NN通过查询元数组,找到Block所在的DN地址
2.Client挑选一台DN服务器(就近原则,然后随机),请求读取数据DN开始 传输数据给Client(从磁盘读取数据输入流,以Packet为单位做校验)Client以Packet为单位接收,先在本地缓存,然后写入目标文件。
3.2 写流程
3.2.1 过程与分析
主要分为9个步骤:
Client通过DistributeFileSystem类向 NN 请求上传文件,NN检查文件是否已存在,父目录是否存在NN响应此次请求,返回是否可以上传Client向NN请求上传第一个BlockNN根据选择策略(本机架当前节点 > 其他机架节点 > 本机架其他节点 > 随机节点) ,返回3个存储文件副本的DN节点,DN1、DN2、DN3- 获取到
DN节点后,Client通过FSDataOutputStream类向DN1请求上传数据,DN1收到请求后会继续调用DN2、DN2又调用DN3,建立成一个通信管道。 DN1、DN2、DN3逐级应答客户端- 建立通信管道后,
Client开始往DN1上传 第一个Block,先从磁盘读取数据放到一个本地内存进行缓存,以Packet为单位,DN1收到后就传给DN2、DN2收到后就传给DN3,DN1每传一个Packet就会放入一个应答队列等待应答 - 当一个
Block传输完成之后,Client再次请求NN上传到下个Block的服务器,重复执行3-8部分 - 最后传输完毕,
Client将处理的信息提交给NN
3.2.2 网络拓扑-节点NN与DN之间的距离计算
在HDFS写数据过程,NN会选择距离待上传数据最近距离的DN接收,这个节点距离等于两个节点到达最近的共同祖先的距离总和。 以尚硅谷机构提供的这张图为例:
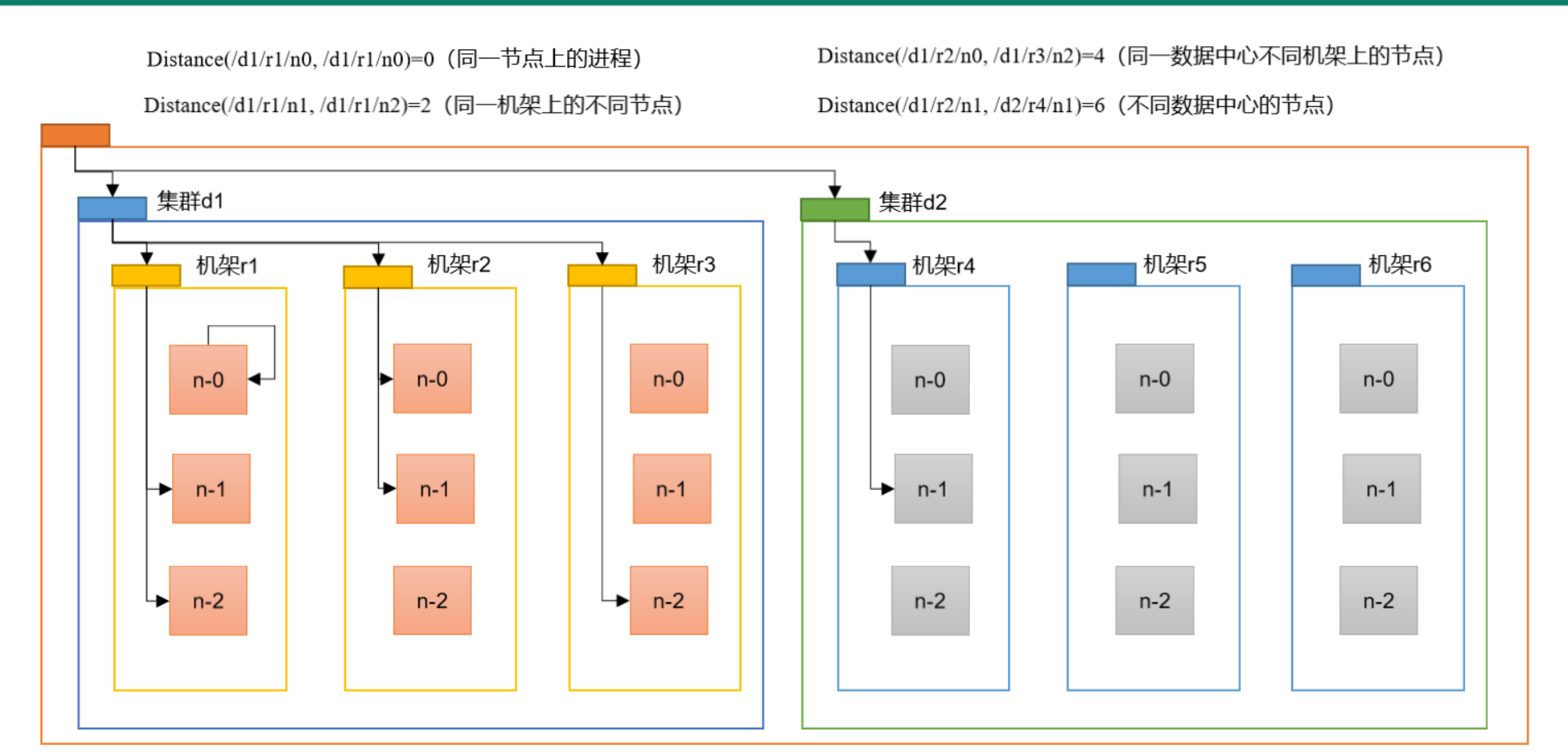
集群分为d1、d2,机架又分为r1、r2、r3、r4、r5、r6,而集群节点都称为n1、n2、n3。可以把它们看成是多叉树里的一个节点。
3.2.3 机架感知(副本存储节点选择)
首先回顾 HDFS的写流程,首先,Client向NN申请上传文件,NN检查文件用户是否有权限、然后再检查是否存在,若符合就响应Client提示允许上传,接着Client请求上传第一个Block,此时NN就需要根据一个策略来选择元数据里的DN负责存储这个副本了,在API中是在 BlockPlacementPolicyDefault类的chooseTargetInOrder方法实现的。
对应包的 Maven 依赖
<dependency>
<groupId>org.apache.hadoop</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









