







 KMP算法是模式匹配算法,模式匹配算法就是比较两个字符串是否相等的算法。eg:(以下例子都建立在下标从1开始,0位在后续用于存放数组长度)S=“abcababca”,T=“abcabx”这就是最简单的匹配做法,但效率其实很低。首先,②③的判断是多余的,根据①已知首字符“a”与第二三位字符的“b,c”均不相等然后④⑤的判断也是可省略的,因为在T中,第一二位的“a,b”分别与第四五位的“...
KMP算法是模式匹配算法,模式匹配算法就是比较两个字符串是否相等的算法。eg:(以下例子都建立在下标从1开始,0位在后续用于存放数组长度)S=“abcababca”,T=“abcabx”这就是最简单的匹配做法,但效率其实很低。首先,②③的判断是多余的,根据①已知首字符“a”与第二三位字符的“b,c”均不相等然后④⑤的判断也是可省略的,因为在T中,第一二位的“a,b”分别与第四五位的“...
KMP算法是模式匹配算法,模式匹配算法就是比较两个字符串是否相等的算法。
eg:(以下例子都建立在下标从1开始,0位在后续用于存放数组长度)
S=“abcababca”,T=“abcabx”


这就是最简单的匹配做法,但效率其实很低。
首先,②③的判断是多余的,根据①已知首字符“a”与第二三位字符的“b,c”均不相等
然后④⑤的判断也是可省略的,因为在T中,第一二位的“a,b”分别与第四五位的“a,b”相等,而在①中已经对比过,T的第四五位分别与S的第四五位相等,那么等价代换一下,T的第一二位必定与S的第四五位相等。
意思就是上述的判断中,①后,应该直接到⑥才是合理的,其他的步骤都是可以省略的。
KMP算法就是为了省略没必要的回溯,因此KMP算法中,主串S是不会进行回溯的,比如例子中①完成后,i=6,i就不会减少了只会增加了,就是好马不吃回头草
那么主串不回溯,那变化的自然就是T串的 j 值了,根据上面的分析,我们也可以看出,j值的变化其实与主串没什么关系,而取决于T串中是否有重复,更具体的说,就是当前字符之前的串的前后缀的相似度。就比如例子中,T串的abcabx中,ab是重复的,前缀的ab,与“x”前的后缀ab是相等的,所以在第六位“x”不匹配时,j从6变成了3
定义一个为数组next,next[j]表示在第j位匹配失败后,下一个检查匹配的位置,这也是KMP算法的核心,公式为:
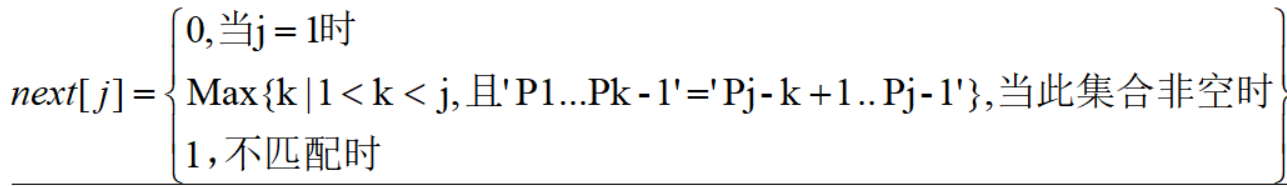
为什么是k-1而不是k?
假设是k,即 ‘P1…Pk‘=’Pj-k-1…Pj-1’,而 1<k<j,则 j-k-1>=0,不符合从1 开始的要求,而原公式中,j-k+1>=1 才符合要求
从公式如何得出算法?
相信很多读者第一反应就是外层一个关于 j 的循环,内层一个关于k的循环。
而实际算法却是:
/* 通过计算返回子串T的next数组。 */
void get_next(String T, int *next)
{
int i,j;
i=1;
j=0;
next[1]=0;
while (i<T[0])  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2525
2525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









