







NLTK
Introduction
NLTK,全称Natural Language Toolkit,自然语言处理工具包,是NLP研究领域常用的一个Python库,由宾夕法尼亚大学的Steven Bird和Edward Loper在Python的基础上开发的一个模块,至今已有超过十万行的代码。这是一个开源项目,包含数据集、Python模块、教程等。
NLTK官方文档:http://www.nltk.org/
Installation
使用pip进行安装
pip install nltk
测试安装是否成功
import nltk
若没有报错,则说明安装成功。
接下来,需要为NLTK安装一些组件。 打开 python,然后键入:
import nltk
nltk.download()
输入后会弹出一个GUI,选择我们需要下载的内容。建议是如果硬盘容量足够的话,点选all下载所有内容。
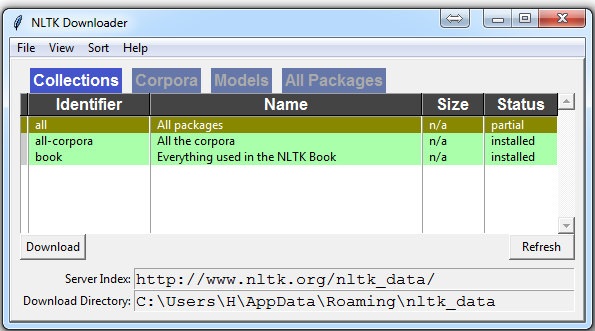
为所有软件包选择下载“全部”,然后单击“下载”。 这会给你所有分词器,分块器,其他算法和所有的语料库。 NLTK 模块将占用大约 7MB,整个nltk_data目录将占用大约 1.8GB,其中包括分块器,解析器和语料库。
如果下载能够顺利的话,则等待所有数据包缓存结束之后,环境就搭建完成了。
简单样例
-
分词以及词性标注
import nltk sentence = "A high level Israeli army official has said today Saturday that Israel believes Iran is set to begin acquiring nuclear capability for military purposes from 2005." tokens = nltk.tokenize.word_tokenize(sentence) # 分词 print("tokens: ", tokens) tagged = nltk.pos_tag(tokens) # 词性标注 print("tagged: ", tagged[:6])输出
tokens: ['A', 'high', 'level', 'Israeli', 'army', 'official', 'has', 'said', 'today', 'Saturday', 'that', 'Israel', 'believes', 'Iran', 'is', 'set', 'to', 'begin', 'acquiring', 'nuclear', 'capability', 'for', 'military', 'purposes', 'from', '2005', '.'] tagged: [('A', 'DT'), ('high', 'JJ'), ('level', 'NN'), ('Israeli', 'NNP'), ('army', 'NN'), ('official', 'NN')] -
nltk中的wordnet
from nltk.corpus import wordnet # 利用nltk中的wordnet来获取同义词 synonyms = [] for syn in wordnet.synsets("computer"): for lemma in syn.lemmas(): synonyms.append(lemma.name()) print(synonyms)输出
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
nltk.download()报错解决方案
-
大多数时候,整个下载速度是非常慢的,而且下载过程中可能因为过慢而导致下载中止。此时,可以采取其它的办法来配置相应数据包。
下载链接 https://github.com/nltk/nltk_data
目前有一些已经下载好的nltk_data文件。下载上面链接中的文件,将packages里的内容复制到上述GUI里的默认下载路径(Download Directory)即可。
-
遇到punkt包加载错误:
将punkt文件夹保存到Searched in下给出的任一搜索路径下的nltk_data/文件夹下即可。
punkt文件也在本仓库内给出,可以直接下载。
代码演示
import nltk
from nltk.corpus import wordnet
sentence = "A high level Israeli army official has said today Saturday that Israel believes Iran is set to begin " \
"acquiring nuclear capability for military purposes from 2005."
tokens = nltk.tokenize.word_tokenize(sentence)
print("tokens: ", tokens)
tagged = nltk.pos_tag(tokens)
print("tagged: ", tagged[:6])
synonyms = []
for syn in wordnet.synsets("computer"):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)
Reference
更多资料可以参考官方文档,或其它资源链接:
官网文档:http://www.nltk.org/
Python自然语言处理工具NLTK学习导引及相关资料: https://www.52nlp.cn/tag/nltk%E4%BB%8B%E7%BB%8D
https://textminingonline.com/dive-into-nltk-part-i-getting-started-with-nltk



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











