






只调用pandas和numpy,不调用其他库
本文为博主原创文章,转载请注明出处
Apriori算法:
1.频繁项集:频繁项集是在数据集中出现次数大于或等于最小支持度(Minimum Support Threshold)的项的集合。注意最小支持度这个阈值的选取往往是依据经验,并未有明确的算法。
例子: 在超市购物数据中,如果“牛奶”和“面包”这一组合经常一起出现在同一个购物篮里,并且出现的次数超过了最小支持度,那么{"牛奶", "面包"}就是一个频繁项集。
2.支持度(Support):是某个项集在所有交易中出现的频率。它用于衡量一个项集的普遍性。
例子: 如果我们有100笔交易,其中有30笔交易包含了“牛奶”,那么“牛奶”的支持度就是30%。
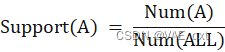
3.置信度(Confidence): 是在A出现的情况下,B出现的条件概率。
例子: 如果在包含“牛奶”的所有交易中,有70%的交易也包含了“面包”,那么从“牛奶”到“面包”的置信度就是70%。
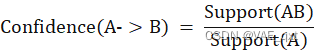
4. 提升度(Lift):提升度用于衡量项集X和Y的出现是否相互独立。如果提升度等于1,表示两个项集是独立的;大于1表示是有正相关性;小于1表示有负相关性。
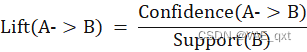
文章基于网页浏览数据关联性分析这个项目所著
数据如下
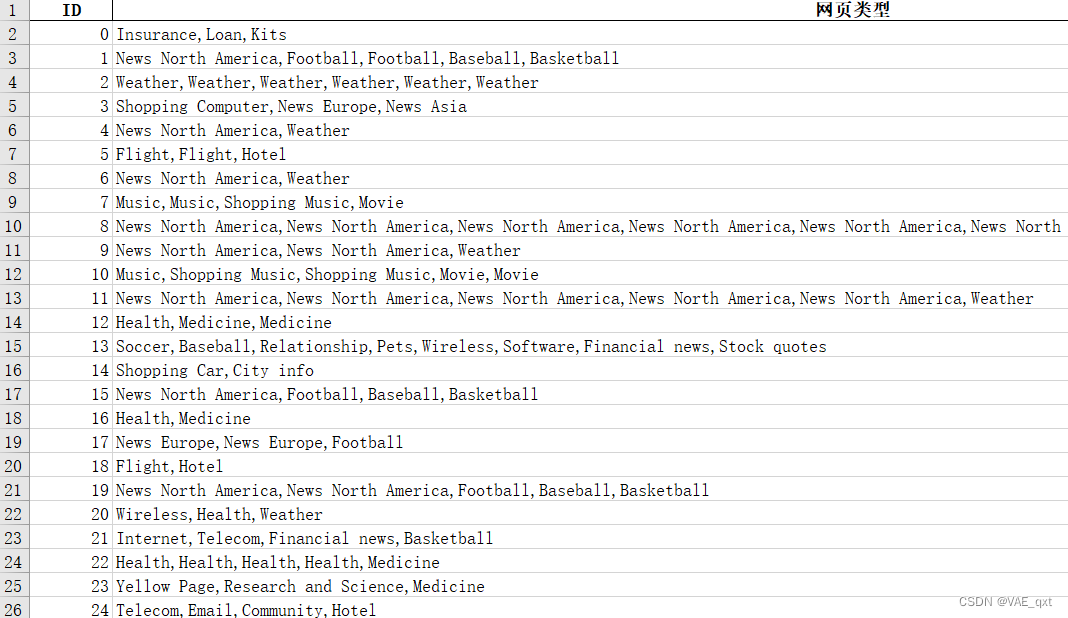
webData.xlsx
data = pd.read_excel('webData.xlsx')
# 候选集
doubleList = []
C1 = []
for i in range(len(data)):
webData = data.iloc[i, 1]
webList = webData.split(",")
deRepetition = []
for l1 in webList: # 这个是每个id浏览的网页去重
if l1 not in deRepetition:
deRepetition.append(l1)
for j in range(len(deRepetition)): # 寻找二项集
for k in range(j+1, len(deRepetition)):
double = [deRepetition[j], deRepetition[k]]
doubleList.append(double)
for web in deRepetition:
C1.append(web)代码解读: 由于一组数据包含多个网页类型,且网页类型有重复,所以先用deRepetion这个列表进行去重。将去重后的网页类型保存到候选集列表C1。然后就是寻找二项集,两层循环遍历去重列表deRepetion寻找二项集。注意!二项集是有次序的!
# 统计网页频数
webCounts = {}
for itemWeb in C1:
if itemWeb not in webCounts:
webCounts[itemWeb] = 1
else:
webCounts[itemWeb] += 1
# 统计每个网页的支持度
web_minSupport = {}
for key, value in webCounts.items():
minSupport = value/len(data)
web_minSupport[key] = minSupport代码解读:在这先遍历候选集C1.统计每种网页类型出现的频率,将数据保存到字典webCounts。
再遍历字典webCounts,求出每个网页类型的支持度。注意!支持度A:A出现的次数 ÷ 总记录条数,所以是minSupport = value/len(data)。
# 统计二项集频数
frequentSet = {}
for itemDouble in doubleList:
itemDouble_tuple = tuple(itemDouble)
print(itemDouble_tuple)
if itemDouble_tuple not in frequentSet:
frequentSet[itemDouble_tuple] = 1
else:
frequentSet[itemDouble_tuple] += 1
# 计算二项集支持度
doubleSupport = {}
for key, value in frequentSet.items():
support = value/len(data)
doubleSupport[key] = support
解读:与上文类似,先统计频数,再计算支持度。
dataframe = pd.DataFrame(list(web_minSupport.items()),columns=['网页', '支持度'])
dataframe.to_excel('网页的支持度.xlsx',index=False)
df = pd.DataFrame(list(doubleSupport.items()),columns=['二项集','支持度'])
df['二项集'] = df['二项集'].astype(str)
df['二项集'] = df['二项集'].str.replace('(','').str.replace(')','').str.replace("'",'')
df.to_excel('二项集的支持度.xlsx',index=False)
保存数据
| 网页 | 支持度 |
| Insurance | 0.0565 |
| Loan | 0.056 |
| Kits | 0.0225 |
| News North America | 0.2085 |
| Football | 0.132 |
| Baseball | 0.1055 |
| Basketball | 0.1065 |
| Weather | 0.1985 |
| Shopping Computer | 0.0685 |
| News Europe | 0.0595 |
| News Asia | 0.0285 |
| Flight | 0.1275 |
| Hotel | 0.1225 |
| 二项集 | 支持度 |
| News North America, Weather | 0.115 |
| Flight, Hotel | 0.1045 |
| Shopping Music, Movie | 0.086 |
| Baseball, Basketball | 0.085 |
| Music, Shopping Music | 0.083 |
| Music, Movie | 0.077 |
| Football, Baseball | 0.0755 |
| Football, Basketball | 0.0745 |
| News North America, Football | 0.0735 |
| News North America, Baseball | 0.0735 |
| News North America, Basketball | 0.0735 |
| Health, Medicine | 0.061 |
webSupport = pd.read_excel('网页的支持度.xlsx')
frequentSupport = pd.read_excel('频繁项集支持度.xlsx')
"""
置信度: <顾客买了A,同时又买了B> -> confidence(A->B) = P(AB)/P(A) or
AB同时出现的次数/A出现的次数
"""
frequentData = frequentSupport.copy()
frequentData['置信度'] = np.nan
for i in range(len(frequentSupport)):
webList = frequentSupport.iloc[i, 0]
web = webList.split(",")[0]
print(web)
support = webSupport.loc[webSupport['网页'] == web, '支持度']
support = float(support)
print("网页支持度:", support)
doubleSupport = frequentSupport.iloc[i, 1]
confidence = doubleSupport/support
print('置信度为:', confidence)
frequentData.at[i, "置信度"] = confidence解读:
confidence(A->B) = support(AB)/support(A)
为了求A->B的置信度,我们需要得知AB的支持度和A的支持度
先遍历表格frequentSupport。由于数据是二项集如:Health, Medicine,所以用iloc提取数据,再用“,”拆分,并选取第一个数据Health。根据Health在webSupport中查询对应网页类型的支持度support。使用frequentSupport.iloc[i, 1]提取Health, Medicine这个二项集的支持度doubleSupport。confidence = doubleSupport/support。
frequentData = pd.read_excel('频繁二项集数据.xlsx')
webSupport = pd.read_excel('网页的支持度.xlsx')
"""
提升度: lift(A -> B)= confidence(A->B)/support(B)
"""
frequentData['提升度'] = np.nan
for i in range(len(frequentData)):
webList = frequentData.iloc[i, 0]
web = webList.split(",")[1].strip()
print(web)
support = webSupport.loc[webSupport['网页'] == web, "支持度"]
support = float(support)
confidence = frequentData.iloc[i, 2]
lift = confidence/support
print("提升度",lift)
frequentData.at[i, "提升度"] = lift提升度的求取与上文相同

















 3421
3421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









