






二叉树的迭代遍历
递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
因此我们也可以用栈来实现二叉树的前中后序遍历
前序遍历
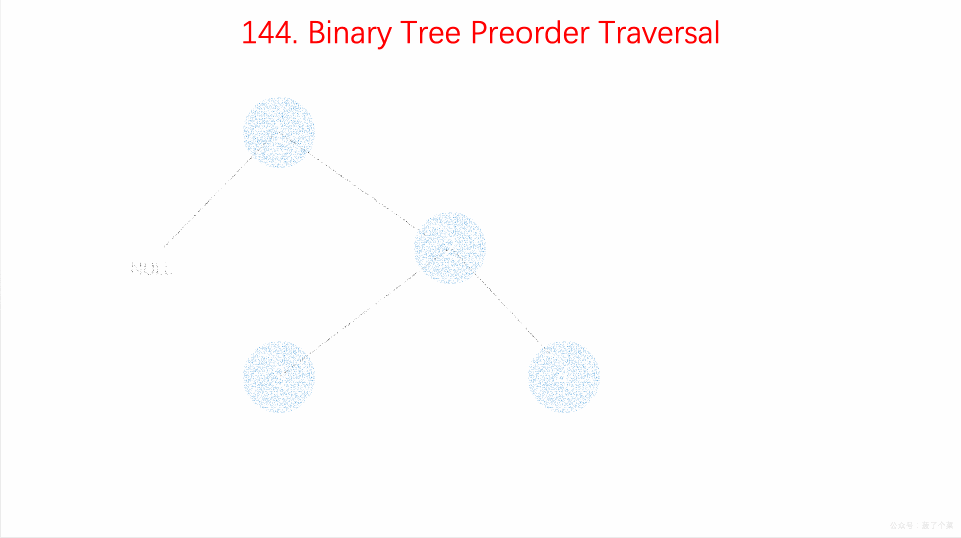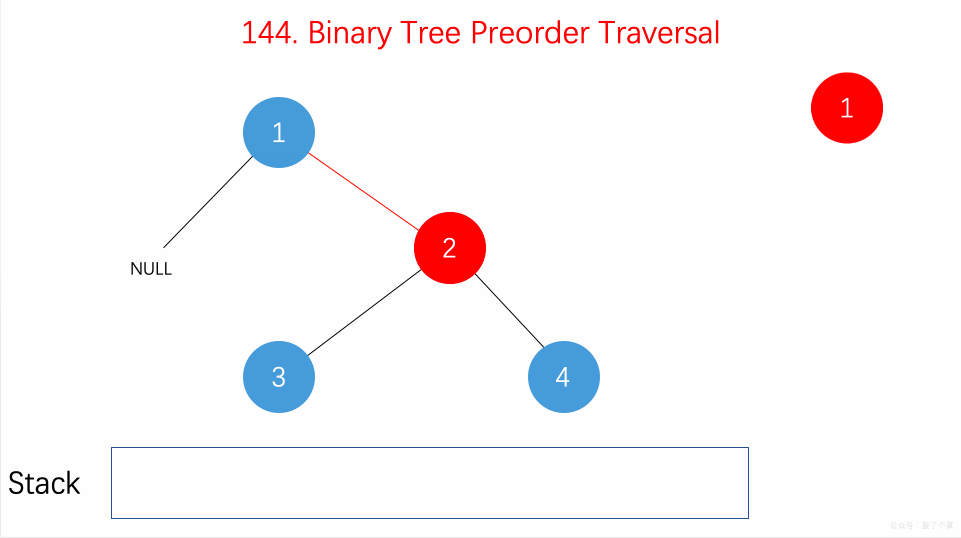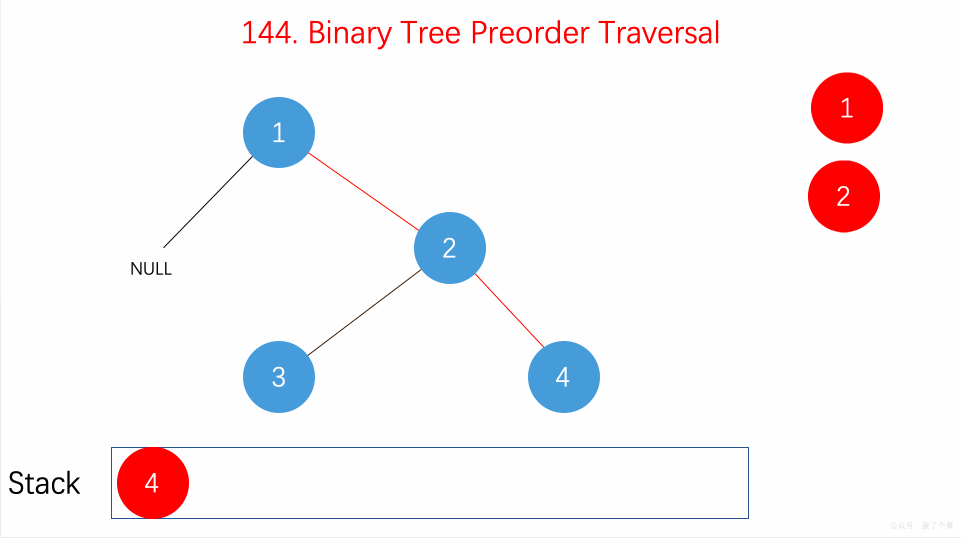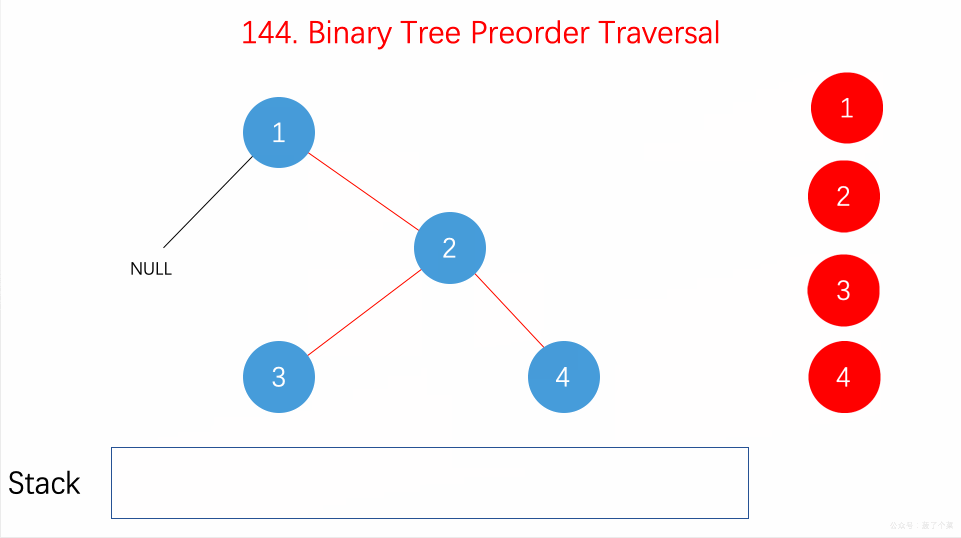
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
动画如下:
不难写出如下代码: (注意代码中空节点不入栈)
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> stk;
vector<int> result;
if (root == NULL) return result;
stk.push(root);
while (!stk.empty()) {
TreeNode* node = stk.top(); // 中
stk.pop();
result.push_back(node->val);
if (node->right) stk.push(node->right); // 右(空节点不入栈)
if (node->left) stk.push(node->left); // 左(空节点不入栈)
}
return result;
}
};
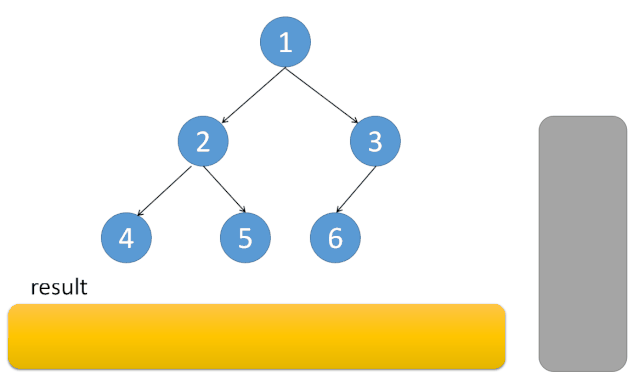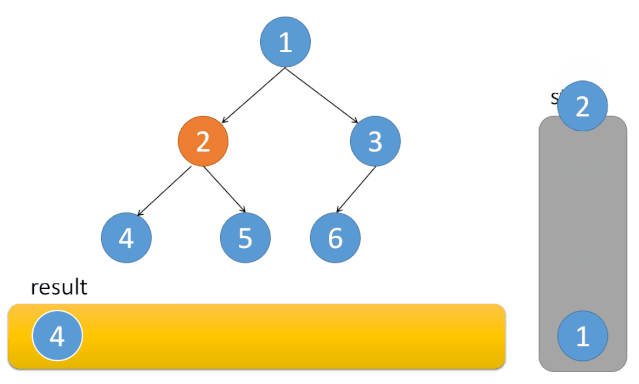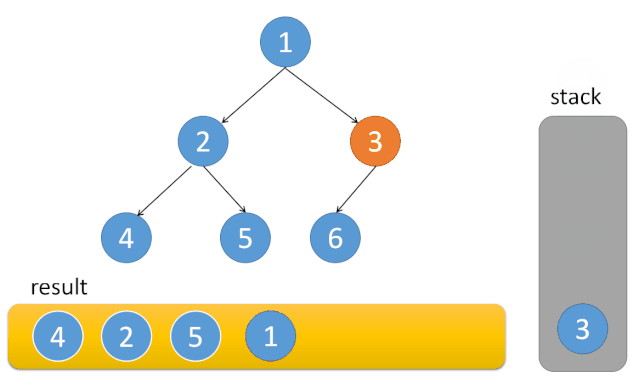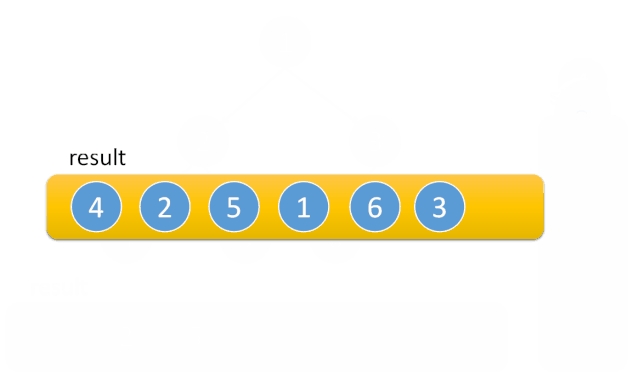
中序遍历
每到一个节点 A,因为根的访问在中间,将 A 入栈。然后遍历左子树,接着访问 A,最后遍历右子树。在访问完 A 后,A 就可以出栈了。因为 A 和其左子树都已经访问完成。
代码实现:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top(); // 从栈里弹出的数据,就是要处理的数据(放进result数组里的数据)
st.pop();
result.push_back(cur->val); // 中
cur = cur->right; // 右
}
}
return result;
}
};
分析一下迭代的前序遍历的代码不能和中序遍历通用呢,因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
后序遍历
每到一个节点 A,就应该立即访问它。 然后将左子树压入栈,再次遍历右子树。遍历完整棵树后,结果序列逆序即可。

根据前序遍历,我们只需要将result反转就好了,代码如下:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
if (node->right) st.push(node->right); // 空节点不入栈
}
reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
return result;
}
};
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









