







写在最前面:
鉴于本博主目前技术水平,我把现在的cpu处理器架构分为两种
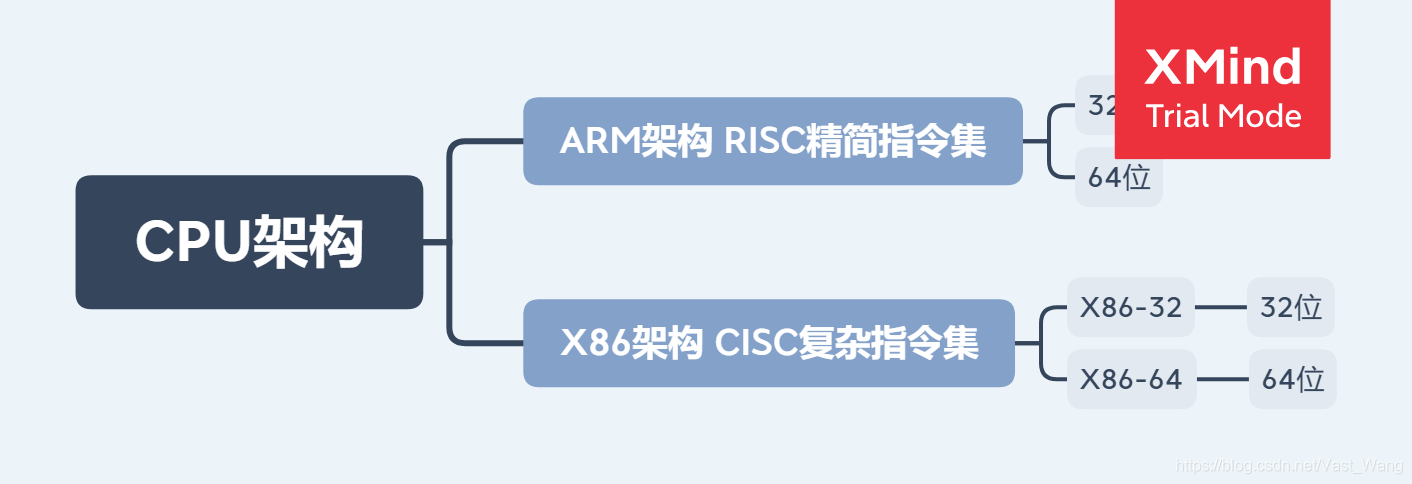
请先查看计组概述第一章:
https://blog.csdn.net/Vast_Wang/article/details/108893893
============================================
X86的由来:
CPU 和内存传输数据,靠的都是总线。
其实总线上主要有两类数据,一个是地址数据,也就是我想拿内存中哪个位置的数据,这类总线叫地址总线(Address Bus);
另一类是真正的数据,这类总线叫数据总线(Data Bus)。
所以说,总线其实有点像连接 CPU 和内存这两个设备的高速公路,说总线到底是多少位,就类似说高速公路有几个车道。
但是这两种总线的位数意义是不同的。
地址总线的位数,决定了能访问的地址范围到底有多广。
例如只有两位,那 CPU 就只能认 00,01,10,11 四个位置,超过四个位置,就区分不出来了。位数越多,能够访问的位置就越多,能管理的内存的范围也就越广。
而数据总线的位数,决定了一次能拿多少个数据进来。例如只有两位,那 CPU 一次只能从内存拿两位数。要想拿八位,就要拿四次。位数越多,一次拿的数据就越多,访问速度也就越快
x86 成为开放平台历史中的重要一笔
那 CPU 中总线的位数有没有个标准呢?如果没有标准,那操作系统作为软件就很难办了,因为软件层没办法实现通用的运算逻辑。这就像很多非标准的元器件一样,你烧你的电路板,我烧我的电路板,谁都不能用彼此的。
早期的 IBM 凭借大型机技术成为计算机市场的领头羊,直到后来个人计算机兴起,苹果公司诞生。但是,那个时候,无论是大型机还是个人计算机,每家的 CPU 架构都不一样。如果一直是这样,个人电脑、平板电脑、手机等等,都没办法形成统一的体系,就不会有我们现在通用的计算机了,更别提什么云计算、大数据这些统一的大平台了。
好在历史将 x86 平台推到了开放、统一、兼容的位置。我们继续来看 IBM 和 x86 的故事。IBM 开始做 IBM PC 时,一开始并没有让最牛的华生实验室去研发,而是交给另一个团队。
一年时间,软硬件全部自研根本不可能完成,于是他们采用了英特尔的 8088 芯片作为 CPU,使用微软的 MS-DOS 做操作系统。
谁能想到 IBM PC 卖得超级好,好到因为垄断市场而被起诉。
IBM 就在被逼的情况下公开了一些技术,使得后来无数 IBM-PC 兼容机公司的出现,也就有了后来占据市场的惠普、康柏、戴尔等等。
能够开放自己的技术是一件了不起的事。从技术和发展的层面来讲,它会使得一项技术大面积铺开,形成行业标准。就比如现在常用的 Android 手机,如果没有开放的 Android 系统,我们也没办法享受到这么多不同类型的手机。
对于当年的 PC 机来说,其实也是这样。英特尔的技术因此成为了行业的开放事实标准。由于这个系列开端于 8086,因此称为 x86 架构。
后来英特尔的 CPU 数据总线和地址总线越来越宽,处理能力越来越强。
但是一直不能忘记三点,一是标准,二是开放,三是兼容。因为要想如此大的一个软硬件生态都基于这个架构,符合它的标准,如果是封闭或者不兼容的,那谁都不答应。

第一个8086架构的总线位数为16
80386开始就是32位了,而且持续了很长时间。直到64位的出现
而64位的机器叫x64 其实叫x86-64!!! 也属于x86架构的
------------------------------------------------------------------------------------
从 8086 的原理说起
说完了 x86 的历史,我们再来看 x86 中最经典的一款处理器,8086 处理器。
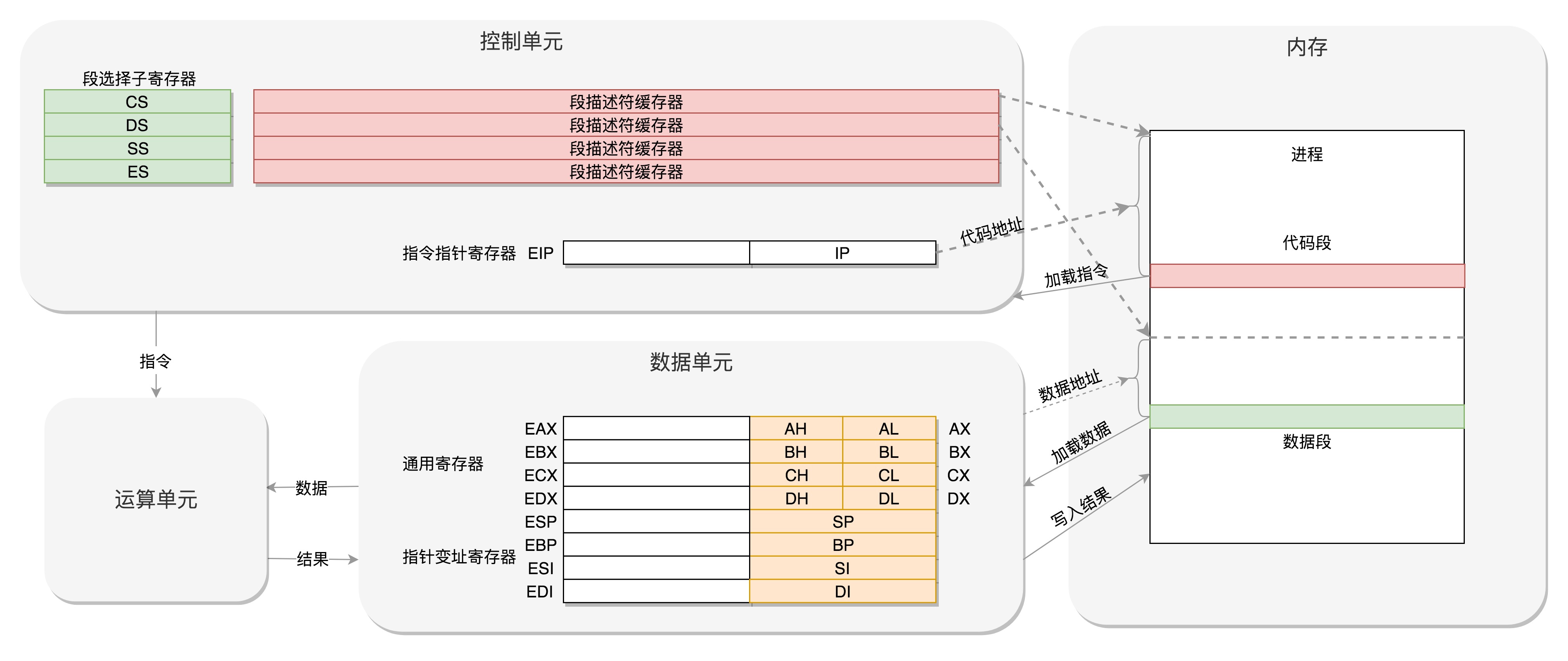
虽然它已经很老了,但是咱们现在操作系统中的很多特性都和它有关,并且一直保持兼容。我们把 CPU 里面的组件放大之后来看。你可以看我画的这幅图。
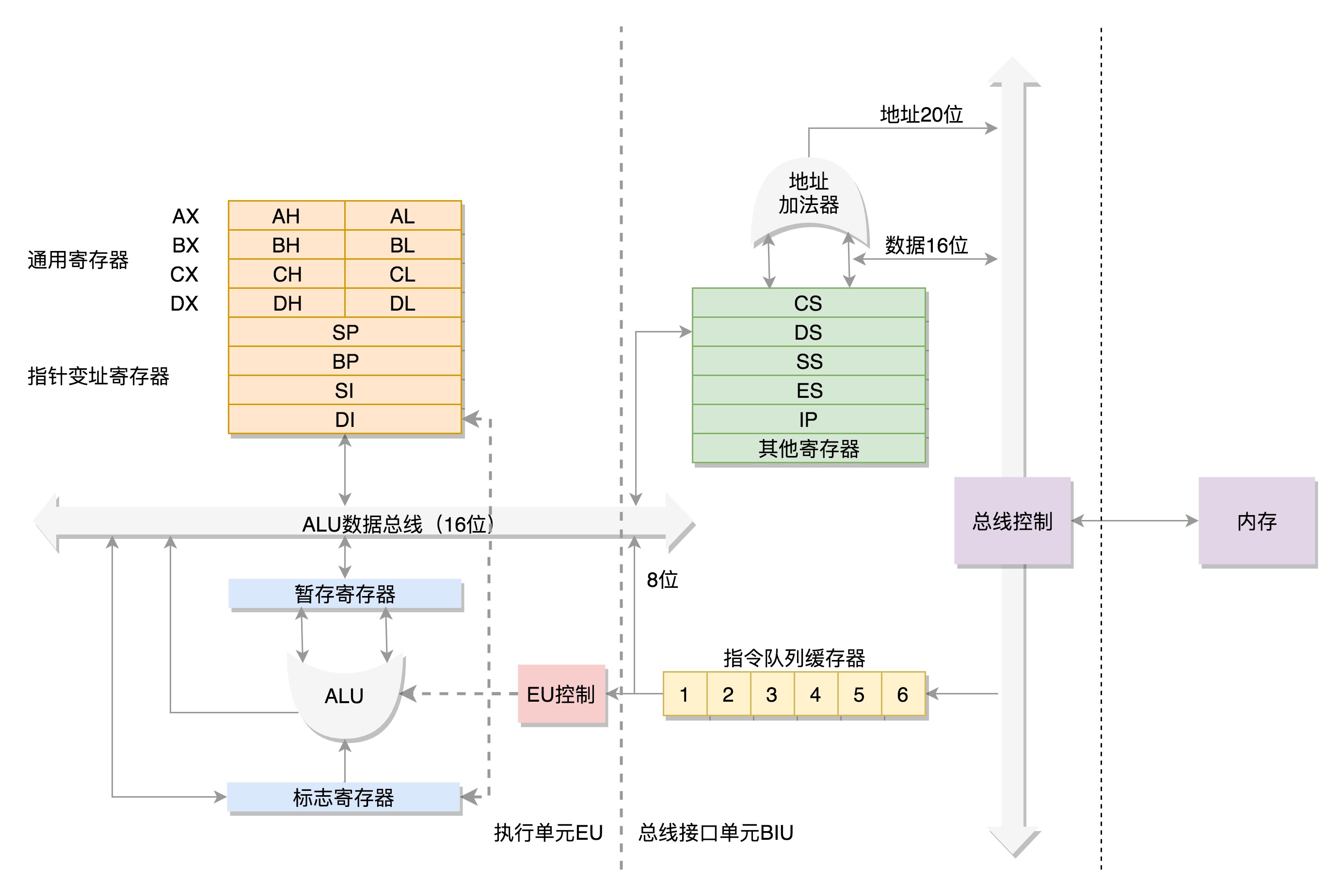
我们先来看数据单元。
为了暂存数据,8086 处理器内部有 8 个 16 位的通用寄存器,也就是刚才说的 CPU 内部的数据单元,分别是 AX、BX、CX、DX、SP、BP、SI、DI。
这些寄存器主要用于在计算过程中暂存数据。这些寄存器比较灵活,其中 AX、BX、CX、DX 可以分成两个 8 位的寄存器来使用,分别是 AH、AL、BH、BL、CH、CL、DH、DL,其中 H 就是 High(高位),L 就是 Low(低位)的意思。
这样,比较长的数据也能暂存,比较短的数据也能暂存。你可能会说 16 位并不长啊,你可别忘了,那是在计算机刚刚起步的时代。
接着我们来看控制单元。
IP 寄存器就是指令指针寄存器(Instruction Pointer Register),指向代码段中下一条指令的位置。
CPU 会根据它来不断地将指令从内存的代码段中,加载到 CPU 的指令队列中,然后交给运算单元去执行。
如果需要切换进程呢?每个进程都分代码段和数据段,为了指向不同进程的地址空间,有四个 16 位的段寄存器,分别是 CS、DS、SS、ES。
其中,CS 就是代码段寄存器(Code Segment Register),通过它可以找到代码在内存中的位置;
DS 是数据段的寄存器,通过它可以找到数据在内存中的位置。
SS 是栈寄存器(Stack Register)。
栈是程序运行中一个特殊的数据结构,数据的存取只能从一端进行,秉承后进先出的原则,push 就是入栈,pop 就是出栈。
在 CS 和 DS 中都存放着一个段的起始地址。
代码段的偏移量在 IP 寄存器中,数据段的偏移量会放在通用寄存器中。
这时候问题来了,CS 和 DS 都是 16 位的,也就是说,起始地址都是 16 位的,IP 寄存器和通用寄存器都是 16 位的,偏移量也是 16 位的,但是 8086 的地址总线地址是 20 位。
怎么凑够这 20 位呢?方法就是“起始地址 *16+ 偏移量”,也就是把 CS 和 DS 中的值左移 4 位,变成 20 位的,加上 16 位的偏移量,这样就可以得到最终 20 位的数据地址。
================================
2^4=16, 起始地址 * 16 相当于左移4位 =
================================
从这个计算方式可以算出,无论真正的内存多么大,对于只有 20 位地址总线的 8086 来讲,能够区分出的地址也就 2^20=1M,超过这个空间就访问不到了。
这又是为啥呢?如果你想访问 1M+X 的地方,这个位置已经超过 20 位了,由于地址总线只有 20 位,在总线上超过 20 位的部分根本是发不出去的,所以发出去的还是 X,最后还是会访问 1M 内的 X 的位置。
那一个段最大能有多大呢?因为偏移量只能是 16 位的,所以一个段最大的大小是 2^16=64k
是不是好可怜?对于 8086CPU,最多只能访问 1M 的内存空间,还要分成多个段,每个段最多 64K。尽管我们现在看来这不可想象的小,根本没法儿用,但是在当时其实够用了。
=======================================
再来说 32 位处理器
当然,后来计算机的发展日新月异,内存越来越大,总线也越来越宽。
在 32 位处理器中,有 32 根地址总线,可以访问 2^32=4G 的内存。
使用原来的模式肯定不行了,但是又不能完全抛弃原来的模式,因为这个架构是开放的。
“开放”,意味着有大量其他公司的软硬件是基于这个架构来实现的,不能为所欲为,想怎么改怎么改,一定要和原来的架构兼容,而且要一直兼容,这样大家才愿意跟着你这个开放平台一直玩下去。如果你朝令夕改,那其他厂商就惨了。如果是不开放的架构,那就没有问题。硬件、操作系统,甚至上面的软件都是自己搞的,你想怎么改就可以怎么改。
我们下面来说说,在开放架构的基础上,如何保持兼容呢?
首先,通用寄存器有扩展,可以将 8 个 16 位的扩展到 8 个 32 位的,但是依然可以保留 16 位的和 8 位的使用方式。
其中,指向下一条指令的指令指针寄存器 IP,就会扩展成 32 位的,同样也兼容 16 位的。
如下图所示:
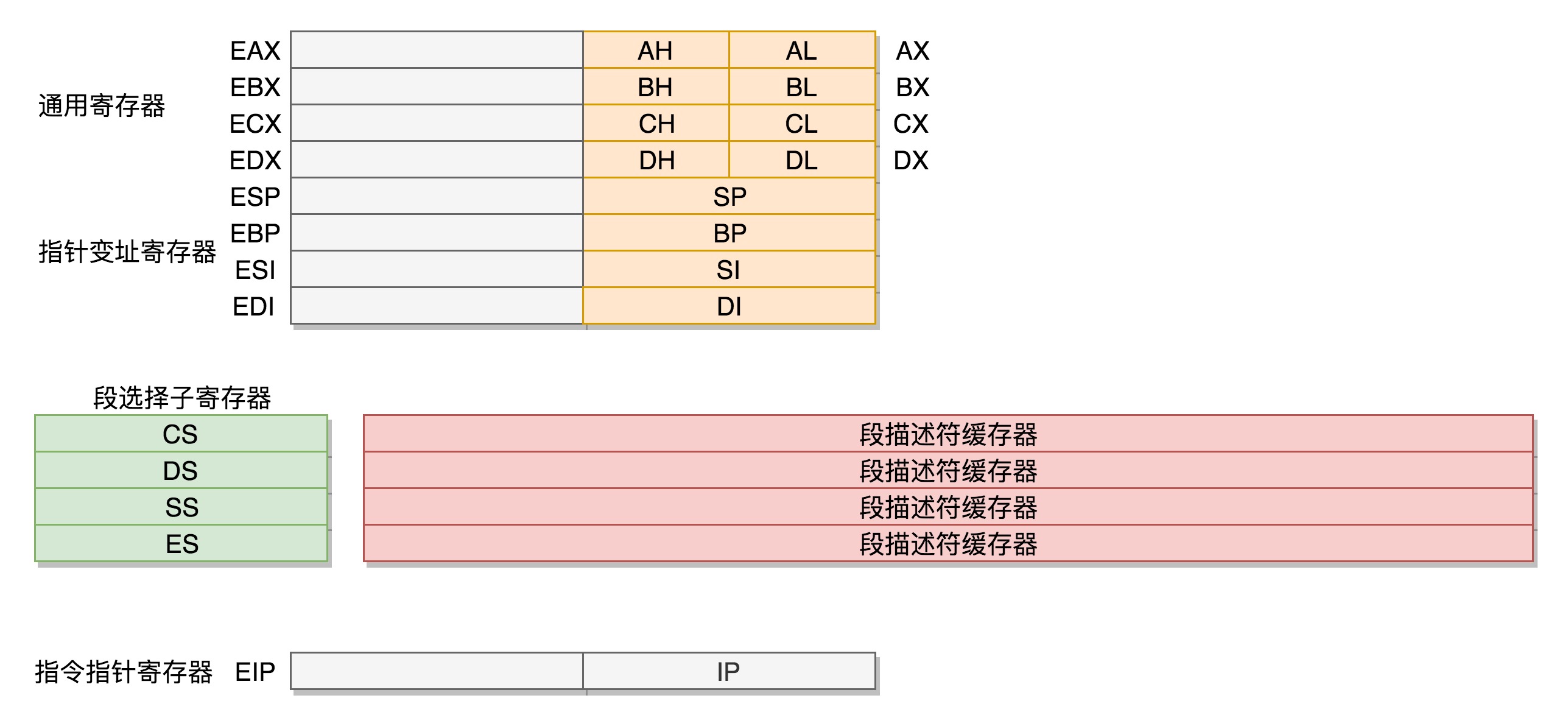
而改动比较大,有点不兼容的就是段寄存器(Segment Register)。
因为原来的模式其实有点不伦不类,因为它没有把 16 位当成一个段的起始地址,也没有按 8 位或者 16 位扩展的形式,而是根据当时的硬件,弄了一个不上不下的 20 位的地址。
这样每次都要左移四位,也就意味着段的起始地址不能是任何一个地方,只是能整除 16 的地方。
如果新的段寄存器都改成 32 位的,明明 4G 的内存全部都能访问到,还左移不左移四位呢?
那我们索性就重新定义一把吧。
CS、SS、DS、ES 仍然是 16 位的,但是不再是段的起始地址。段的起始地址放在内存的某个地方。
这个地方是一个表格,表格中的一项一项是段描述符(Segment Descriptor)。
这里面才是真正的段的起始地址。而段寄存器里面保存的是在这个表格中的哪一项,称为选择子(Selector)。
这样,将一个从段寄存器直接拿到的段起始地址,就变成了先间接地从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址。这样段起始地址就会很灵活了。
当然为了快速拿到段起始地址,段寄存器会从内存中拿到 CPU 的描述符高速缓存器中。
前面的模式出现的时候,没想到自己能够成为一个标准,所以设计就没这么灵活。
因而到了 32 位的系统架构下,我们将前一种模式称为实模式(Real Pattern),后一种模式称为保护模式(Protected Pattern)。
当系统刚刚启动的时候,CPU 是处于实模式的,这个时候和原来的模式是兼容的。
也就是说,哪怕你买了 32 位的 CPU,也支持在原来的模式下运行,只不过快了一点而已。
当需要更多内存的时候,你可以遵循一定的规则,进行一系列的操作,然后切换到保护模式,就能够用到 32 位 CPU 更强大的能力。
这也就是说,不能无缝兼容,但是通过切换模式兼容,也是可以接受的。在接下来的几节,我们就来看一下,CPU 如何从启动开始,逐渐从实模式变为保护模式的。
========================================














 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









