







Java分类、特性及原理
Java的三大分类:
JavaSE——Java语言的标准版,用于桌面应用开发,是其他两个版本的基础
JavaME——Java语言的小型版,用于嵌入式电子设备或者小型移动设备
JavaEE——Java语言的企业版,用于Web方向的网站开发

Java的主要特性:面向对象、安全性、多线程(同时做多件事情)、简单易用、开源、跨平台(程序可以在任意操作系统上运行)
Java跨平台的原理:
① Java语言的跨平台是通过虚拟机实现的
② Java语言不是直接运行在操作系统里面的,而是运行在虚拟机中的
③ 针对于不同的操作系统,安装不同的虚拟机就可以了
JDK(Java Development kit):java开发工具包。包括:
① JVM(Java Virtual Machine)虚拟机:Java程序运行的地方
② 核心类库:Java已经写好的东西,我们可以直接用
③ 开发工具:javac(编译工具)、java(运行工具)、jdb(调试工具)、jhat(内存分析工具)…
JRE(Java Runtime Environment):Java运行环境。包括:JVM、核心类库、运行工具
JDK、JRE、JVM三者的包含关系:JDK包含JRE,JRE包含JVM
注释
单行注释:
//注释信息
多行注释:
/* 注释信息 */
文档注释:
/** 注释信息 */
关键字
关键字:被Java赋予了特定含义的英文单词
特点:
① 关键字的字母全部小写
② 常用的代码编辑器,针对关键字有特殊的颜色标记,非常直观
字面量
| 字面量类型 | 说明 | 举例 |
|---|---|---|
| 整数类型 | 不带小数点的数字 | 666,-88 |
| 小数类型 | 带小数点的数字 | 13.14,-5.21 |
| 字符串类型 | 用双引号括起来的内容 | “123”,“” |
| 字符类型 | 用单引号括起来的,内容有且只能有一个 | ‘我’,‘0’ |
| 布尔类型 | 布尔值,表示真假 | true,false |
| 空类型 | 一个特殊的值,空值 | null |
注意:null不能直接打印,如果要打印null,那么只能用字符串的形式进行打印
特殊字符'\t':在打印的时候,把前面字符串的长度补齐到8,或者8的整数倍。最少补1个空格,最多补8个空格。(常用于字符串的对齐)
变量
定义格式:数据类型 变量名 = 数据值;
计算机中的数据存储
数据分类:Text文本、Image图片、Sound声音
1.Text文本:
数字:
① 二进制:由0和1组成,代码中以0b开头
② 十进制:由0-9组成,前面不加任何前缀
③ 八进制:由0-7组成,代码中以0开头
④ 十六进制:由0-9还有a-f组成,代码中以0x开头
字母:查询码表
汉字:查询码表
2.Image图片:
通过每一个像素点中的RGB三原色来存储。可以写成十进制形式(255,255,255),也可以写成十六进制形式(FFFFFF)
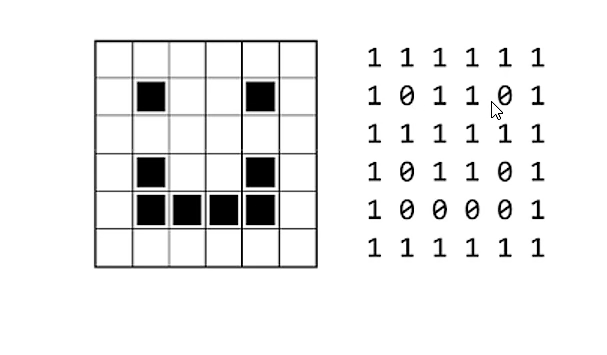
① 黑白图
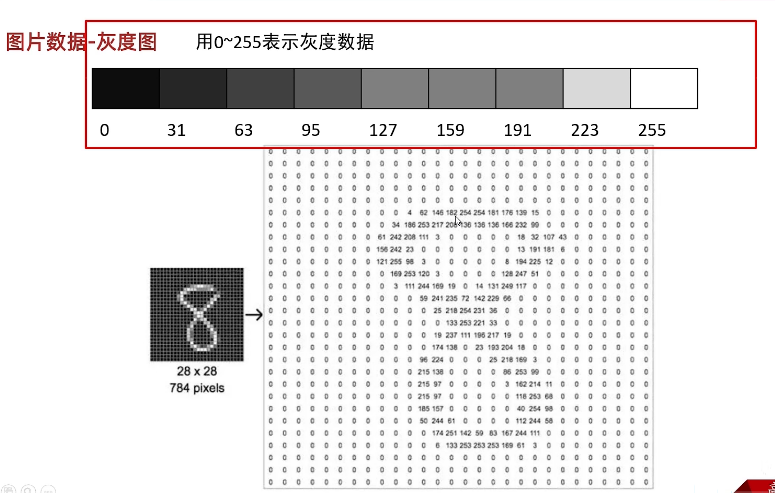
② 灰度图
③ 彩色图
即日常生活中的图片,采用RGB三原色来存储
3.Sound声音:
对声音的波形图进行采样再存储

数据类型
分类:基本数据类型、引用数据类型
基本数据类型:
| 数据类型 | 关键字 | 取值范围 | 内存占用 |
|---|---|---|---|
| 整数 | byte | -128~127 | 1 |
| short | -32768~32767 | 2 | |
| int默认 | -231~231-1(10位数) | 4 | |
| long | -263~263-1(19位数) | 8 | |
| 浮点数 | float | 略 | 4 |
| double默认 | 略 | 8 | |
| 字符 | char | 0-65535 | 2 |
| 布尔 | boolean | true,flase | 1 |
注意:
① 如果要定义long类型的变量,在数据值的后面需要加一个L作为后缀,L可以是大写的,也可以是小写的,但建议大写
② 定义float类型的变量,在数据值的后面需要加一个F作为后缀,F可大写可小写
标识符
命名规则:
① 由数字、字母、下划线和**美元符($)**组成
② 不能以数字开头
③ 不能是关键字
④ 区分大小写
键盘录入
Java帮我们写好一个类叫Scanner,这个类可以接收键盘输入的数字
步骤:
1.导包
import java.util.Scanner; //导包必须出现在类定义的上边
2.创建对象
Scanner sc = new Scanner(System.in) //只有sc是变量名可以变,其他不可以变
3.接收数据
int i = sc.nextInt(); //只有i是变量名可以变,其他不可以变
第一套体系(遇到空格,制表符,回车就停止接收):
nextInt(); //接收整数
nextDouble(); //接收小数
next(); //接收字符串
第二套体系(可以接收空格,制表符,遇到回车才停止接收数据):
nextLine();
IDEA项目结构介绍:project(项目)——> module(模块)——> package(包)——> class(类)。其中箭头表示包含关系
运算符
算术运算符:
| 符号 | 作用 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取模、取余 |
取值范围:byte < short < int < long < float < double
隐式转换的两种提升规则:
① 取值范围小的,和取值范围大的进行运算,小的会先提升为大的,再进行运算
② byte short char 三种类型的数据在运算的时候,都会直接先提升为int,然后再进行运算
强制转换:如果把一个取值范围大的,赋值给取值范围小的变量。是不允许直接赋值的(会报错),如果一定要这么做,就需要加入强制转换。
格式: 目标数据类型 变量名 = (目标数据类型) 被强转的数据
字符串的“+”操作:当“+”操作中出现字符串时,这个“+”是字符串连接符,而不是算术运算符了。会将前后的数据进行拼接,并产生一个新的字符串。
连续进行“+”操作时,从左到右逐个执行。例:1 + 99 + “年黑马” = “100年黑马”
**字符的"+"操作:**当字符+字符 / 字符+数字时,会把字符通过ASCII码表查询到对应的数字再进行计算
自增自减运算符:
| 符号 | 作用 | 说明 |
|---|---|---|
| ++ | 加 | 变量的值加1 |
| – | 减 | 变量的值减1 |
赋值运算符:
| 符号 | 作用 |
|---|---|
| = | 赋值 |
| += | 加后赋值 |
| -= | 减后赋值 |
| *= | 乘后赋值 |
| /= | 除后赋值 |
| %= | 取余后赋值 |
注意:+=、-=、*=、/=、%=底层都隐藏了一个强制类型转换,而转换的类型取决于左边的变量类型
short s = 1;
s += 1; //等同于:s = (short)(s+1)
关系运算符:
| 符号 | 说明 |
|---|---|
| == | a == b,判断a和b的值是否相等,成立为true,不成立为false |
| != | a != b,判断a和b的值是否不相等,成立为true,不成立为false |
| > | a > b,判断a是否大于b,成立为true,不成立为false |
| >= | a >= b,判断a是否大于等于b,成立为true,不成立为false |
| < | a < b,判断a是否小于b,成立为true,不成立为false |
| <= | a <= b,判断a是否小于等于b,成立为true,不成立为false |
注意:关系运算符的结果都是boolean类型
逻辑运算符:
| 符号 | 作用 | 说明 |
|---|---|---|
| & | 逻辑与(且) | 并且,两边都为真,结果才是真 |
| | | 逻辑或 | 或者,两边都为假,结果才是假 |
| ^ | 逻辑异或 | 相同为false,不同为true |
| ! | 逻辑非 | 取反 |
短路逻辑运算符:
| 符号 | 作用 | 说明 |
|---|---|---|
| && | 短路与 | 结果和&相同,但是有短路效果 |
| || | 短路或 | 结果与|相同,但是有短路效果 |
注意:& 和 | 无短路效果,只有&& 和 || 有短路效果
三元运算符:关系表达式 ? 表达式1 : 表达式2
运算符优先级:
| 优先级 | 运算符 |
|---|---|
| 1 | . () {} |
| 2 | !、~、++、– |
| 3 | *、/、% |
| 4 | +、- |
| 5 | <<、>>、>>> |
| 6 | <、<=、>、>=、instanceof |
| 7 | ==、!= |
| 8 | & |
| 9 | ^ |
| 10 | | |
| 11 | && |
| 12 | || |
| 13 | ? : |
| 14 | =、+=、-=、*=、/=、%=、&= |
补充:
原码的弊端:利用原码进行计算的时候,如果是整数完全没有问题。但是如果是负数计算,结果就出错,实际运算的方向,跟正确的运算方向是相反的
反码出现的目的:为了解决原码不能计算负数的问题而出现的
反码的弊端:负数运算的时候,如果结果不跨0,是没有任何问题的,但是如果结果跨0,跟实际结果会有1的偏差(因为0的反码有两个)
补码出现的目的:为了解决负数计算时跨0的问题而出现的
补码的注意点:计算机中的存储和计算都是以补码的形式进行的
其他的运算符:
| 运算符 | 含义 | 运算规则 |
|---|---|---|
| & | 逻辑与 | 0为false 1为true |
| | | 逻辑或 | 0为false 1为true |
| << | 左移 | 向左移动,低位补0 |
| >> | 右移 | 向右移动,高位补0或1 |
| >>> | 无符号右移 | 向右移动,高位补0 |
判断和循环
分支结构
if语句的第一种格式:
if(关系表达式){
语句体;
}
if语句的第二种格式:
if(关系表达式){
语句体1;
}
else{
语句体2;
}
if语句的第三种格式:
if(关系表达式1){
语句体1;
}
else if(关系表达式2){
语句体2;
}
...
else{
语句体n + 1;
}
switch语句格式:
switch(表达式){
case 值1:
语句体1;
break;
case 值2:
语句体2;
break;
...
default:
语句体n + 1;
break;
}
注意:表达式的取值为byte、short、int、char,JDK5以后可以是枚举,JDK7以后可以是String
switch新特性(JDK12后):可以利用箭头来简化代码的书写(可以简化break语句),当箭头后面只有一行代码时,可以不加大括号,如果有多行,则必须加大括号
int number = 10;
switch(number){ //当箭头后面只有一行代码时,可以省略大括号
case 1 -> System.out.println("一");
case 2 -> System.out.println("二");
case 3 -> System.out.println("三");
default -> System.out.println("没有这个选项");
}
//等价于下面的代码
/*
switch(number){
case 1: System.out.println("一"); break;
case 2: System.out.println("二"); break;
case 3: System.out.println("三"); break;
deafult: System.out.println("没有这个选项"); break;
}
*/
循环结构
for循环:
for(初始化语句;条件判断语句;条件控制语句){
循环体语句;
}
while循环:
初始化语句;
while(条件判断语句){
循环体语句;
条件控制语句;
}
do…while循环:
初始化语句;
do{
循环体语句;
条件控制语句;
} while(条件判断语句);
无限循环:
for(;;){
}
while(true){
}
do {
} while(true)
跳转控制语句:
1.continue:跳过本次循环,继续执行下次循环
2.break:结束整个循环
获取随机数:
1.导包
import Java.util.Random //导包的动作必须出现在类定义的上边
2.创建对象
Random r = new Random(); //这个格式中只有r是变量名,可以变,其他的都不允许变
3.生成随机数
int number = r.nextInt(上限 - 下限 + 1) + 下限
数组
数组的基本操作
数组容器在存储数据的时候,需要结合隐式转换考虑
例如:int类型的数组容器(boolean (×) byte (√) short (√) int (√) double (×))
例如:double类型的数组容器(byte (√) short (√) int (√) long (√) float (√) double (√))
数组的定义:
格式一:
数据类型[] 数组名;
格式二:
数据类型 数组名[];
数组的初始化:
① 静态初始化
数据类型[] 数组名 = new 数据类型 [] {元素1,元素2,元素3...};
简化格式
数据类型[] 数组名 = {元素1,元素2,元素3...};
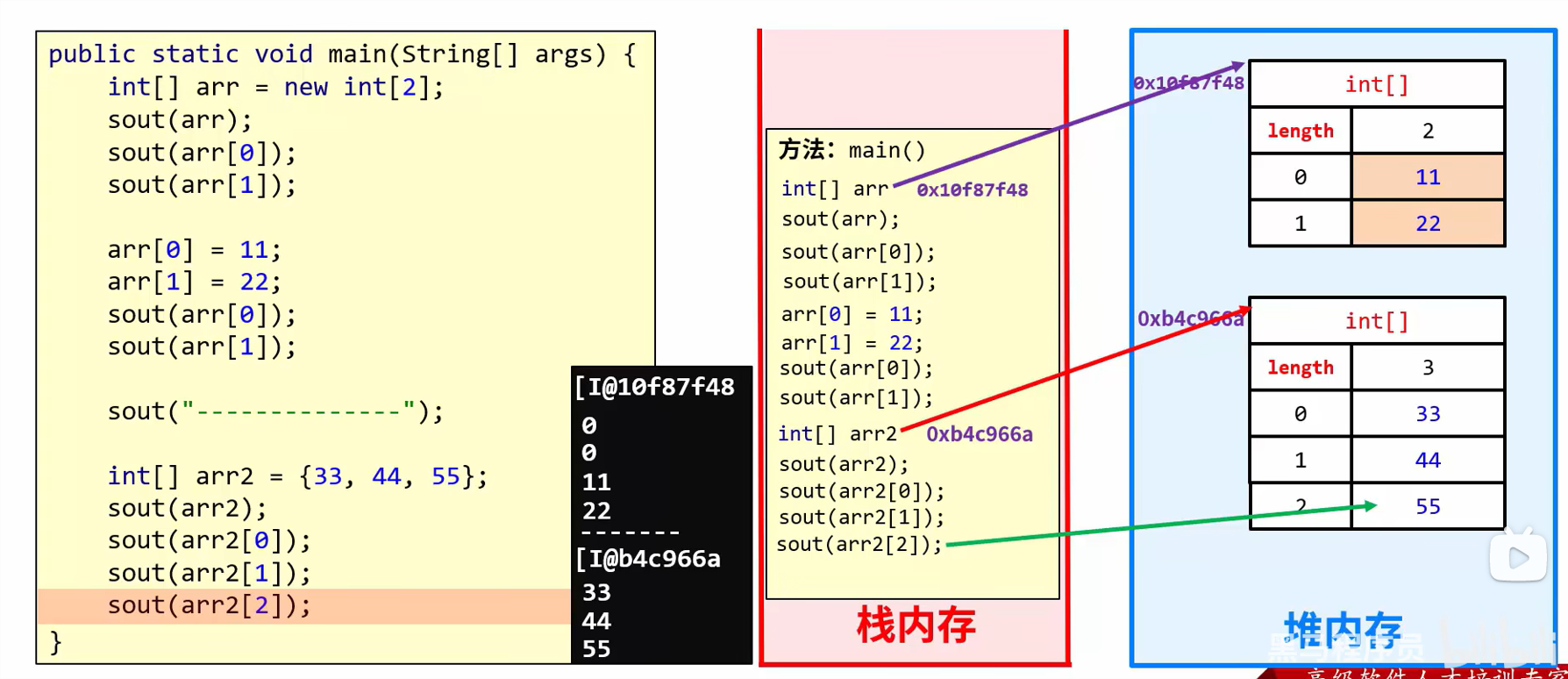
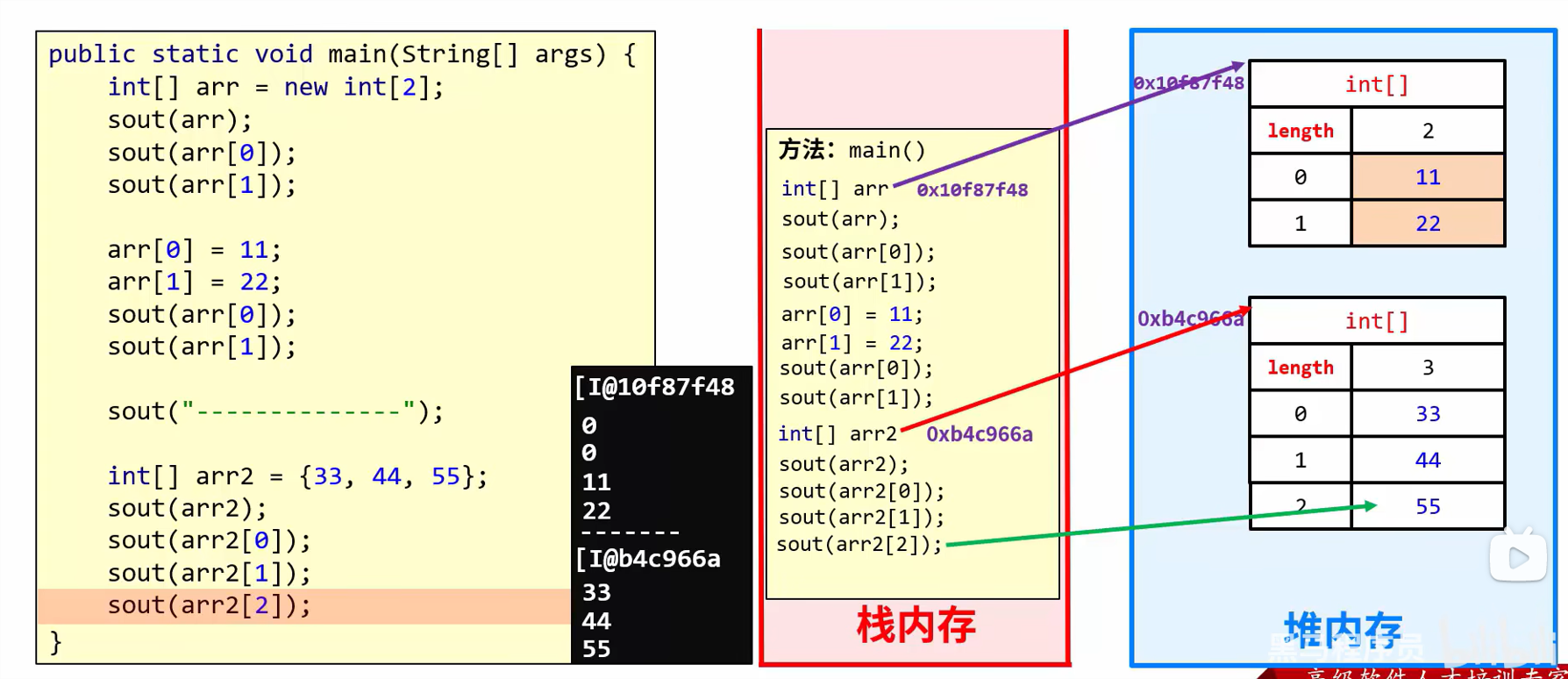
数组的地址值:
double[] arr = {1.93,1.94,1.96};
System.out.println(arr); //[D@7ef20235
//[:表示当前是一个数组
//D:表示当前数组里面的元素都是double类型的
//@:表示一个间隔符号(固定格式)
//7ef20235:是数组真正的地址值(十六进制)
数组元素访问:
数组名[索引];
数组的长度属性:
数组名.length
② 动态初始化
数据类型[] 数组名 = new 数据类型[数组长度]
动态初始化默认初始值规律:
| 类型 | 默认初始化值 |
|---|---|
| 整数类型 | 0 |
| 小数类型 | 0.0 |
| 字符类型 | ‘\u0000’ (空格) |
| 布尔类型 | false |
| 引用数据类型 | null |
二维数组的静态初始化:
数据类型[][] 数组名 = new 数据类型[][] {{元素1,元素2},{元素1,元素2}};
简化格式:
数据类型[][] 数组名 = {{元素1,元素2},{元素1,元素2}};
二维数组的动态初始化:
数据类型[][] 数组名 = new 数据类型[m][n];
二维数组的内存图:

由上图可以看出,二维数组实际内存是存在于堆内存中的,但是数组的引用是存储在栈内存中的
数组的内存分配
Java内存分配:
① 栈:方法运行时使用的内存,比如main方法运行,进入方法栈中执行
② 堆:存储对象或者数组,new来创建的,都存储在堆内存
③ 方法区:存储可以运行的class文件
④ 本地方法栈:JVM在使用操作系统功能的时候使用,和我们开发无关
⑤ 寄存器:给CPU使用,和我们开发无关
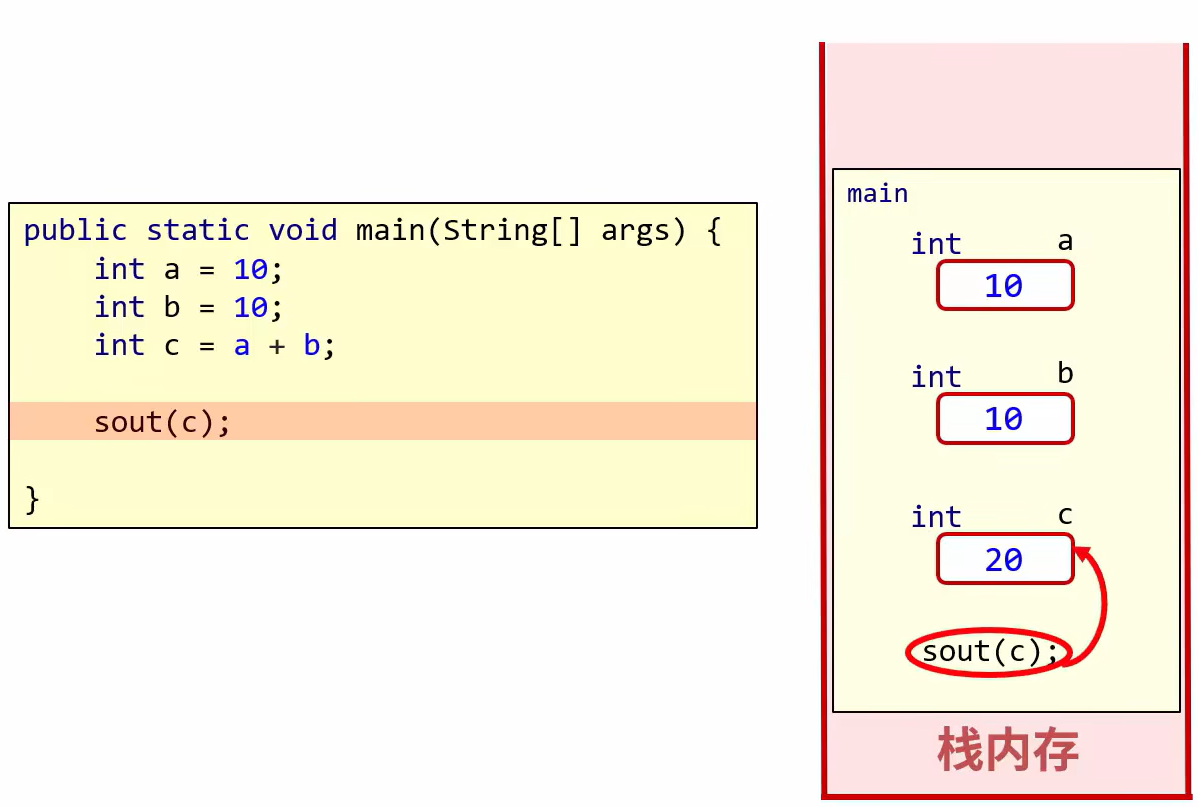
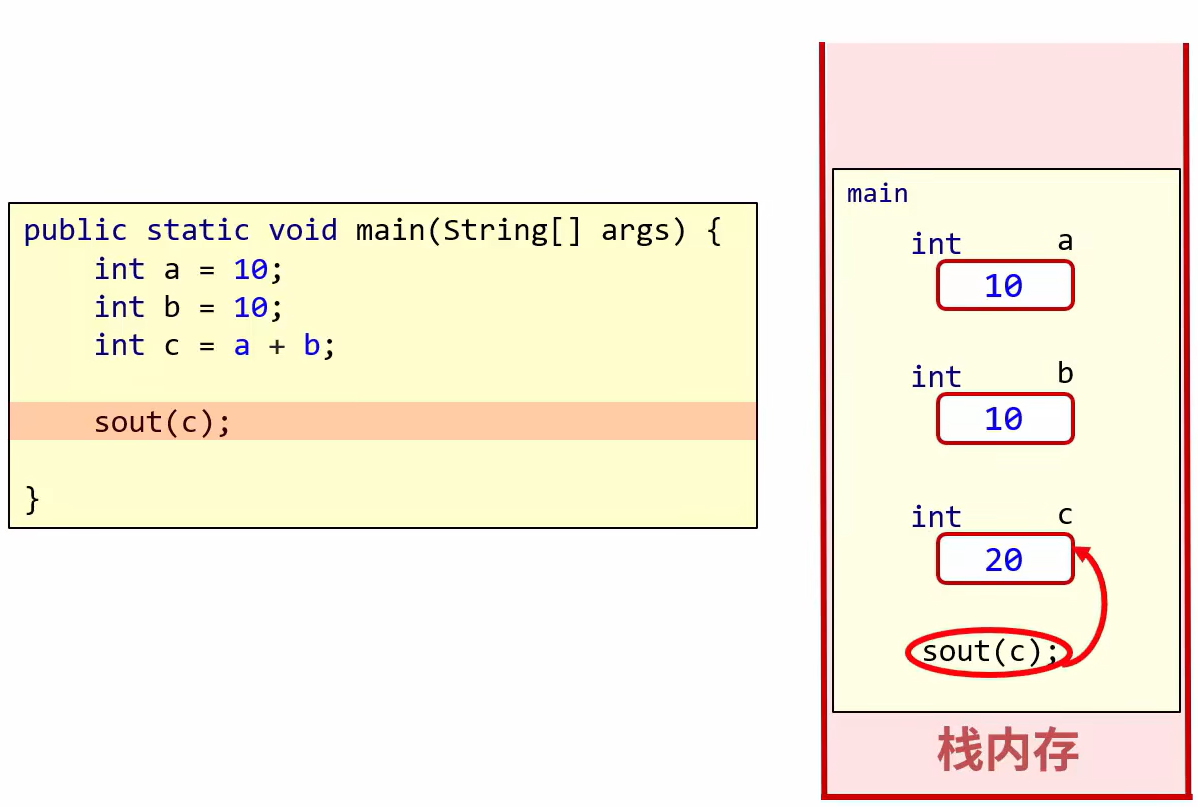
单一变量存储的数据存储在栈空间中
数组存储的数据存放在堆空间中,此时变量类似于指针
方法
方法(method)是程序中最小的执行单元
方法的定义格式:
public static 返回值类型 方法名(参数列表){
方法体;
return 返回值;
}
调用:
方法名(参数列表);
方法的重载:同一个类中,方法名相同,参数不同的方法,构成重载关系。与返回值无关。参数不同指的是个数不同、类型不同、顺序不同(只要存在一个不相同就是参数不同)
基本数据类型:数据值是存储在自己的空间中
特点:赋值给其他变量,也是赋的真实的值
引用数据类型:数据值是存储在其他空间中,自己空间中存储的是地址值
特点:赋值给其他变量,赋的是地址值
执行
② 堆:存储对象或者数组,new来创建的,都存储在堆内存
③ 方法区:存储可以运行的class文件
④ 本地方法栈:JVM在使用操作系统功能的时候使用,和我们开发无关
⑤ 寄存器:给CPU使用,和我们开发无关
单一变量存储的数据存储在栈空间中
数组存储的数据存放在堆空间中,此时变量类似于指针















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









