






写在前面:
这篇文章源于我们操作系统的作业,本着写都写了的思想就发到了网上。第一尝试,操作还不熟悉,所以格式有些混乱,若是给你的阅读带来影响还请谅解。
整个文章的内容涉及schedule.c,goodness.c,switch_to.c,process.c中的全部或部分函数解析,Linux系统调度算法的评述解析,以及一些相关名词解释的目录。书写的内容均是我查阅相关资料后的自我理解,受限于学业水平,这其中或有些许错误,或有解释不清的地方,还望指出;如有更好的想法,也欢迎你在评论区交流,一同进步。
下面,文章正式开始!
目录
GS(Global/General Segment register)
schedule.c源码解析
schedule()函数是Linux内核中负责进程调度的核心函数,其主要流程如下
⭐主要流程:
清理当前运行中的进程➡选择下一个要运行的进程➡设置新进程运行环境➡进程上下文切换
在开始讲述之前,我们将补充一些关于mm与active_mm的内容,以帮助大家更好阅读与理解源代码
mm与active_mm:
在Linux系统的地址空间存在着如图所示的两部分——“真实地址空间”与“匿名地址空间”。“真实地址空间”如同用户空间,这其中存放着我们日常运行的程序的进程,“匿名地址空间”则如内核空间,其中存放着原语等内容。

这两类地址最主要的区别Linus曾做过回复:“真实地址空间和匿名地址空间的的区别在于匿名地址空间不关心用户级的页表,所以当我们做一个上下文切换到匿名地址空间时我们只保留之前的活跃地址空间活跃。”而active_mm的产生正源于此。
在Linux系统中task_struct->mm指向真实地址空间(用户地址空间)。而对于匿名进程来说,task_struct->mm显而易见的为NULL,因为匿名进程位于匿名地址空间(内核空间)而非真实地址空间,然而我们仍然需要跟踪我们为这样的匿名用户“偷用”了哪个地址空间,因为前文的Linus的回复提到“我们需要保留之前的活跃地址空间(用户地址空间中)活跃”。可是mm已经为NULL无法记录了,于是我们便引入了active_mm来记录之前的地址空间。
理解了产生的原因,active_mm与mm二者记录地址的对应关系便容易理解了:对于一个有真实地址空间的进程(即mm是 non-NULL),active_mm显然与真实的mm相同。对于一个匿名进程来说,mm为NULL,而active_mm则记录着匿名进程运行时“借用”的地址空间。当匿名进程被调度走时,借用的地址空间被返回并清除。(清除的原因仍有待探究,目前可将active_mm视为一个锁)
接下来,我们将以代码中的标签处作为划分,通过流程图、文字与代码来解析整个每个代码块的作用与运行过程,进而帮助大家更好理解整个函数的运行过程,完整版流程图与注释版代码位于末尾。
need_resched_back:
有关中断的相关处理:若为中断处理调用,那么不允许进行任务调度,跳转到scheduling_in_interrupt进行处理;若为软中断请求则跳转到handle_softirq进行处理。
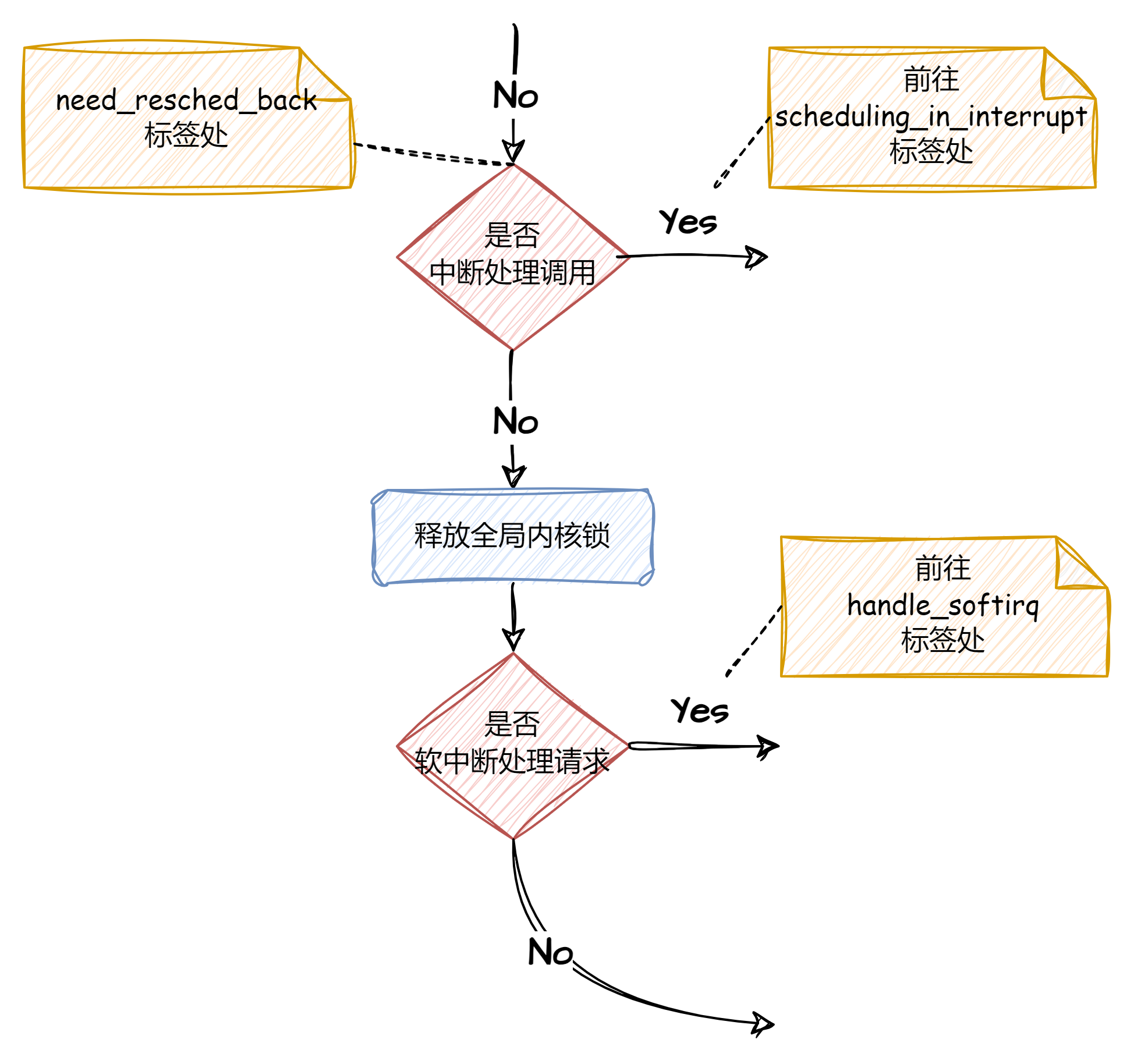
need_resched_back:
prev = current;
this_cpu = prev->processor;
if (in_interrupt()) //是否被中断处理调用?中断中不允许调度
goto scheduling_in_interrupt;
release_kernel_lock(prev, this_cpu); //释放全局内核锁,i386为空语句
/* Do "administrative" work here while we don't hold any locks */
if (softirq_active(this_cpu) & softirq_mask(this_cpu))//是否有软中断请求
goto handle_softirq;scheduling_in_interrupt:
显示出错信息,调用BUG()函数,结束函数

scheduling_in_interrupt://显示或者在/var/log/messages文件末尾添上一条出错信息
printk("Scheduling in interrupt\n");
BUG();
return;
}handle_softirq:
处理软中断请求,调转到handle_softirq_back

handle_softirq:
do_softirq();
goto handle_softirq_back;handle_softirq_back:
在处理软中断的上下文中,对特定CPU的调度数据进行访问和修改,当遇到轮转调度策略的进程时调转到move_rr_last

handle_softirq_back:
/*
* 'sched_data' is protected by the fact that we can run
* only one process per CPU.
*/
sched_data = & aligned_data[this_cpu].schedule_data;//保存当前CPU调度进程的数据区
spin_lock_irq(&runqueue_lock);//锁住可执行队列,防止其他处理器干扰
/* move an exhausted RR process to be last.. */
if (prev->policy == SCHED_RR)
goto move_rr_last;move_rr_last:
将时间片用完且未完成的进程移动到队列末尾,而后跳转到move_rr_back

move_rr_last:
if (!prev->counter) {//如果count为0,则时间片用完
prev->counter = NICE_TO_TICKS(prev->nice);//恢复最初的时间配额
move_last_runqueue(prev);//转移到队列的末尾
}
goto move_rr_back;move_rr_back:
根据进程当前的状态执行对应操作
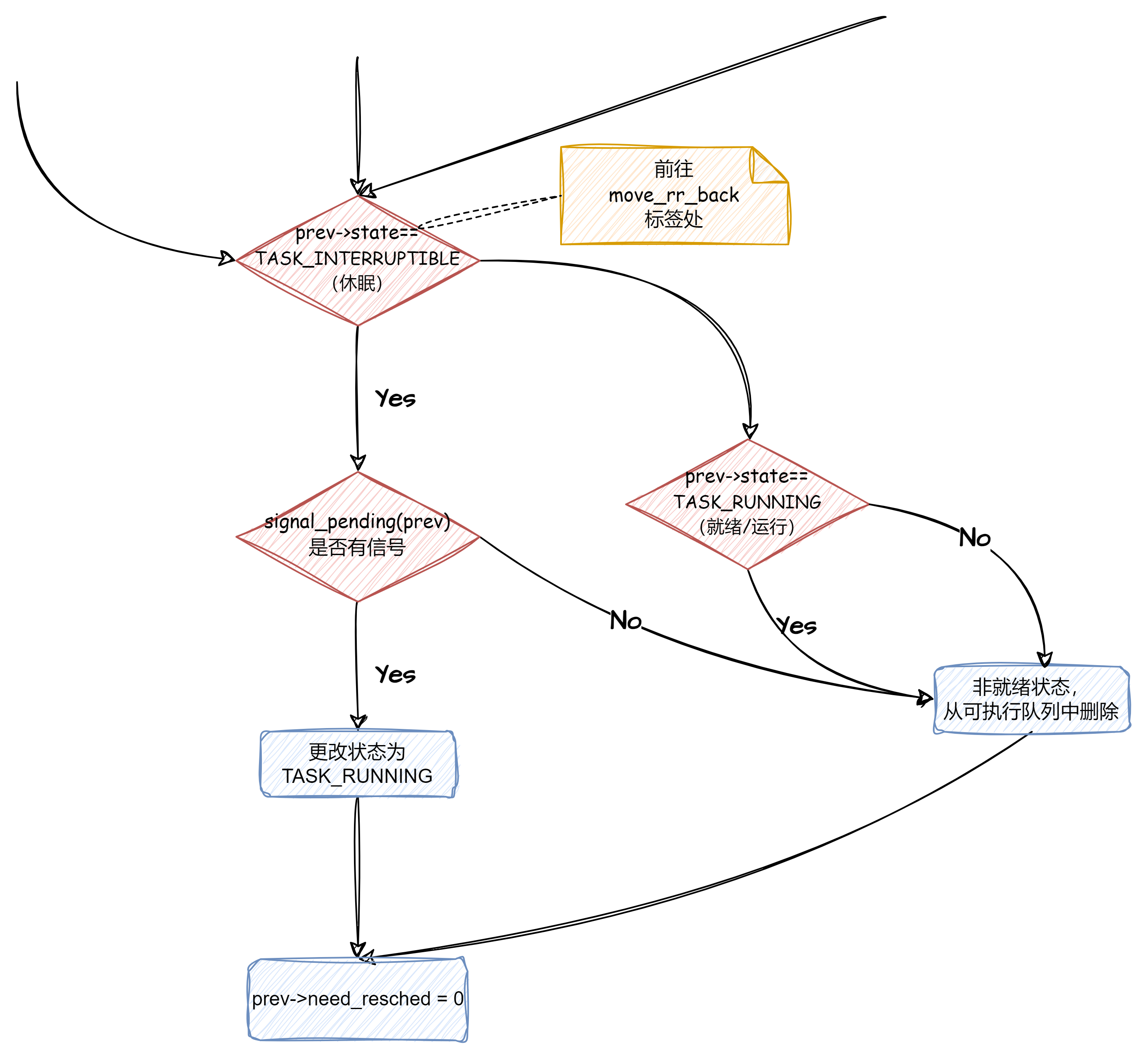
move_rr_back:
switch (prev->state) {
case TASK_INTERRUPTIBLE:
if (signal_pending(prev)) {//如果有信号,则让其去处理
prev->state = TASK_RUNNING;
break;
}//没有信号,继续向下,执行default
default:
del_from_runqueue(prev);//非就绪状态,从可执行队列中删除
case TASK_RUNNING:
}
prev->need_resched = 0;//所需要的调度已经在进行
/*
* this is the scheduler proper:
*/
repeat_schedule:
挑选下一进程,若前一进程仍在运行则跳转到still_running

repeat_schedule:
/*
* Default process to select..
*/
next = idle_task(this_cpu);//挑选的进程从idle进程开始
c = -1000;//idle进程的综合权值
if (prev->state == TASK_RUNNING)
goto still_running;still_running:
计算当前进程权值(repeat_schedule的前一进程)

still_running://如果当前进程希望继续运行,从当前进程开始挑选
c = goodness(prev, this_cpu, prev->active_mm);//计算当前进程权值
next = prev;
goto still_running_back;still_running_back:
在处理仍有进程运行的上下文中,遍历可执行队列中的所有进程,计算每个进程的权值,与当前最高值c相比;当权值为0时跳转到recalculate;当选中的是当前进程,跳转到same_process;其他情况中则进行进程切换的准备与执行
still_running_back://遍历可执行队列中的所有进程,计算每个进程的权值,与当前最高值c相比
list_for_each(tmp, &runqueue_head) {
p = list_entry(tmp, struct task_struct, run_list);//
if (can_schedule(p, this_cpu)) {//单CPU中恒为1
int weight = goodness(p, this_cpu, prev->active_mm);//计算权值
if (weight > c)//取权值大的进程
c = weight, next = p;
}
}
/* Do we need to re-calculate counters? */
if (!c)//权值为0,系统中没有就绪的实时进程,sched_other进程时间片用完(最低权值为0)
goto recalculate;//重新计算所有进程的配额时间
/*
* from this point on nothing can prevent us from
* switching to the next task, save this fact in
* sched_data.
*/
sched_data->curr = next;
#ifdef CONFIG_SMP
next->has_cpu = 1;
next->processor = this_cpu;
#endif
spin_unlock_irq(&runqueue_lock);
if (prev == next)//选中的是当前进程
goto same_process;
#ifdef CONFIG_SMP
/*
* maintain the per-process 'last schedule' value.
* (this has to be recalculated even if we reschedule to
* the same process) Currently this is only used on SMP,
* and it's approximate, so we do not have to maintain
* it while holding the runqueue spinlock.
*/
sched_data->last_schedule = get_cycles();
/*
* We drop the scheduler lock early (it's a global spinlock),
* thus we have to lock the previous process from getting
* rescheduled during switch_to().
*/
#endif /* CONFIG_SMP */
kstat.context_swtch++;
/*
* there are 3 processes which are affected by a context switch:
*
* prev == .... ==> (last => next)
*
* It's the 'much more previous' 'prev' that is on next's stack,
* but prev is set to (the just run) 'last' process by switch_to().
* This might sound slightly confusing but makes tons of sense.
*/
prepare_to_switch();//空语句
{
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if (!mm) {//新选进程是内核线程
if (next->active_mm) BUG();
next->active_mm = oldmm;//借用刚刚切换下去进程的活动mm结构
atomic_inc(&oldmm->mm_count);//增加借用mm的共享数
enter_lazy_tlb(oldmm, next, this_cpu);
} else {
if (next->active_mm != mm) BUG();
switch_mm(oldmm, mm, next, this_cpu);//用户空间切换
}
if (!prev->mm) {//如果切换掉的进程是借用mm结构
prev->active_mm = NULL;
mmdrop(oldmm);//借用结构的共享数减1
}
}
/*
* This just switches the register state and the
* stack.
*/
switch_to(prev, next, prev);//进程切换
__schedule_tail(prev);//将prev的policy字段的sched_yield清0recalculate:
遍历所有进程,重新计算权值,而后回到repeat_schedule

recalculate:
{
struct task_struct *p;
spin_unlock_irq(&runqueue_lock);
read_lock(&tasklist_lock);
for_each_task(p)//遍历所有进程,不仅是在就绪队列中,权值得以提升
p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
read_unlock(&tasklist_lock);
spin_lock_irq(&runqueue_lock);
}
goto repeat_schedule;same_process:
加锁,在中断的响应中重新进行调度

same_process:
reacquire_kernel_lock(current);//对i386单CPU为空语句
if (current->need_resched)//需要再次调度(前面已清0,必是发生中断,中断中要求重新调度)
goto need_resched_back;//重新调度
return;附:完整流程图与代码解析

/*
* 'schedule()' is the scheduler function. It's a very simple and nice
* scheduler: it's not perfect, but certainly works for most things.
*
* The goto is "interesting".
*
* NOTE!! Task 0 is the 'idle' task, which gets called when no other
* tasks can run. It can not be killed, and it cannot sleep. The 'state'
* information in task[0] is never used.
*/
asmlinkage void schedule(void)
{
struct schedule_data * sched_data;
struct task_struct *prev, *next, *p;
struct list_head *tmp;
int this_cpu, c;
if (!current->active_mm) BUG(); //当前进程不能是内核线程
need_resched_back:
prev = current;
this_cpu = prev->processor;
if (in_interrupt()) //是否被中断处理调用?中断中不允许调度
goto scheduling_in_interrupt;
release_kernel_lock(prev, this_cpu); //释放全局内核锁,i386为空语句
/* Do "administrative" work here while we don't hold any locks */
if (softirq_active(this_cpu) & softirq_mask(this_cpu))//是否有软中断请求
goto handle_softirq;
handle_softirq_back:
/*
* 'sched_data' is protected by the fact that we can run
* only one process per CPU.
*/
sched_data = & aligned_data[this_cpu].schedule_data;//保存当前CPU调度进程的数据区
spin_lock_irq(&runqueue_lock);//锁住可执行队列,防止其他处理器干扰
/* move an exhausted RR process to be last.. */
if (prev->policy == SCHED_RR)
goto move_rr_last;
move_rr_back:
switch (prev->state) {
case TASK_INTERRUPTIBLE:
if (signal_pending(prev)) {//如果有信号,则让其去处理
prev->state = TASK_RUNNING;
break;
}//没有信号,继续向下,执行default
default:
del_from_runqueue(prev);//非就绪状态,从可执行队列中删除
case TASK_RUNNING:
}
prev->need_resched = 0;//所需要的调度已经在进行
/*
* this is the scheduler proper:
*/
repeat_schedule:
/*
* Default process to select..
*/
next = idle_task(this_cpu);//挑选的进程从idle进程开始
c = -1000;//idle进程的综合权值
if (prev->state == TASK_RUNNING)
goto still_running;
still_running_back://遍历可执行队列中的所有进程,计算每个进程的权值,与当前最高值c相比
list_for_each(tmp, &runqueue_head) {
p = list_entry(tmp, struct task_struct, run_list);//
if (can_schedule(p, this_cpu)) {//单CPU中恒为1
int weight = goodness(p, this_cpu, prev->active_mm);//计算权值
if (weight > c)//取权值大的进程
c = weight, next = p;
}
}
/* Do we need to re-calculate counters? */
if (!c)//权值为0,系统中没有就绪的实时进程,sched_other进程时间片用完(最低权值为0)
goto recalculate;//重新计算所有进程的配额时间
/*
* from this point on nothing can prevent us from
* switching to the next task, save this fact in
* sched_data.
*/
sched_data->curr = next;
#ifdef CONFIG_SMP
next->has_cpu = 1;
next->processor = this_cpu;
#endif
spin_unlock_irq(&runqueue_lock);
if (prev == next)//选中的是当前进程
goto same_process;
#ifdef CONFIG_SMP
/*
* maintain the per-process 'last schedule' value.
* (this has to be recalculated even if we reschedule to
* the same process) Currently this is only used on SMP,
* and it's approximate, so we do not have to maintain
* it while holding the runqueue spinlock.
*/
sched_data->last_schedule = get_cycles();
/*
* We drop the scheduler lock early (it's a global spinlock),
* thus we have to lock the previous process from getting
* rescheduled during switch_to().
*/
#endif /* CONFIG_SMP */
kstat.context_swtch++;
/*
* there are 3 processes which are affected by a context switch:
*
* prev == .... ==> (last => next)
*
* It's the 'much more previous' 'prev' that is on next's stack,
* but prev is set to (the just run) 'last' process by switch_to().
* This might sound slightly confusing but makes tons of sense.
*/
prepare_to_switch();//空语句
{
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if (!mm) {//新选进程是内核线程
if (next->active_mm) BUG();
next->active_mm = oldmm;//借用刚刚切换下去进程的活动mm结构
atomic_inc(&oldmm->mm_count);//增加借用mm的共享数
enter_lazy_tlb(oldmm, next, this_cpu);
} else {
if (next->active_mm != mm) BUG();
switch_mm(oldmm, mm, next, this_cpu);//用户空间切换
}
if (!prev->mm) {//如果切换掉的进程是借用mm结构
prev->active_mm = NULL;
mmdrop(oldmm);//借用结构的共享数减1
}
}
/*
* This just switches the register state and the
* stack.
*/
switch_to(prev, next, prev);//进程切换
__schedule_tail(prev);//将prev的policy字段的sched_yield清0
same_process:
reacquire_kernel_lock(current);//对i386单CPU为空语句
if (current->need_resched)//需要再次调度(前面已清0,必是发生中断,中断中要求重新调度)
goto need_resched_back;//重新调度
return;
recalculate:
{
struct task_struct *p;
spin_unlock_irq(&runqueue_lock);
read_lock(&tasklist_lock);
for_each_task(p)//遍历所有进程,不仅是在就绪队列中,权值得以提升
p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
read_unlock(&tasklist_lock);
spin_lock_irq(&runqueue_lock);
}
goto repeat_schedule;
still_running://如果当前进程希望继续运行,从当前进程开始挑选
c = goodness(prev, this_cpu, prev->active_mm);//计算当前进程权值
next = prev;
goto still_running_back;
handle_softirq:
do_softirq();
goto handle_softirq_back;
move_rr_last:
if (!prev->counter) {//如果count为0,则时间片用完
prev->counter = NICE_TO_TICKS(prev->nice);//恢复最初的时间配额
move_last_runqueue(prev);//转移到队列的末尾
}
goto move_rr_back;
scheduling_in_interrupt://显示或者在/var/log/messages文件末尾添上一条出错信息
printk("Scheduling in interrupt\n");
BUG();
return;
}-
goodness.c源码解析
-
goodness.c核心是名为goodness的静态内联函数,它的主要作用是评估一个进程权重(优先级),以便调度器选择下一个要进行的进程。其主要按照如下的流程展开。
-
⭐主要流程:
初始化权值处理➡sched_yield调用➡非实时进程➡实时进程➡权值返回
(后文解析中忽略了首尾的初始化权值与权值返回,因其内容简单)
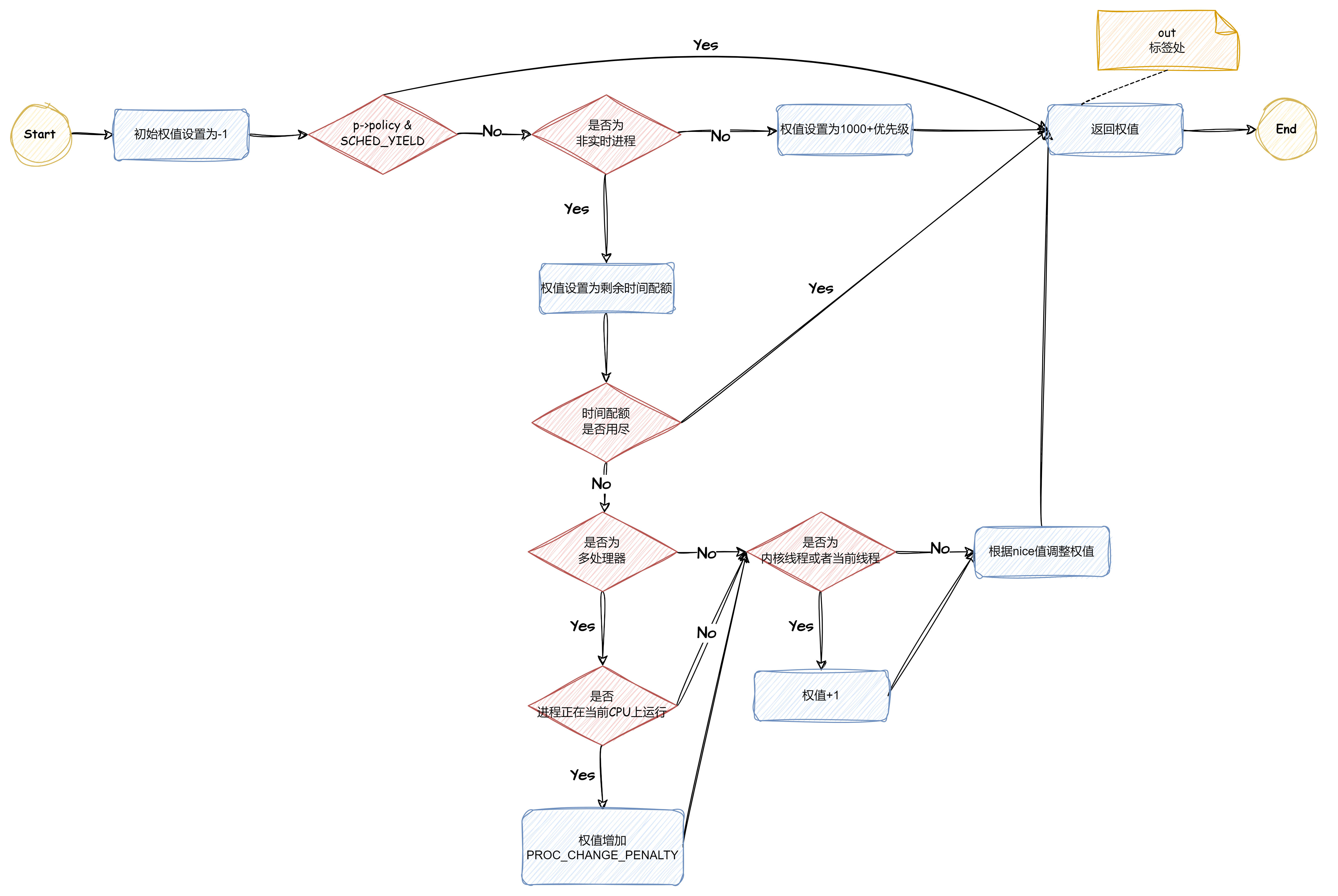
-
处理sched_yield调用
-
SCHED_YIELD
- 与进程调度相关的一个系统调用函数。它的作用是让当前进程或线程主动放弃CPU的使用权,以便其他进程或线程可以获得更多的CPU时间片。
-
weight = -1;
if (p->policy & SCHED_YIELD)//若进程调用sched_yield()表示让出CPU,则权值为-1,低于所有就绪进程
goto out;-
非实时进程
- SCHED_OTHER(分时调度策略)
- Linux内核默认的调度策略,用于对普通进程进行调度,采用的调度方式为时间片轮转方式。
- 权值计算:
- 未用完的时间配额与nice的和
- nice:
- 负向优先级,表示“谦让”的程度
- 取值范围:19~-20,-20最高,特权用户能小于0
- 内核线程或者当前线程权重更高
- 原因在于,这样的处理这样的线程,可以避免上下文切换带来的开销,系统负担更小
- SCHED_OTHER(分时调度策略)
if (p->policy == SCHED_OTHER) {
/*
* Give the process a first-approximation goodness value
* according to the number of clock-ticks it has left.
*
* Don't do any other calculations if the time slice is
* over..
*/
weight = p->counter;
if (!weight)//时间配额用完
goto out;
#ifdef CONFIG_SMP
/* Give a largish advantage to the same processor... */
/* (this is equivalent to penalizing other processors) */
if (p->processor == this_cpu)
weight += PROC_CHANGE_PENALTY;
#endif
/* .. and a slight advantage to the current MM */
if (p->mm == this_mm || !p->mm)//内核线程或者当前线程,不用切换上下文,优先权提高1
weight += 1;
weight += 20 - p->nice;//未用完的时间配额与nice的和
goto out;
}-
实时进程
- 1000的由来:权值规则
- rt_priority属性
- -1000:从不选择
- 0:超时,需要重新计算(有可能会被选中)
- +ve:goodness计算的值,越大越好
- +1000:实时进程,优先选择此进程
- rt_priority属性
- 专门用于实时进程,用以表示实时进程的优先级。
- 1000的由来:权值规则
/*
* Realtime process, select the first one on the
* runqueue (taking priorities within processes
* into account).
*/
weight = 1000 + p->rt_priority;-
switch_to.c源码解析
-
switch_to函数是Linux内核上下文切换的核心,它通过操作CPU寄存器和堆栈实现了进程之间的快速切换。但在我们正式开始switch_to函数代码详解之前,我们不妨回忆一下进程切换的调度过程。
-
⭐调度过程:
保存镜像➡调度算法➡进程切换➡处理机回收
每一阶段的具体内容不再赘述,因为这不是重点。在这里提到“调度过程”,是因为switch_to函数在一定程度上是按照这一流程展开的。(我们忽略了准备阶段的prepare_to_switch函数,因其内容为空)

-
保存镜像(记录现场信息部分)
- 实现保存当前进程的ESI, EDI, EBP寄存器到堆栈的功能
(有关ESI, EDI, EBP段寄存器功能的内容,我们放在了附录中)
#define prepare_to_switch() do { } while(0) // 准备切换阶段,代码为空意味着不需要特别的准备步骤
#define switch_to(prev,next,last) do { \
asm volatile( "pushl %%esi\n\t" //保存ESI寄存器到堆栈 \
"pushl %%edi\n\t" //保存EDI寄存器到堆栈 \
"pushl %%ebp\n\t" //保存EBP寄存器到堆栈 \
-
调度算法:该部分暂不涉及 -
进程切换:
- 当从__switch_to返回时,堆栈上的next->thread.eip将被弹出到EIP,实现进程切换
- 原因在于,EIP寄存器是x86架构中的指令指针寄存器,它存储了CPU接下来要执行的指令的地址。因此,当next->thread.eip被加载到EIP时,CPU将开始执行新进程的指令,从而实现进程的切换。
- 当从__switch_to返回时,堆栈上的next->thread.eip将被弹出到EIP,实现进程切换
(有关__switch_to函数的内容,我们将在process.c解析中阐述)
(有关TSS、GS、FS三个段寄存器功能的内容,我们放在了附录中)
"movl %%esp,%0\n\t" /* 将当前ESP(堆栈指针)保存到prev->thread.esp */
"movl %3,%%esp\n\t" /* 将next->thread.esp的值加载到ESP,切换到新进程的堆栈 */
"movl $1f,%1\n\t" /* 将当前指令地址(即'1:'标签的地址)保存到prev->thread.eip */
"pushl %4\n\t" /* 将next->thread.eip压入堆栈,这是新进程恢复执行时的EIP */
"jmp __switch_to\n" /* 跳转到__switch_to函数,该函数负责处理TSS、GS、FS段寄存器等 */
"1:\t" \ -
调度算法:该部分暂不涉及 -
信息恢复:
- 从堆栈中恢复ESI, EDI, EBP寄存器的值
- 为保证进程再次被调度时,能够保证程序执行的连续性与正确性,我们需要取出先前存储的信息,这也是为什么在一开始需要存储ESI, EDI, EBP寄存器的值。
- 从堆栈中恢复ESI, EDI, EBP寄存器的值
"popl %%ebp\n\t" /* 从堆栈恢复EBP寄存器 */
"popl %%edi\n\t" /* 从堆栈恢复EDI寄存器 */
"popl %%esi\n\t" /* 从堆栈恢复ESI寄存器 */ -
约束:
- 输入、输出与寄存器约束
- (是GCC内联汇编(Inline Assembly)的一部分,详细原因暂不知晓)
- 输入、输出与寄存器约束
/*输出约束*/
:"=m" (prev->thread.esp),"=m" (prev->thread.eip), /*将汇编指令的结果和$1f的地址分别存储到对应位置*/ \
"=b" (last) \
/*输入约束*/
:"m" (next->thread.esp),"m" (next->thread.eip), /*将新进程的堆栈指针和指令指针加载到对应位置*/ \
/*寄存器约束*/
"a" (prev), "d" (next), \
"b" (prev)); \
} while (0)-
process.c源码解析
-
process.c文件是Linux内核中针对x86(特指i386架构)这一体系结构进行进程处理的相关部分。这一文件中包含了许多内容,例如电源管理、hlt指令相关使用、空闲时系统默认执行的部分等,内容极为丰富。但我们的重点是schedule函数以及与之相关的代码,所以下文将会着重介绍switch_to.c中使用的__switch_to函数。
-
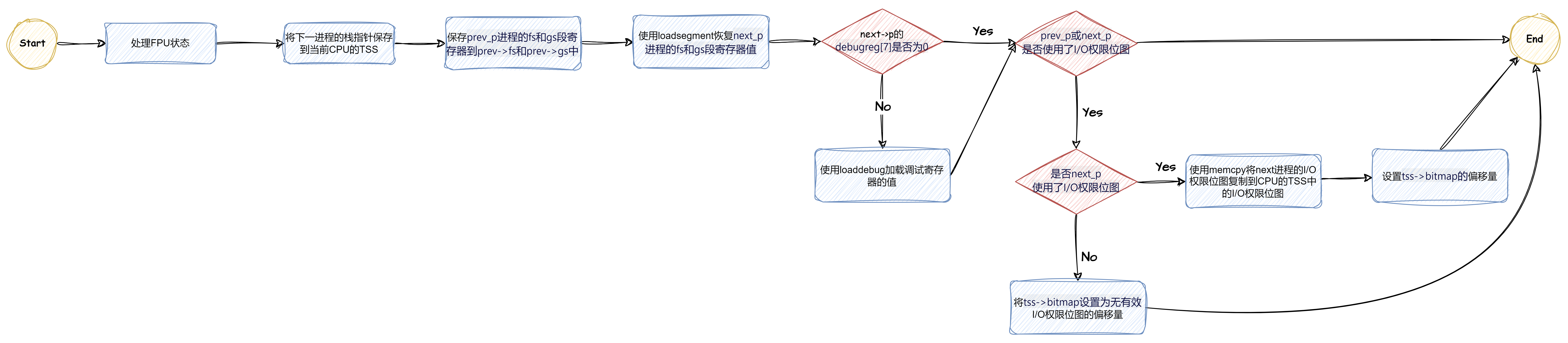
⭐主要流程:
FPU状态➡保存和恢复上下文➡调试寄存器➡I/O权限位图
-
FPU状态
- unlazy_fpu()
- 若prev_p进程使用了FPU,函数unlazy_fpu()会确保FPU的状态被保存或标记为“已保存”,以便在需要时可以恢复
- unlazy_fpu()
(有关FPU功能的内容,我们放在了附录中)
void __switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread,
*next = &next_p->thread;
struct tss_struct *tss = init_tss + smp_processor_id();
unlazy_fpu(prev_p);-
保存和恢复上下文
- 保存esp栈指针
- 这是为了确保当CPU切换到next_p进程时,能够正确地使用其栈。
- asm volatile
- asm关键字用于嵌入汇编语言代码
- volatile关键字通常用于告诉编译器不要对该变量进行优化,即每次访问该变量时都应该直接从内存中读取它的值,而不是使用可能已经缓存在寄存器中的值。
- 保存esp栈指针
/*
* Reload esp0, LDT and the page table pointer:
*/
tss->esp0 = next->esp0;
/*
* Save away %fs and %gs. No need to save %es and %ds, as
* those are always kernel segments while inside the kernel.
*/
asm volatile("movl %%fs,%0":"=m" (*(int *)&prev->fs));
asm volatile("movl %%gs,%0":"=m" (*(int *)&prev->gs));
/*
* Restore %fs and %gs.
*/
loadsegment(fs, next->fs);
loadsegment(gs, next->gs);
-
调试寄存器
(有关调试寄存器功能的内容,我们放在了附录中)
/*
* Now maybe reload the debug registers
*/
if (next->debugreg[7]){
loaddebug(next, 0);
loaddebug(next, 1);
loaddebug(next, 2);
loaddebug(next, 3);
/* no 4 and 5 */
loaddebug(next, 6);
loaddebug(next, 7);
}-
I/O权限位图
- 偏移量设置
- 将
tss->bitmap设置为IO_BITMAP_OFFSET,这个偏移量告诉内核在哪里可以找到TSS中的I/O权限位图。 - 将
tss->bitmap设置为INVALID_IO_BITMAP_OFFSET。这是一个特殊的偏移量,表示TSS中没有有效的I/O权限位图。在此情况下当使用I/O端口指令,内核能够检测并生成段错误来终止违规进程
- 将
- 偏移量设置
if (prev->ioperm || next->ioperm) {
if (next->ioperm) {
/*
* 4 cachelines copy ... not good, but not that
* bad either. Anyone got something better?
* This only affects processes which use ioperm().
* [Putting the TSSs into 4k-tlb mapped regions
* and playing VM tricks to switch the IO bitmap
* is not really acceptable.]
*/
memcpy(tss->io_bitmap, next->io_bitmap,
IO_BITMAP_SIZE*sizeof(unsigned long));
tss->bitmap = IO_BITMAP_OFFSET;
} else
/*
* a bitmap offset pointing outside of the TSS limit
* causes a nicely controllable SIGSEGV if a process
* tries to use a port IO instruction. The first
* sys_ioperm() call sets up the bitmap properly.
*/
tss->bitmap = INVALID_IO_BITMAP_OFFSET;
}-
调度算法评述和解释
-
Linux中的调度算法主要有三种策略,两种类别。它根据进程的特点以及权衡不同调度策略的优劣,实现了精准匹配,最大限度地发挥所选调度策略的优势,同时规避其潜在的劣势,提高系统的整体运行效率和使用体验。
-
-
类别一:实时调度策略
-
这一类别中有两种调度策略,分别是SCHED_FIFO和SCHED_RR
-
-
SCHED_FIFO先入先出(先来先服务)
- 内容:调度方式与数据结构中的队列相同,先到先服务。
-
-
-
- 优缺点:这种调度方式的优势在于可以充分利用CPU资源,但劣势在于不能很好应对I/O繁忙性作业
- 评述:Linux系统是对“时间要求较强、运行时间较短的进程”使用这种调度策略,这种策略可以及时响应较为紧急的进程,因为我们可以将这一进程置于队首,使处理机先相应。同时这类进程运行时间短的特点,也很好规避了队列服务易因运行时间长造成排序较后的进程的饥饿问题。
-
-
-
SCHED_RR循环轮转(时间片轮转调度)
- 内容:按进程到达就绪队列的顺序,轮流分配一个时间片去执行,时间用完则剥夺
-
-
-
- 优缺点:这种调度方式的优势在于公平、响应快,但劣势在于较差的时间片划分会给系统的运行效率和开销带来负面影响
- 评述:Linux系统是对“运行时间较长的进程”使用这种调度策略,通过合理的时间片划分,这种策略可以分段逐次相应每一个进程,每次处理一点,不断轮转直到处理结束。虽然不能一次处理完毕,但这有助避免由于单个进程处理时间过长导致的后续进程饥饿问题,提高了系统的运行效率。
-
-
-
类别二:分时调度策略
-
这一类别的调度策略为SCHED_OTHER
-
-
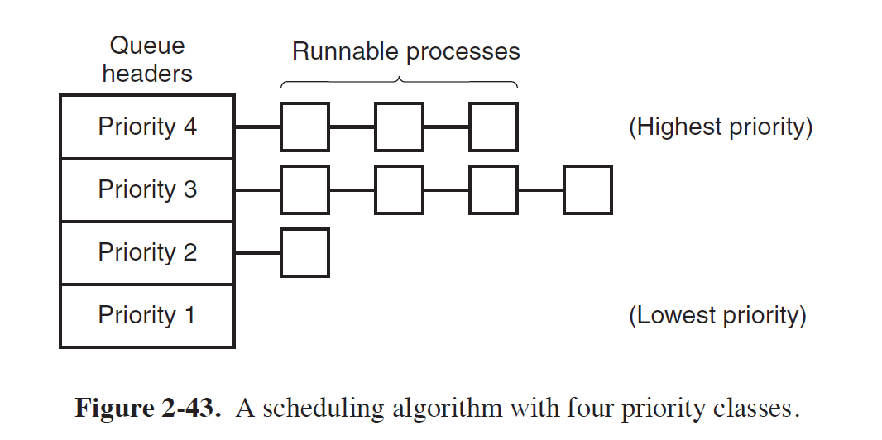
SCHED_OTHER普通策略(优先级调度)
-
虽然名字中没有直接指出调度策略的内容,但通过我们上面的分析,特别是对goodness.c的分析,我们可以看到SCHED_OTHER的调度策略与PSA优先级调度策略并无太多的区别,因此下文将以优先级调度策略来分析解释SCHED_OTHER策略
- 内容:按作业/进程的优先级(紧迫程度)进行调度。
-
-
-
-
- 优缺点:这种调度方式的优势在于可以提升系统响应,优化资源利用,但劣势优先级在很多时候不易确定下来且较差的优先级划分会给系统的运行效率和开销带来负面影响
- 评述:Linux系统主要是对“没有实时要求的进程”使用这种调度策略,但我们在goodness代码分析中也可以看到,实时进程拥有着最高的权重,所以这种调度策略也在实际参与实时进程的调度。而对于没有实时性要求的进程来说,这种策略通过对不同进程赋予轻重缓急实现优化系统资源利用,提高系统响应速度。同时非实时性要求的进程也在一定程度上规避了,较差的优先级划分会给系统带来较大负面影响的风险。提高系统的健壮性,维持了系统正常运行。
-
-
附录
资料源:文心一言
ESI寄存器
作用:ESI寄存器通常用作源索引寄存器,在数据传输和字符串操作中,它存储源数据或源字符串的起始地址。在上下文切换的过程中,ESI寄存器的值被保存到堆栈中,以便在恢复旧进程的执行时能够恢复其原始状态。
EDI寄存器
作用:EDI寄存器通常用作目的索引寄存器,在数据传输和字符串操作中,它存储目标数据或目标字符串的起始地址。与ESI类似,EDI也用于在数据传输过程中标识数据的去向。
EBP寄存器
作用:EBP寄存器是扩展基指针寄存器,它通常用于指向当前函数的栈帧的基地址。栈帧是函数调用期间在栈上分配的一块内存区域,用于存储局部变量、函数参数、返回地址和其他临时数据。通过EBP,程序可以方便地访问栈帧中的各个元素。
TSS(Task-State Segment)
作用:
存储任务上下文:TSS是一块内存区域,用于存储CPU寄存器的状态信息,包括通用寄存器、段寄存器、指令指针(EIP/RIP)、标志寄存器等。当任务(在操作系统层面通常指线程)从用户态切换到内核态或从内核态切换回用户态时,TSS用于保存和恢复这些寄存器的值,以确保任务的上下文在切换过程中得到正确的保存和恢复。
支持多任务并发:在多核处理器上,每个核都可以同时运行不同的任务。因此,每个核都需要有自己的TSS来存储当前任务的上下文信息。这样,当任务切换发生时,CPU可以快速地从一个任务的上下文切换到另一个任务的上下文。
组成:
TSS主要由几个区域组成,包括链接字段区域、内层堆栈指针区域、地址映射寄存器区域、寄存器保存区域和其他字段。其中,寄存器保存区域用于保存任务切换时需要保存的寄存器值。
GS(Global/General Segment register)
作用:
存储全局描述符表(GDT)的索引:在x86架构中,GS寄存器通常用于存储全局描述符表(GDT)中某个描述符的索引。GDT是一种数据结构,用于定义内存段的属性和访问权限。通过GS寄存器,CPU可以快速访问GDT中的描述符,从而实现对内存段的访问控制。
提供内存隔离和保护:GS寄存器的使用可以提供更高级别的内存隔离和保护。通过为不同的任务或线程分配不同的GDT描述符,可以确保它们只能访问被授权的内存段,从而防止内存冲突和数据泄露。
注意:
在某些情况下,GS寄存器也可能被用作其他目的,如实现线程局部存储(TLS)。但是,在Linux内核的上下文中,GS寄存器的主要作用仍然是与GDT相关。
FS(Flat Segment register)
作用:
存储段选择子:FS寄存器通常用于存储一个段选择子(Segment Selector),该选择子指向GDT或LDT(局部描述符表)中的一个描述符。通过这个描述符,CPU可以访问特定的内存段。
获取进程和线程信息:在Linux内核中,FS寄存器经常被用作访问进程和线程相关信息的入口点。例如,FS寄存器可能指向一个包含当前线程信息的结构(如KTHREAD或TEB),通过该结构,内核可以方便地获取当前线程的堆栈、上下文等信息。
FPU(Float Point Unit):
一种专门用于执行浮点运算(如加法、减法、乘法、除法等)的硬件单元。
特点:
计算精度高:FPU能够提供比软件模拟更高的浮点运算精度,满足高精度计算的需求。
数学函数丰富:FPU内置了大量的数学函数,可以高效地执行复杂的数学运算,减少软件层面的计算负担。
线程安全性高:FPU的运算通常是线程安全的,这意味着在多线程环境下,FPU能够减少因浮点运算导致的线程冲突和数据不一致性问题。
I/O操作高效:在需要频繁进行浮点数据I/O操作的场景中,FPU能够显著提高数据处理效率。
调试寄存器:
是一组特殊的CPU寄存器,它们被设计用来支持调试和追踪功能。
类别:
断点寄存器:用于设置软件断点的地址。当CPU执行到这些地址时,可以触发调试异常,使得调试器能够接管执行流程,从而允许开发者检查程序的状态。
监视寄存器:这些寄存器可以用来监视特定的内存地址或数据值。当这些地址被访问或数据值发生特定变化时,也可以触发调试异常。
控制寄存器:虽然不直接称为调试寄存器,但某些控制寄存器(如CR4在x86架构中)包含影响调试行为的位。例如,它们可以控制是否启用调试寄存器,以及调试异常的处理方式。
性能监视计数器(PMC):虽然它们主要用于性能分析而非传统意义上的调试,但PMC也可以被视为一种广义的调试工具,因为它们允许开发者监视和测量CPU的各种性能指标。















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









