start:
.type start,#function .rept 8 mov r0, r0 @ 空语句 .endr b 1f /*魔数,和uboot的魔数相对应*/ .word 0x016f2818 @ Magic numbers to help the loader .word start @ absolute load/run zImage address .word _edata @ zImage end address1: mov r7, r1 @ save architecture ID mov r8, r2 @ save atags pointer#ifndef __ARM_ARCH_2__ ......#else /*关中断*/ teqp pc, #0x0c000003 @ turn off interrupts #endif /* * Note that some cache flushing and other stuff may * be needed here - is there an Angel SWI call for this? */ /* * some architecture specific code can be inserted * by the linker here, but it should preserve r7, r8, and r9. */ .text /* * LC0标签在下面定义,这里把LC0的地址装载到r0,和ldr不同,adr不需要考虑偏移 * 下面ldmia命令把r0(LC0)的内容依次赋给r1,r2等寄存器,对应关系看下面LC0标签 */ adr r0, LC0 ARM( ldmia r0, {r1, r2, r3, r4, r5, r6, r11, ip, sp}) THUMB( ldmia r0, {r1, r2, r3, r4, r5, r6, r11, ip} ) THUMB( ldr sp, [r0, #32] ) /*这里 r0 = r0 - r1 并更新 N、Z、C 和 V 标记*/ subs r0, r0, r1 @ calculate the delta offset @ if delta is zero, we are @ 如果运行当前运行地址和链接地址相等,则不需进行重定位。直接清除bss段 beq not_relocated @ running at the address we - ......
not_relocated:
mov r0, #0 /* r2:bbs开始位置 * r3: bbs结束位置 * str命令: STR Rd, [Rbase], Rindex 存储 Rd 到 Rbase 所包含的有效地址。把 Rbase- * + Rindex 所合成的有效地址写回 Rbase。
- * 下面4句str命令将清空 bss 32个字节 ,r2 累加 32
* */1: str r0, [r2], #4 @ clear bss r2+=4 str r0, [r2], #4 @ clear bss r2+=4 str r0, [r2], #4 @ clear bss r2+=4 str r0, [r2], #4 @ clear bss r2+=4 cmp r2, r3 @ 判断是否到bss的结束位置, blo 1b @ 若不是,继续清空 /* * The C runtime environment should now be setup * sufficiently. Turn the cache on, set up some * pointers, and start decompressing. */ bl cache_on-
- /*r1、r2作为参数传给decompress_kernel */
mov r1, sp @ malloc space above stack add r2, sp, #0x10000 @ 64k max 分配一段解压函数需要的内存缓冲 sp 栈指针,/* * Check to see if we will overwrite ourselves. * r4 = final kernel address 最终的内核开始地址,就是解压后的地址 * r5 = start of this image 解压前的映像开始地址 * r6 = size of decompressed image 解压前的映像大小 * r2 = end of malloc space (and therefore this image) * We basically want: * r4 >= r2 -> OK * r4 + image length <= r5 -> OK * 内核映像解压后不会超过解压前的4倍大小- * 调用decompress_kernel前,要准备4个参数:r0 (解压后的内核开始位置),r1(动态内存开始位置)
- * r2(动态内存结束位置),r3(结构ID))
*/ cmp r4, r2 @ r4为内核执行地址,此时为0X50008000,r2此时为用户栈顶, @ 即解压函数所需内存缓冲的开始处 bhs wont_overwrite add r0, r4, r6 cmp r0, r5 bls wont_overwrite mov r5, r2 @ decompress after malloc space mov r0, r5 mov r3, r7 bl decompress_kernel add r0, r0, #127 + 128 @ alignment + stack bic r0, r0, #127 @ align the kernel length/* * r0 = decompressed kernel length * r1-r3 = unused * r4 = kernel execution address * r5 = decompressed kernel start * r7 = architecture ID * r8 = atags pointer * r9-r12,r14 = corrupted */ add r1, r5, r0 @ end of decompressed kernel adr r2, reloc_start ldr r3, LC1 add r3, r2, r31: ldmia r2!, {r9 - r12, r14} @ copy relocation code stmia r1!, {r9 - r12, r14} ldmia r2!, {r9 - r12, r14} stmia r1!, {r9 - r12, r14} cmp r2, r3 blo 1b mov sp, r1 add sp, sp, #128 @ relocate the stack bl cache_clean_flush ARM( add pc, r5, r0 ) @ call relocation code THUMB( add r12, r5, r0 ) THUMB( mov pc, r12 ) @ call relocation code/* * We're not in danger of overwriting ourselves. Do this the simple way. * * r4 = kernel execution address * r7 = architecture ID */
wont_overwrite:
mov r0, r4 @ 解压后的内核开始位置 mov r3, r7 @ 结构ID bl decompress_kernel @ 这个是跳转到arch/arm/boot/compressed/misc.c的- @ decompress_kernel 函数
b call_kernel @ 解压完毕调用这个 .align 2 .type LC0, #object
LC0:
.word LC0 @ r1 .word __bss_start @ r2 .word _end @ r3 .word zreladdr @ r4 .word _start @ r5 .word _image_size @ r6 .word _got_start @ r11 .word _got_end @ ip .word user_stack+4096 @ sp
LC1:
.word reloc_end - reloc_start .size LC0, . - LC0 ....../* * Turn on the cache. We need to setup some page tables so that we * can have both the I and D caches on. * * We place the page tables 16k down from the kernel execution address, * and we hope that nothing else is using it. If we're using it, we * will go pop! * * On entry, * r4 = kernel execution address * r7 = architecture number * r8 = atags pointer * r9 = run-time address of "start" (???) * On exit, * r1, r2, r3, r9, r10, r12 corrupted * This routine must preserve: * r4, r5, r6, r7, r8 */ .align 5
cache_on:
mov r3, #8 @ cache_on function b call_cache_fn ....../* * Here follow the relocatable cache support functions for the * various processors. This is a generic hook for locating an * entry and jumping to an instruction at the specified offset * from the start of the block. Please note this is all position * independent code. * * r1 = corrupted * r2 = corrupted * r3 = block offset value和mask各占了4byte, * 所以在cache_on标签处被赋值为8, * 用于偏移到函数跳转的位置,具体看代码 * r9 = corrupted * r12 = corrupted */
call_cache_fn:
adr r12, proc_types#ifdef CONFIG_CPU_CP15 mrc p15, 0, r9, c0, c0 @ get processor ID #else ldr r9, =CONFIG_PROCESSOR_ID#endif /*上面找到processor ID放入 r9 , 下面标号1的代码循环调用,在proc_types中 查找和processor ID匹配的cache函数,找到后即调用 */1: ldr r1, [r12, #0] @ get value ldr r2, [r12, #4] @ get mask eor r1, r1, r9 @ (real ^ match) tst r1, r2 @ & mask /*若eq(匹配成功),跳到cache函数*/ ARM( addeq pc, r12, r3 ) @ call cache function THUMB( addeq r12, r3 ) THUMB( moveq pc, r12 ) @ call cache function add r12, r12, #4*5 b 1b @ proc_types 是一个列表,要一个一个匹配,跳回标号1,匹配下一个/* * Table for cache operations. This is basically: * - CPU ID match * - CPU ID mask * - 'cache on' method instruction * - 'cache off' method instruction * - 'cache flush' method instruction * * We match an entry using: ((real_id ^ match) & mask) == 0 * * Writethrough caches generally only need 'on' and 'off' * methods. Writeback caches _must_ have the flush method * defined. */ .align 2 .type proc_types,#object
proc_types:
.word 0x41560600 @ ARM6/610 .word 0xffffffe0 W(b) __arm6_mmu_cache_off @ works, but slow W(b) __arm6_mmu_cache_off mov pc, lr ...... ... @ ARM7/710 mov pc, lr ... @ ARM720T (writethrough) mov pc, lr ......这里忽略一些项 @ These match on the architecture ID @ 这个是匹配ARMv4T的,如ARM920T的s3c2440等等 .word 0x00020000 @ ARMv4T .word 0x000f0000 W(b) __armv4_mmu_cache_on W(b) __armv4_mmu_cache_off W(b) __armv4_mmu_cache_flush ......这里忽略一些项 /*目前我使用S5PV210是cortexA8的cpu,v7架构,匹配这个 上面的语句addeq pc, r12, r3将跳转到__armv7_mmu_cache_on, 因为r3事先被赋值为8。 */ .word 0x000f0000 @ new CPU Id 4 字节 .word 0x000f0000 @ 4 字节 W(b) __armv7_mmu_cache_on @ r12 偏移 r3 后,是这里 W(b) __armv7_mmu_cache_off @ 在内核解压完毕,r3会被赋值为12,即调用这个 W(b) __armv7_mmu_cache_flush @ 在内核解压完毕,r3会被赋值为16,即调用这个 .word 0 @ unrecognised type .word 0 mov pc, lr ......
__setup_mmu:
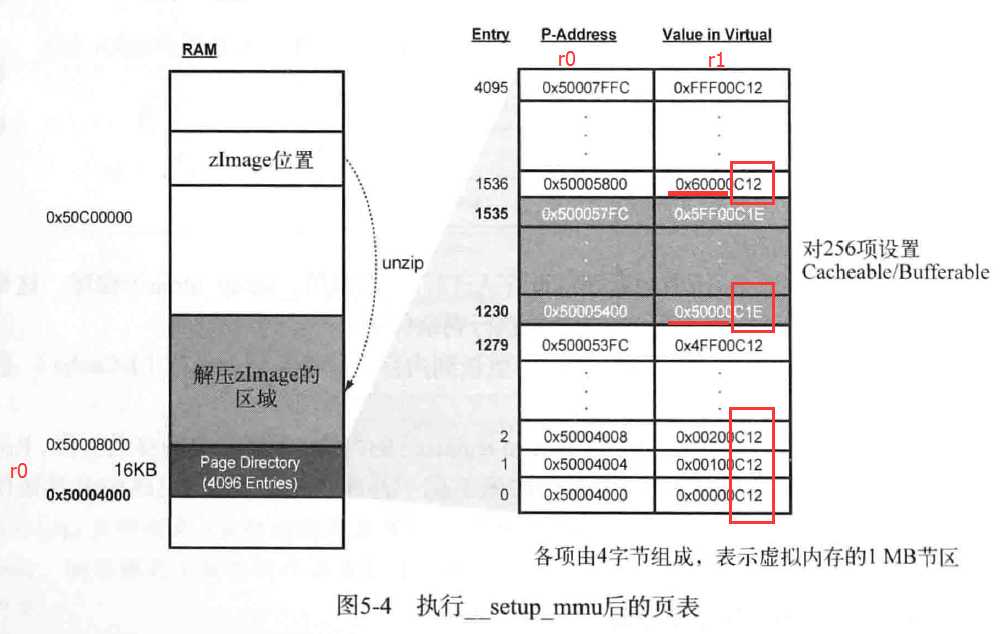
sub r3, r4, #16384 @ Page directory size 16384 是16K- /*上面r4是zreladdr 内核执行地址*/
bic r3, r3, #0xff @ Align the pointer 16K对齐 bic r3, r3, #0x3f00 /*为了容易理解注释,这里假设对齐后 r3 = 0x50004000*/ /* * Initialise the page tables, turning on the cacheable and bufferable * bits for the RAM area only. */ mov r0, r3 @ r0 = 0x50004000 mov r9, r0, lsr #18 @ r0 先 lsr(逻辑右移)18位,再mov给r9 mov r9, r9, lsl #18 @ r9 先 lsl(逻辑左移)18位,再mov给r9 = 0x50000000 @ start of RAM add r10, r9, #0x10000000 @ a reasonable RAM size r10 = 0x60000000 /*上面得到r9为256M对齐的地址,作为RAM的开始地址,r10作为RAM的结束地址*/ /* r9 = 0x50004000 r10 = 0x50008000*/
mov r1, #0x12 @ r1 = 0b 0000 0000 0001 0010 orr r1, r1, #3 << 10 @ r1 = 0b 0000 1100 0001 0010 = 0xC12 add r2, r3, #16384 @ r2 = 0x 5000 8000 /*下面一个循环,把虚拟空间的256MB映射的页表项 设置 缓存和写缓存*/
1: cmp r1, r9 @ if virt > start of RAM orrhs r1, r1, #0x0c @ set cacheable, bufferable cmp r1, r10 @ if virt > end of RAM bichs r1, r1, #0x0c @ clear cacheable, bufferable str r1, [r0], #4 @ 1:1 mapping add r1, r1, #1048576 @ 判断下一个 1M 的节区 teq r0, r2 bne 1b
for(r0=0x50004000,r1=0xc12; r0!=0x50008000; r0+=4,r1+=0x100000)
{
if(r1 > 0x50000000)
r1 = r1 or 0x0c; // 0xC12 -> 0xC1E 第2、3个bit为1,即set cacheable, bufferable
if(r1 > 0x60000000)
r1 = r1 xor 0x0c; // 0xC1E -> 0xC12 这样,从0x50000000到0x60000000的虚拟地址为cacheable, bufferable
*r0 = r1; // 把虚拟地址值直接写入到对应的页表物理空间
}
/* * If ever we are running from Flash, then we surely want the cache * to be enabled also for our execution instance... We map 2MB of it * so there is no map overlap problem for up to 1 MB compressed kernel. * If the execution is in RAM then we would only be duplicating the above. */ mov r1, #0x1e orr r1, r1, #3 << 10 mov r2, pc, lsr #20 orr r1, r1, r2, lsl #20 add r0, r3, r2, lsl #2 str r1, [r0], #4 add r1, r1, #1048576 str r1, [r0] mov pc, lrENDPROC(__setup_mmu)
__armv4_mmu_cache_on:
mov r12, lr @ 保存返回地址到r12,因为下面调用bl __setup_mm @ 时会将返回地址lr更新掉#ifdef CONFIG_MMU bl __setup_mmu mov r0, #0 /* 利用cp15将所有写缓冲的内容更新到内存,并清除指令缓存I-Cache 和数据缓存D-Cache、TLB等 读取CP15的控制寄存器内容,设置指令缓存激活位、RoundRobin缓存交替 策略激活位。这部分参考ARM Linux内核源码剖析 mcr p15, 0, r0, c7, c10, 4 @ drain write buffer mcr p15, 0, r0, c8, c7, 0 @ flush I,D TLBs mrc p15, 0, r0, c1, c0, 0 @ read control reg orr r0, r0, #0x5000 @ I-cache enable, RR cache replacement orr r0, r0, #0x0030#ifdef CONFIG_CPU_ENDIAN_BE8 orr r0, r0, #1 << 25 @ big-endian page tables#endif /*__common_mmu_cache_on子程序使用了上面变更的域设置和“指令缓存”激活 、缓存循环交替策略。同时将页目录的起始地址值存入CP15专用寄存器 */ bl __common_mmu_cache_on @ 清除指令缓存、数据缓存、TLB mov r0, #0 mcr p15, 0, r0, c8, c7, 0 @ flush I,D TLBs#endif mov pc, r12 @返回
__armv7_mmu_cache_on:
mov r12, lr#ifdef CONFIG_MMU mrc p15, 0, r11, c0, c1, 4 @ read ID_MMFR0 tst r11, #0xf @ VMSA blne __setup_mmu mov r0, #0 mcr p15, 0, r0, c7, c10, 4 @ drain write buffer tst r11, #0xf @ VMSA mcrne p15, 0, r0, c8, c7, 0 @ flush I,D TLBs#endif mrc p15, 0, r0, c1, c0, 0 @ read control reg orr r0, r0, #0x5000 @ I-cache enable, RR cache replacement orr r0, r0, #0x003c @ write buffer#ifdef CONFIG_MMU#ifdef CONFIG_CPU_ENDIAN_BE8 orr r0, r0, #1 << 25 @ big-endian page tables#endif orrne r0, r0, #1 @ MMU enabled movne r1, #-1 mcrne p15, 0, r3, c2, c0, 0 @ load page table pointer mcrne p15, 0, r1, c3, c0, 0 @ load domain access control#endif mcr p15, 0, r0, c1, c0, 0 @ load control register mrc p15, 0, r0, c1, c0, 0 @ and read it back mov r0, #0 mcr p15, 0, r0, c7, c5, 4 @ ISB mov pc, r12 ......
__common_mmu_cache_on:
#ifndef CONFIG_THUMB2_KERNEL#ifndef DEBUG orr r0, r0, #0x000d @ Write buffer, mmu#endif mov r1, #-1 mcr p15, 0, r3, c2, c0, 0 @ load page table pointer mcr p15, 0, r1, c3, c0, 0 @ load domain access control b 1f .align 5 @ cache line aligned1: mcr p15, 0, r0, c1, c0, 0 @ load control register mrc p15, 0, r0, c1, c0, 0 @ and read it back to sub pc, lr, r0, lsr #32 @ properly flush pipeline#endif
























 741
741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









