







基于索引统计数据的成本
index dive
有时候使用索引执行查询时会有许多单点区间,比如使用IN语句就很容易产生非常多的单点区间,比如下边这个查询(下边查询语句中的…表示还有很多参数):
SELECT * FROM order_exp WHERE order_no IN ('aa1', 'aa2', 'aa3', ... , 'zzz');
很显然,这个查询可能使用到的索引就是idx_order_no,由于这个索引并不是唯一二级索引,所以并不能确定一个单点区间对应的二级索引记录的条数有多少,需要我们去计算。就是先获取索引对应的B+树的区间最左记录和区间最右记录,然后再计算这两条记录之间有多少记录(记录条数少的时候可以做到精确计算,多的时候只能估算)。MySQL把这种通过直接访问索引对应的B+树来计算某个范围区间对应的索引记录条数的方式称之为index dive。
有零星几个单点区间的话,使用index dive的方式去计算这些单点区间对应的记录数也不是什么问题,如果IN语句里20000个参数怎么办?这就意味着MySQL的查询优化器为了计算这些单点区间对应的索引记录条数,要进行20000次index dive操作,这性能损耗就很大,搞不好计算这些单点区间对应的索引记录条数的成本比直接全表扫描的成本都大了。MySQL考虑到了这种情况,所以提供了一个系统变量eq_range_index_dive_limit,我们看一下在MySQL 5.7.21中这个系统变量的默认值:
show variables like '%dive%';
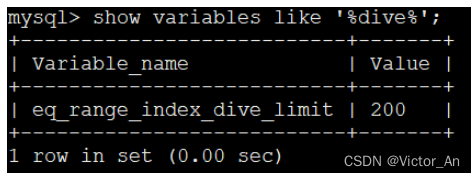
也就是说如果我们的IN语句中的参数个数小于200个的话,将使用index dive的方式计算各个单点区间对应的记录条数,如果大于或等于200个的话,可就不能使用index dive了,要使用所谓的索引统计数据来进行估算。怎么个估算法?像会为每个表维护一份统计数据一样,MySQL也会为表中的每一个索引维护一份统计数据,查看某个表中索引的统计数据可以使用SHOW INDEX FROM 表名的语法,比如我们查看一下order_exp的各个索引的统计数据可以这么写
show index from order_exp;















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









