









PreparedStatement 对象
在上一篇介绍中,SQL语句的执行是通过 Statement 对象实现的。Statement对象每次执行SQL语句时,都会对其进行编译。当相同的SQL语句执行多次是,Statement对象就会使数据库频繁编译相同的SQL语句,从而降低数据库的访问效率。 为了解决上述问题,Statement提供了一个子类 PreparedStatement 对象可以对SQL语句进行预编译。也就是说,当相同的SQL语句在此执行时,数据库只需要使用缓冲区中的数据,而不需要对SQL语句再次编译,从而有效提高数据的访问效率。我们可以通过下面这个程序,对此作进一步的了解。
package com.rocky.test01;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class Demo1 {
public static void main(String[] args) throws Exception {
Connection conn=null;
PreparedStatement ps=null;
try {
//加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
String url="jdbc:mysql://localhost:3306/test";
String username="root";
String password="root";
//创建应用程序与数据库连接的Connection对象
conn=DriverManager.getConnection(url, username, password);
//执行的SQL语句
String sql="insert into users(name,password,email,birthday) values(?,?,?,?)";
//创建执行SQL语句的PreparedStatement对象
ps =conn.prepareStatement(sql);
ps.setString(1, "zhangsan");
ps.setString(2, "123456");
ps.setString(3, "zhangsan@sina.com");
ps.setString(4, "2017-09-09");
ps.executeUpdate();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}finally{
//释放资源
if(ps !=null){
try {
ps.close();
} catch (Exception e2) {
// TODO: handle exception
}
ps=null;
}
if(conn !=null){
try {
conn.close();
} catch (Exception e2) {
// TODO: handle exception
}
conn =null;
}
}
}
}使用了 PreparedStatement 对象执行SQL语句的步骤。首先通过 Connection 对象的 PreparedStatement() 方法生成 PreparedStatement 对象然后调用 PreparedStatement 对象的 setXxx() 方法,给SQL语句中的参数赋值,最后通过调用 executeUpdate() 方法执行SQL语句。代码运行成功后,会在数据库test的users表中插入数据,进入MySQL,使用select语句查询users表,查询结果如下(下表中的数据,是将代码运行了三次产生的结果)
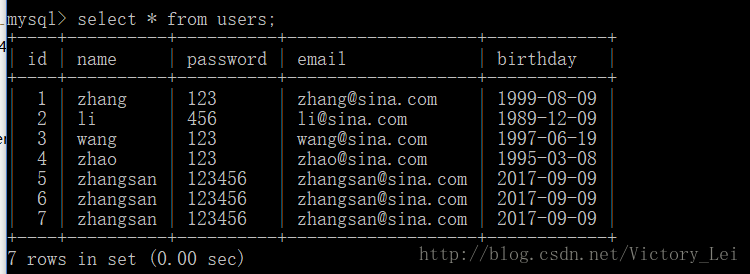
从上述结果中可以看出,users表中多了几条数据,说明PreparedStatement 对象可以成功执行对数据库的操作。
CallableStatement对象
CallableStatement接口是用于执行SQL存储过程的接口,它继承自 PreparedStatement接口,JDBC API提供了一个存储过程SQL转义语法,该语法允许对所有关系型数据库管理系统使用标准方式调用存储过程。此语法有一个包含结果参数的形式和一个不包含结果参数的形式,具体如下所示:
{?=call<procedure-name>[(<arg1>,<arg2>,....)]}
{call<procedure-name>[(<arg1>,<arg2>,...)]}
(1) IN类型:此类型是用于参数从外部传递给存储过程使用。
(2) OUT类型:此类型是存储过程执行过程中的返回值。
(3) IN、OUT混合类型:此类型是参数传入,然后返回。
如果使用结果参数,则必须将其注册为OUT参数。其他参数可用于输入、输出或同时用于二者。参数是根据编号按顺序引用的,第一个参数的编号是1。IN参数值是使用继承自 PreparedStatement 的setXxx() 方法设置的。在执行存储过程之前,必须注册所有的OUT参数的类型;它们的值是在执行后通过此类提供的 getXxx() 方法获取的。 CallableStatement可以返回一个 ResultSet 对象或者多个 ResultSet 对象,多个ResultSet对象是通过继承Statement 来处理的。 接下来,我们可以通过一个简单的代码,来创建一个存储过程。
delimiter //
create procedure add_pro(a int ,b int , out sum int)
begin
set sum=a+b;
end//
delimiter;
上面的程序创建了名为add_pro的存储过程,该存储过程包含三个参数:a、b是默认的参数,即传入参数,而sum使用out修饰,是传出参数。 调用存储过程使用CallableStatement,可以通过Connection的 prepareCall( ) 方法来创建 CallableStatement对象,创建该对象时需要传入调用存储过程的SQL语句,如下:
//使用Connection 来创建一个 CallableStatement对象
CallableStatement cs=conn.prepareCall("{call add_pro(?,?,?)}");
在上述代码中,?占位符可以是IN、OUT或者是INOUT参数,这取决于存储过程中的add_pro。存储过程的参数既有传入参数,也有传出参数。所谓传入参数就是Java程序必须为这些参数传入值,那么可以通过 CallableStatement 的setXxx( )方法为传入的参数设置值;所谓传出参数就是Java程序中可以通过该参数获取存储过程里的值,那么CallableStatement需要调用 registerOutParameter( ) 方法来注册该参数,示例如下:
//注册 CallableStatement 的第三个参数 int类型
cs.regiserOutParameter(3,Types.INTEGER);
经过上面的步骤之后,就可以调用 CallableStatement的 execute( )方法来执行存储过程,执行结束后通过 CallableStatement 对象的 getXxx( int index)方法来获取指定的传出参数的值。我们可以通过下面的这个例子,来进一步的了解:
package com.rocky.test01;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Types;
public class Demo3 {
public static void main(String[] args) throws Exception {
Connection conn=null;
CallableStatement cs=null;
try {
//加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
String url="jdbc:mysql://localhost:3306/test";
String username="root";
String password="root";
//创建应用程序与数据库连接的Connection对象
conn=DriverManager.getConnection(url, username, password);
//执行的SQL语句
String sql="insert into users(name,password,email,birthday) values(?,?,?,?)";
//创建执行SQL语句的CallableStatement对象
cs=conn.prepareCall("call add_pro(?,?,?)");
cs.setInt(1, 4);
cs.setInt(2, 5);
//注册 CallableStatement的第三个参数为int 类型
cs.registerOutParameter(3, Types.INTEGER);
//执行存储过程
cs.execute();
System.out.println("执行的结果是:"+cs.getInt(3));
} catch (ClassNotFoundException e) {e.printStackTrace();
}finally{
//释放资源
if(cs !=null){
try {
cs.close();
} catch (Exception e2) {
// TODO: handle exception
} cs=null;
}
if(conn !=null){
try {
conn.close();
} catch (Exception e2) {
// TODO: handle exception
}conn =null;
}
}
}
}程序执行成功后,会将4和5两个数字相加的结果打印到控制台上,具体的结果如图所示:

ResultSet 对象
ResultSet主要用于存储结果集,并且只能通过next( )方法由前向后逐个获取结果集中的数据。但是,如果想获取结果集中任意位置的数据,则需要在创建 Statement 对象时,设置两个 ResultSet定义的常量,具体的设置方式如下:
Statement st =conn.createStatement(ResultSet.TYPE_SCROLL_INSENITVE,ResultSet.CONCUR_READ_ONLY); ResultSet rs=st.executeQuery(sql); 在上述的方法中,常量ResultSet.TYPE_SCROLL_INSENSITIVE表示结果集可以滚动,常量ResultSet.CONCUR_READ_ONLY表示以只读的形式打开结果集。接下来,我们通过下列代码来对此做进一步的了解,通过示例来看出如何使用ResultSet对象滚动读取结果集中的数据。
package com.rocky.test01;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class Demo4 {
public static void main(String[] args) {
Connection conn=null;
Statement stmt=null;
try {
//注册数据库的驱动
Class.forName("com.mysql.jdbc.Driver");
String url ="jdbc:mysql://localhost:3306/test";
String username="root";
String password="root";
conn =DriverManager.getConnection(url, username, password);
String sql="select * from users";
Statement st=conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_READ_ONLY);
ResultSet rs=st.executeQuery(sql);
System.out.println("第2条数据的name的值:");
//将指针定位到结果集中第2行的数据
rs.absolute(2);
System.out.println(rs.getString("name"));
System.out.println("第1条的数据name的值:");
//将指针定位到结果集中第一行数据之前
rs.beforeFirst();
//将指针向后滚动
rs.next();
System.out.println(rs.getString("name"));
System.out.println("第4条数据的name值为:");
//将指针定位到结果集中最后一条数据之后
rs.afterLast();
//将指针向前滚动
rs.previous();
System.out.println(rs.getString("name"));
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
if (stmt !=null){
try {
stmt.close();
} catch (Exception e2) {
e2.printStackTrace();
}
stmt =null;
}
if(conn !=null){
try {
conn.close();
} catch (Exception e2) {
// TODO: handle exception
}
conn =null;
}
}
}
}
程序的运行结果如下:















 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









