



一、关系数据库与非关系型数据库概述
1、关系型数据库
一个结构化的数据库,创建在关系模型(二维表格模型)基础上
一般面向于记录
SQL 语句(标准数据查询语言)就是一种基于关系型数据库的语言
用于执行对关系型数据库中数据的检索和操作。
主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2 等。
2、非关系型数据库
NoSQL(NoSQL = Not Only SQL ),意思是“不仅仅是 SQL”,是非关系型数据库的总称。
除了主流的关系型数据库外的数据库,都认为是非关系型。
主流的 NoSQL 数据库有 Redis、MongBD、Hbase、CouhDB 等。
3、关系数据库与非关系型数据库区别
(1)数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据。
与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。
你的数据及其特性是选择数据存储和提取方式的首要影响因素。
(2)扩展方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多个表,这都需要通过提高计算机性能来客服。虽然SQL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限。
而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
(3)对事务性的支持不同
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
总结:
关系型数据库:
实例–>数据库–>表(table)–>记录行(row)、数据字段(column)
非关系型数据库:
实例–>数据库–>集合(collection)–>键值对(key-value)
非关系型数据库不需要手动建数据库和集合(表)。
二、Redis概述
1、Redis简介 端口号:TCP/6379
Redis 是一个开源的、使用 C 语言编写的 NoSQL 数据库。
Redis 基于内存运行并支持持久化,采用key-value(键值对)的存储形式,是目前分布式架构中不可或缺的一环。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。
若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;
若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力
所以在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。
若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。
若 CPU 资源比较紧张,采用单进程即可。
2、Redis 优点
具有极高的数据读写速度:数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
支持丰富的数据类型:支持 key-value、Strings、Lists、Hashes、Sets 及 Ordered Sets 等数据类型操作。
支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
原子性:Redis 所有操作都是原子性的。
支持数据备份:即 master-salve 模式的数据备份。
3、Redis使用场景
Redis作为基于内存运行的数据库,缓存是其最常应用的场景之一。除此之外,Redis常见应用场景还包括获取最新N个数据的操作、排行榜类应用、计数器应用、存储关系、实时分析系统、日志记录。
4.Redis 为什么那么快?
1.redis是基于内存运行,数据的读写都是在内存中完成的
2.数据结构简单,可以直接使用 键值对 的方式存储数据
3.数据读写采用单线程模型,避免了多线程切换带来的CPU性能损耗,同时也不用考虑各种锁的影响
4.采用IO多路复用模型,非阻塞IO可以使网络线程处理更多的网络连接请求,提高了网络并发能力
5.数据类型:五大基础数据类型
- string(字符串)
- list(列表)
- hash(哈希/散列)
- set(集合/无序集合)
- zset/sorted set(有序集合)
- Redis 命令工具
redis性能压测工具:
redis-benchmark -h <redis服务器地址> -p <redis端口> -a <redis密码> -c <并发连接数> -n <总请求数> -d <请求的数据大小> -t <测试的命令列表> -q
redis命令行客户端工具:
redis-cli -h <redis服务器地址> -p <redis端口> -a <redis密码> [命令]
redis-server 用于启动 Redis 的工具
redis-benchmark 用于检测 Redis 在本机的运行效率
redis-check-aof 修复 AOF 持久化文件
redis-check-rdb 修复 RDB 持久化文件
redis-cli Redis命令行工具
命令:
1.redis-cli 命令行工具
语法:redis-cli -h host -p port -a password
-h 指定远程主机
-p 指定 Redis 服务的端口号
-a 指定密码,未设置数据库密码可以省略-a 选项
若不添加任何选项表示,则使用 127.0.0.1:6379 连接本机上的 Redis 数据库
例:
redis-cli -h 192.168.19.10 -p 6379
#此时无密码,不需要-a直接登陆
2.redis-benchmark 测试工具
基本的测试语法:redis-benchmark [选项] [选项值]。
-h 指定服务器主机名。
-p 指定服务器端口。
-s 指定服务器 socket
-c 指定并发连接数。
-n 指定请求数。
-d 以字节的形式指定 SET/GET 值的数据大小。
-k 1=keep alive 0=reconnect 。
-r SET/GET/INCR 使用随机 key, SADD 使用随机值。
-P 通过管道传输请求。
-q 强制退出 redis。仅显示 query/sec 值。
--csv 以 CSV 格式输出。
-l 生成循环,永久执行测试。
-t 仅运行以逗号分隔的测试命令列表。
-I Idle 模式。仅打开 N 个 idle 连接并等待。
向 IP 地址为 192.168.19.10、端口为 6379 的 Redis 服务器发送 100 个并发连接与 100000 个请求测试性能
redis-benchmark -h 192.168.19.10 -p 6379 -c 100 -n 100000
Redis 数据库常用命令
(1)set/get 存放/获取数据
set 存放数据,命令格式为 set key value
get 获取数据,命令格式为 get key
例:
redis-cli -p 6379
set name zhangsan
get name
(2)keys 取值 : keys 命令可以取符合规则的键值列表,通常情况可以结合*、?等选项来使用
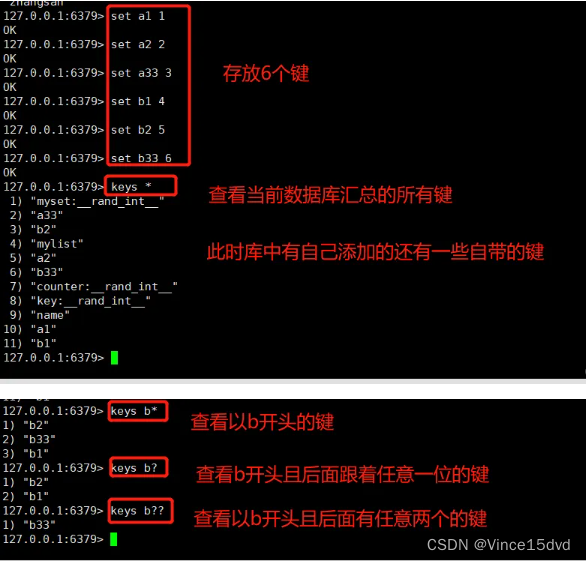
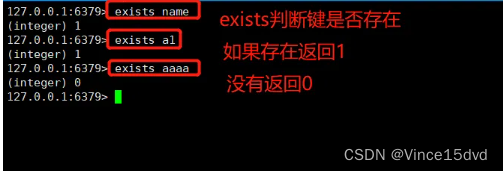
(3)exists 判断值是否存在
exists 命令可以判断键值是否存在。
exists name
exists aaaa
(4)del 删除key
del 命令可以删除当前数据库的指定 key。
keys *
del name
keys *
(5)type 获取值的类型
type 命令可以获取 key 对应的 value 值类型
type a2
Redis 多数据库常用命令
(1)多数据库间切换
命令格式:select 序号
使用 redis-cli 连接 Redis 数据库后,默认使用的是序号为 0 的数据库。
127.0.0.1:6379> select 10 #切换至序号为 10 的数据库
127.0.0.1:6379[10]> select 15 #切换至序号为 15 的数据库
127.0.0.1:6379[15]> select 0 #切换至序号为 0 的数据库
string类型操作:(计数器)
set 键 值 #添加
get 键 #查询
mset 键1 值1 键2 值2 #批量添加
mget 键1 键2 #批量查询
list类型操作:(消息队列)
lpush 键 值1 值2 .... #从左边开始插入元素
rpush 键 值1 值2 .... #从右边开始插入元素
lrange 键 起始位置 终止位置 #起始位置 0表示左边开始的第一个元素,终止位置 -1表示到最后一个元素
hash类型操作:(存储对象描述)
hset 键 字段 值
hmset 键 字段1 值1 字段2 值2 ....
hget 键 字段
hkeys 键 #查看所有的字段
hvals 键 #查看所有字段的值
hdel 键 字段 #删除指定字段
set类型操作:(抽奖,求交集、差集、并集)
sadd 键 值1 值2 .... #元素不能重复
smembers 键 #查看元素,无序的
zset类型操作:(排行榜,热搜)
zadd 键 权重1 值1 权重2 值2 .... #score权重是可以重复的,元素值是不可以重复的
zrange 键 起始位置 终止位置 [withscores] #起始位置 0表示左边开始的第一个元素,终止位置 -1表示到最后一个元素

















 8634
8634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









