







在知道这个之前…原来我一直在暴力for循环。。。。真是不知者无畏啊
暴力匹配就不说了 大家都知道怎么回事 无非是挨个比,如果不匹配了,就像后挪一位再比,以此类推,效率极低。在最坏情况下的时间复杂度相当高

引用于大话数据结构

有如图的T字符串和P字符串
匹配表(Partial Match Table)
也就KMP算法的核心
匹配表的第一步是拆分 分为

而对应的最大公共前后缀长度为

就是将拆分下来的字符串,进行前缀和后缀的匹配
例如a,只有a无法匹配,为0
例如ab,a和b不相同,也无法匹配,为0
aba,前缀a和后缀a相同,为1
abab,前缀ab和后缀ab相同 所以为2 以此类推
下标为0的数组 是不需要最后一段的
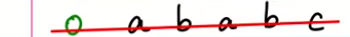
而最大长度表对应的next[i]为
**-1 0 0 1 2 **

即整体右移一位,并附初值为-1 后续也将用next数组进行匹配
然后给P字符串附上下标和next数组值
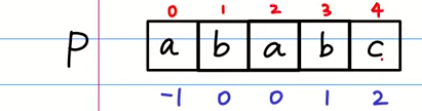
开始匹配

T字符串和P字符串的前三位都是相同的,不做操作,但第四位匹配失败,这时我们要将P字符串的下标值移动到和next数组值相同的值的位置,如本图中就是将1下标挪动到红圈1的位置。

然后我们发现a和b还是不匹配的,和刚才的操作一样,将下标0移动到数组值为0的位置上

以此类推(递归)
附上next数组的公式(来自大话数据结构)

附java实现代码
import java.util.Arrays;
/**
* KMP模式匹配算法
* 返回子串t在主串s中第pos个字符后的位置。若不存在返回-1 要注意i不变,只改变j
*
* @author Yongh
*
*/
public class KMP {
/*
* 返回字符串的next数组
*/
public int[] getNext(String str) {
int length = str.length();
int[] next = new int[length]; //别忘了初始化
int i = 0; //i为后缀的指针
int j = -1; //j为前缀的指针
next[0] = -1;
while (i < length - 1) { // 因为后面有next[i++],所以不是i<length
if (j == -1 || str.charAt(i) == str.charAt(j)) { // j == -1代表前后缀没有相等的部分,i+1位置的next值为0
next[++i] = ++j; //等于前缀的长度
} else {
j = next[j];
}
}
return next;
}
/*
* 返回子串t在主串s中第pos个字符后的位置(包含pos位置)。若不存在返回-1
*/
public int index_KMP(String s, String t, int pos) {
int i = pos; //主串的指针
int j = 0; //子串的指针
int[] next = getNext(t); //获取子串的next数组
while (i < s.length() && j < t.length()) {
if (j == -1 || s.charAt(i) == t.charAt(j)) {
// j==-1说明了子串首位也不匹配,它是由j=next[0]=-1得到的。
i++;
j++;
} else {
j = next[j];
}
}
if (j == t.length())
return i - j;
return -1;
}
public static void main(String[] args) {
KMP aKmp = new KMP();
System.out.println(Arrays.toString(aKmp.getNext("BBC")));
System.out.println(Arrays.toString(aKmp.getNext("ABDABC")));
System.out.println(Arrays.toString(aKmp.getNext("ababaaaba")));
System.out.println(aKmp.index_KMP("goodgoogle", "google", 0));
}
}















 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









