 Python字典dict的内部实现与存储策略
Python字典dict的内部实现与存储策略





 本文深入解析Python字典dict的内部实现,包括PyDictObject的存储策略,使用开放寻址法处理冲突,PyDictEntry的三种状态(Active、Unused、Dummy)及其作用,以及构造和销毁过程。通过理解这些细节,可以更好地了解Python字典的高效运作机制。
本文深入解析Python字典dict的内部实现,包括PyDictObject的存储策略,使用开放寻址法处理冲突,PyDictEntry的三种状态(Active、Unused、Dummy)及其作用,以及构造和销毁过程。通过理解这些细节,可以更好地了解Python字典的高效运作机制。
Python里的dict和C++ STL的map一样,都是映射容器(key->value),但实现原理不同。由于python内部大量使用dict这种结构,效率要求很高,所以Python没有使用STL map的平衡二叉树,而采用哈希表,最低能在O(1)时间内完成搜索。
使用hash就必须解决冲突的问题,dict采用的是开放寻址法。原因我觉得是开放寻址法比拉链法能更好地利用CPU cache,cache命中率较高。
探测函数为 i = (i << 2) + i + perturb + 1; perturb每探测一次就除以2^5。PyDictObject的存储策略
- 使用散列表进行存储
- 使用开放定址法处理冲突
2.1 插入, 发生冲突, 通过二次探测算法, 寻找下一个位置, 直到找到可用位置, 放入(形成一条冲突探测链)
2.2 查找, 需要遍历冲突探测链
2.3 删除, 如果对象在探测链上, 不能直接删除, 否则会破坏整个结构(所以不是真的删)
键值PyDictEntry定义
typedef struct {
Py_ssize_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;说明
- PyDictEntry 用于存储键值对信息
- Py_ssize_t me_hash
存储了me_key计算得到的hash值, 不重复计算

补充:
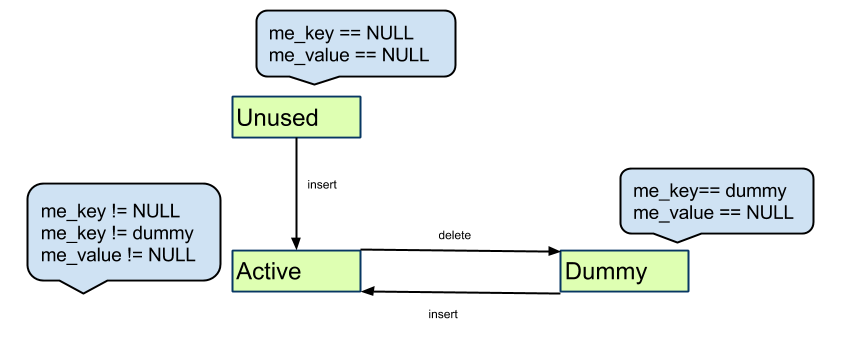
每个entry有三种状态:Active, Unused, Dummy。
Unused:me_key == me_value == NULL,即未使用的空闲状态。
Active:me_key != NULL, me_value != NULL,即该entry已被占用
Dummy:me_key == dummy, me_value == NULL。
哈希探测结束的条件是探测到一个Unused的entry。但是dict操作中必定会有删除操作,如果删除时仅把Active标记成Unused,显然该entry之后的所有entry都不可能被探测到,所以引入了dummy结构。遇到dummy就说明当前entry处于空闲状态,但探测不能结束。这样就解决了删除一个entry之后探测链断裂的问题。
PyDictEntry的三个状态(图片引自-Python源码剖析)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









