






前言
官方文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/empty-search.html
官方文档基于ES 2.x,小部分api已经失效或修改,但大部分是延续使用的
Es学习总结:https://mp.weixin.qq.com/s/V2U5kBqccX3AMoxGRkTXOQ
一.Elasticsearch的知识点和架构
链接:https://www.zhihu.com/question/323811022/answer/981341195
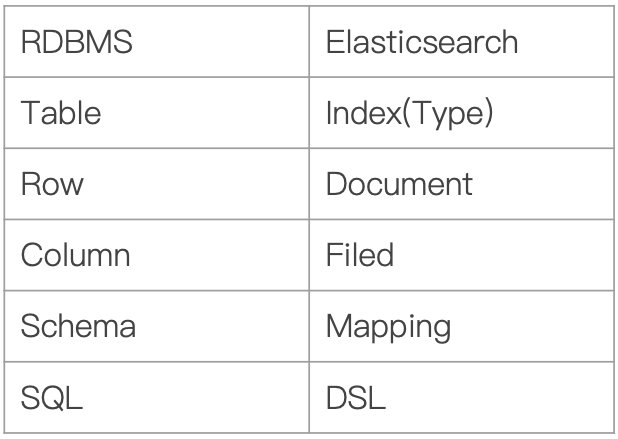
1.ES常见术语
从官网的介绍我们已经知道Elasticsearch是分布式存储的
在讲解Elasticsearch的架构之前,首先我们得了解一下Elasticsearch的一些常见术语。
- Index:Elasticsearch的Index相当于数据库的Table
Type:这个在新的Elasticsearch7.0版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type–有点类似于消息队列一个topic下多个group的概念)- Document:Document相当于数据库的一行记录
- Field:相当于数据库的Column的概念
- Mapping:相当于数据库的Schema的概念
- DSL:相当于数据库的SQL(给我们读取Elasticsearch数据的API)
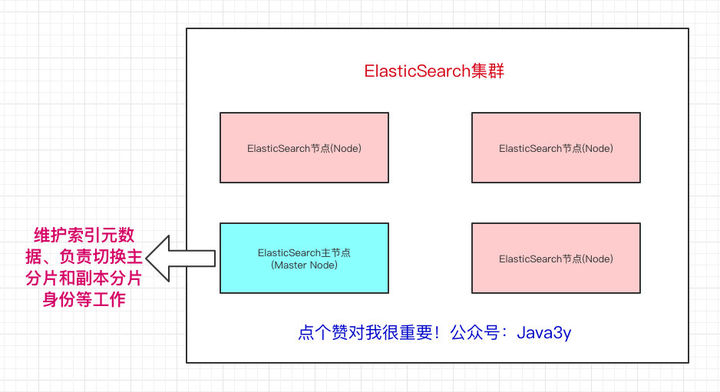
2.ES架构
在众多的节点中,其中会有一个Master Node,它主要负责维护索引元数据、负责切换主分片和副本分片身份等工作(后面会讲到分片的概念),如果主节点挂了,会选举出一个新的主节点。
从上面我们也已经得知,Elasticsearch最外层的是Index(相当于数据库 表的概念);一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片。
比如现在我集群里边有4个节点,我现在有一个Index,想将这个Index在4个节点上存储,那我们可以设置为4个分片。这4个分片的数据合起来就是Index的数据

为什么要分片?原因也很简单:
- 如果一个Index的数据量太大,只有一个分片,那只会在一个节点上存储,随着数据量的增长,一个节点未必能把一个Index存储下来。
- 多个分片,在写入或查询的时候就可以并行操作(从各个节点中读写数据,提高吞吐量)
现在问题来了,如果某个节点挂了,那部分数据就丢了吗?显然Elasticsearch也会想到这个问题,所以分片会有主分片和副本分片之分(为了实现高可用)
数据写入的时候是写到主分片,副本分片会复制主分片的数据,读取的时候主分片和副本分片都可以读。
Index需要分为多少个分片和副本分片都是可以通过配置设置的
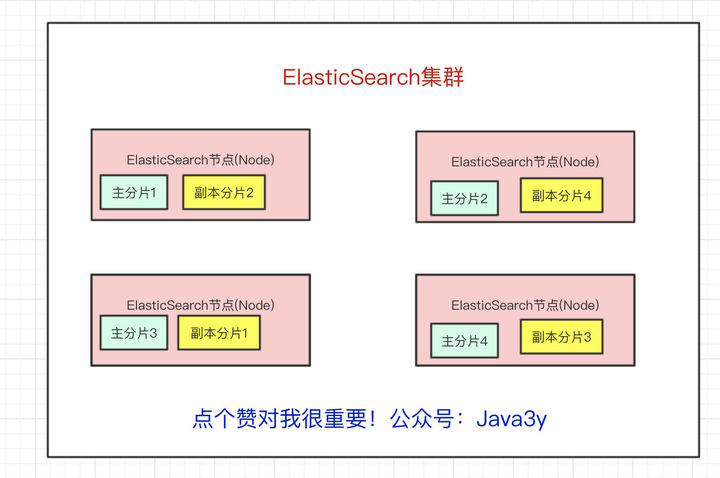
如果某个节点挂了,前面所提高的Master Node就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢。
更多基础可查看链接:https://www.zhihu.com/question/323811022/answer/981341195
3.ElasticSearch与solr的区别与总结
链接:https://www.zhihu.com/question/323811022/answer/2345165058
1.Elasticsearch 简介
Elasticsearch 是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入 实时搜索(search-asyou-type)和 搜索纠错(did-you-mean)等搜索建议功能。
英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
Github使用Elasticsearch检索1300亿行的代码。
但是 Elasticsearch 不仅用于大型企业,它还让像DataDog 以及 Klout 这样的创业公司将最初的想法变成可扩展的解决方案。
Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据 。
Elasticsearch 是一个基于 Apache Lucene 的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的
Elasticsearch也使用Java开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单
2.Solr 简介
Solr 是 Apache 下的一个顶级开源项目,采用Java开发,它是基于 Lucene 的全文搜索服务器。Solr提供了比 Lucene 更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat 等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据 xml 文档添加、删除、更新索引。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr是基于 lucene 开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
3.Lucene简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene是一个全文检索引擎的架构。那什么是全文搜索引擎?
全文搜索引擎是名副其实的搜索引擎,国外具代表性的有Google、Fast/AllTheWeb、AltaVista、Inktomi、Teoma、WiseNut等,国内著名的有百度(Baidu)。它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,因此他们是真正的搜索引擎。
从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中调用,如上面提到的7家引擎;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如 Lycos 引擎。
4.Elasticsearch和Solr比较




5.ElasticSearch vs Solr 总结
1、es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
3、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式
4、Solr 官方提供的功能更多,而** Elasticsearch 本身更注重于核心功能**,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
6、Solr 比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch 相对开发维护者较少,更新太快,学习使用成本较高。
4.ES的mapping配置详解
转载自:https://blog.csdn.net/liuerchong/article/details/123728638
转载自:https://blog.csdn.net/qq_34348049/article/details/115305675
1.什么是mapping
1. Mapping 类似数据库中的Schema的定义(DDL),作用如下:
1. 定义索引中字段的名称
2. 定义字段的数据类型,例如字符串,数字,布尔
3. 字段,倒排索引的相关配置,是否分词
2. Mapping会把JSON文档映射成Lucene所需要的扁平格式
3. 一个Mapping属于一个索引的Type:
1. 每个文档都属于一个索引的Type
2. 一个Type有一个Mapping定义
3. 7.0开始,不需要在Mapping定义中指定Type信息
2.mapping的基本格式
{
"mappings":{
"_doc":{
"_all":{
"enabled":false #默认情况,ElasticSarch自动使用_all所有的文档的域都会被加到_all中进行索引。可以使用"_all" : {"enabled":false} 开关禁用它。如果某个域不希望被加到_all中,可以使用"include_in_all":false关闭
},
"properties":{
"uuid":{
"type":"text",
"copy_to":"_search_all", #对应_search_all字段,可以对其进行全文检索
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150 #ignore_above 默认值是256,当字段文本的长度大于指定值时,不做倒排索引。
}
}
},
"name":{
"type":"text",
"copy_to":"_search_all",
"analyzer":"ik_max_word", # ik_max_word 插件会最细粒度分词
"search_analyzer":"ik_smart", # ik_smart 粗粒度分词
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150
}
}
},
"dt_from_explode_time":{
"type":"date",
"copy_to":"_search_all",
"format":"strict_date_optional_time||epoch_millis"
},
"_search_all":{
"type":"text"
}
},
"date_detection":false, #关闭日期自动检测,如果开启,会对于设置为日期格式的字段进行判断
"dynamic_templates":[ #用于自定义在动态添加field的时候自动给field设置的数据类型
{
"strings":{
"match_mapping_type":"string",
"mapping":{
"type":"text",
"copy_to":"_search_all",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150
}
}
}
}
}
]
}
},
"settings":{
"index":{
"number_of_shards":6, #分片数量
"number_of_replicas":1 #副本数量
}
}
}
分词:
按照一般情况来讲,索引分词应该按照最细粒度来分词,搜索分词可按最粗粒度来分词
比如搜索“华为手机”,用户不希望将关键词拆分为华为,手机,那这样各类手机和华为路由器或华为其它产品也能搜索出来所以这块建议搜索分词设置为最粗粒度
3.mapping的参数说明(待学习补充)
字段类型概述
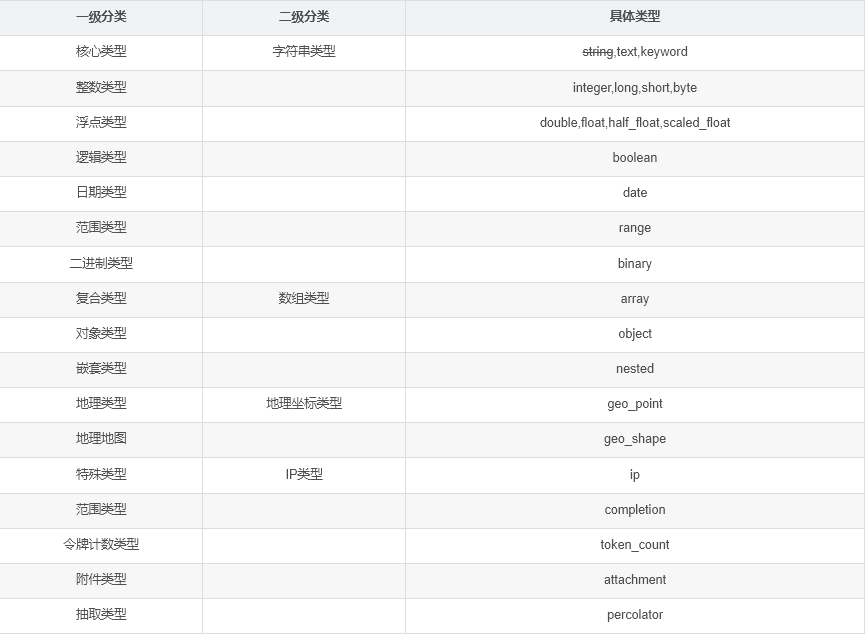
string类型:ELasticsearch 5.X之后的字段类型不再支持string,由text或keyword取代。 如果仍使用string,会给出警告
text取代了string,当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合(termsAggregation除外)
keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到
转载自:https://www.jianshu.com/p/26744eb914a8
ElasticSearch 5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索,keyword通常用于过滤、排序、参与聚合等。关键字不参与分词。
ElasticSearch字符串将默认被同时映射成text和keyword类型,将会自动创建下面的动态映射(dynamic mappings):
这就是造成部分字段还会自动生成一个与之对应的“.keyword”字段的原因。
{
"foo": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
Text 与. keyword的区别
Text:
会分词,然后进行索引
支持模糊、精确查询
不支持聚合
keyword:
不进行分词,直接索引
支持模糊、精确查询
支持聚合
4.Dynamic Mapping动态映射
写入文档的时候,索引不存在,会自动创建索引, 无需手动创建,ES会根据内容推断字段的类型,推断会不准确,可能造成某些功能无法使用,例如 范围查询。
GET /index_name/_mapping
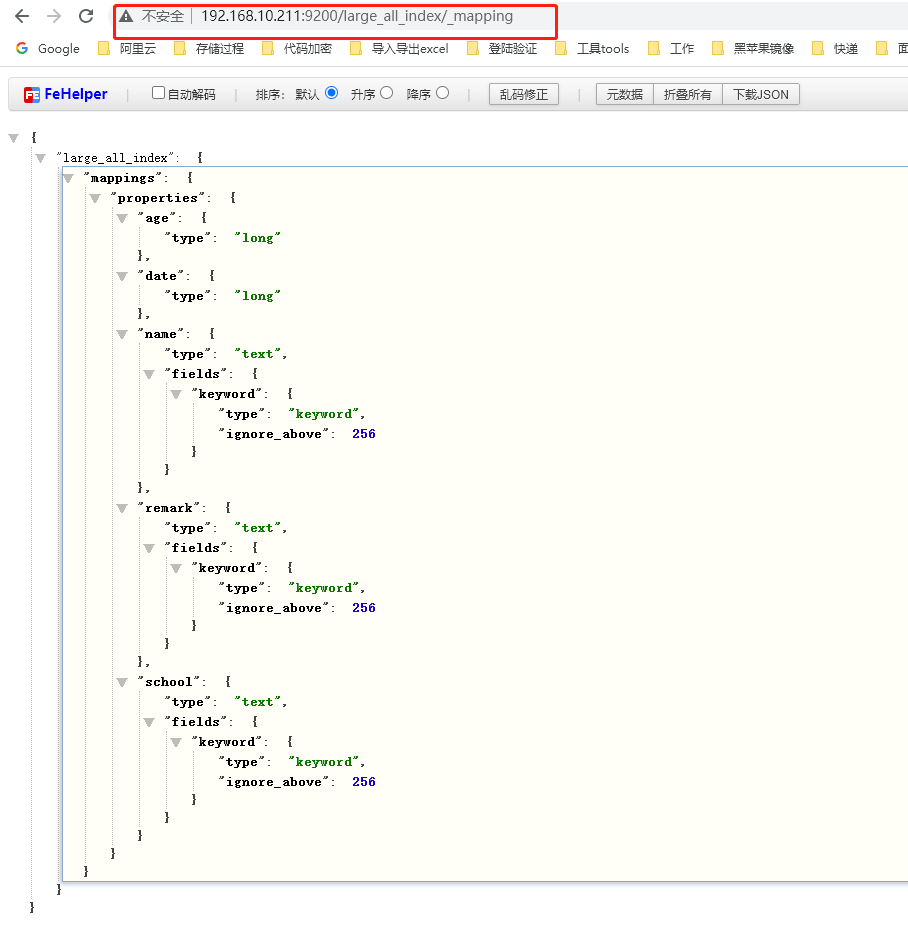
5.修改Mapping的字段类型
在写入文档的时候,有可能当前文档的索引并不存在,就会为我们自动创建索引
DynamicMapping使得我们无需手动定义Mapping字段信息,ES根据文档的信息来推断出文档的类型。
ES推算的字段类型并不完全准确。
当类型设置的不对时,有些功能无法正常运行,比如聚合、分词、范围查询等等。
6.能否更改Mapping的字段类型
1. 新增加字段
1. Dynamic 设为true时,一旦有新增字段的文档写入,Mapping也同时被更新
2. Dynamic 设为false时,Mapping不会被更新,新增字段的数据无法被索引,但是信息会出现在_scoure中
3. Dynamic设置为Stict,文档写入失败
2. 对于已有字段,一旦有数据写入,就不再支持修改字段定义
1. Lucene实现的待排索引,一旦生成后,就不允许修改
3. 如果希望改变字段类型,必须Reindex API,重建索引
原因:
1. 如果修改了字段的数据类型,会导致已被索引的属于无法被搜索
2. 但如果是新增的字段,就不会有这样的影响
7.自定义Mapping的一些建议
1. 可以参考API手册,纯手写
2. 为了减少输入的工作量,减少出错概率,可以依照以下步骤:
1. 创建一个临时的Index,写入一些样本数据
2. 通过访问Mapping API获得该临时文件的动态Mapping定义
3. 修改后用,使用该配置创建你的索引
4. 删除临时索引
5.简单搜索(search)
1. 测试使用的index、mapping及数据准备
PUT example
PUT example/_mapping
{
"properties": {
"id": {
"type": "long"
},
"orderNo": {
"type": "keyword"
},
"buyerId": {
"type": "long"
},
"shopId": {
"type": "long"
},
"shopName": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"tradeStatus": {
"type": "integer"
},
"payStatus": {
"type": "integer"
},
"orderAmount": {
"type": "float"
},
"payAmount": {
"type": "float"
},
"payPlatformOrderNo": {
"type": "keyword"
},
"delivery": {
"properties": {
"receiver": {
"type": "keyword"
},
"phoneNumber": {
"type": "keyword"
},
"address": {
"type": "keyword"
},
"detailedAddress": {
"type": "keyword"
}
}
},
"items": {
"type": "nested",
"properties": {
"id": {
"type": "long"
},
"orderId": {
"type": "long"
},
"goodId": {
"type": "long"
},
"goodName": {
"type": "keyword"
},
"goodPrice": {
"type": "float"
},
"goodNumber": {
"type": "integer"
},
"goodAmount": {
"type": "float"
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"ignore_malformed": true
}
}
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"ignore_malformed": true
},
"deliveryTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"ignore_malformed": false
},
"deliveryAmount": {
"type": "float"
},
"remark": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}
}
}
#bulk插入
POST example/_bulk
{"index": {"_id": 1}}
{"id":1,"orderNo":1136482742505680898,"buyerId":4500,"shopId":9596,"shopName":"小米手机官方旗舰店","tradeStatus":1,"payStatus":1,"orderAmount":4290.90,"payAmount":4280.00,"payPlatformOrderNo":"9b235e16-ffa2-4605-af8c-47bee94d1732","delivery":{"receiver":"张三","phoneNumber":"13279220508","address":"陕西省西安市雁塔区","detailedAddress":"小寨东路91号陕西历史博物馆"},"items":[{"id":123,"orderId":1,"goodId":54,"goodName":"小米CC9Pro","goodPrice":3299.00,"goodNumber":5468,"goodAmount":1,"createTime":"2019-11-11 00:01:18"},{"id":124,"orderId":1,"goodId":55,"goodName":"小米插线板","goodPrice":49.00,"goodNumber":5469,"goodAmount":2,"createTime":"2019-11-11 00:01:18"},{"id":125,"orderId":1,"goodId":56,"goodName":"小米平衡车","goodPrice":1999.00,"goodNumber":5470,"goodAmount":1,"createTime":"2019-11-11 00:01:18"}],"createTime":"2019-11-11 00:01:18","deliveryTime":"2019-11-11 16:30:22","deliveryAmount":20.00,"remark":"尽快发货,谢谢!"}
{"index": {"_id": 2}}
{"id":2,"orderNo":1136482742505656781,"buyerId":4500,"shopId":9500,"shopName":"华为旗舰店","tradeStatus":1,"payStatus":1,"orderAmount":7999.99,"payAmount":6500.00,"payPlatformOrderNo":"9b235e16-ffa2-4605-af8c-47bee94d2134","delivery":{"receiver":"张三","phoneNumber":"13279220508","address":"陕西省西安市雁塔区","detailedAddress":"小寨东路91号陕西历史博物馆"},"items":[{"id":124,"orderId":2,"goodId":1003,"goodName":"华为笔记本","goodPrice":7999.99,"goodNumber":5400,"goodAmount":1,"createTime":"2019-11-11 00:01:18"}],"createTime":"2019-11-11 00:01:18","deliveryTime":"2019-11-12 18:30:22","deliveryAmount":0.00,"remark":"尽快发货,谢谢!"}
{"index": {"_id": 3}}
{"id":3,"orderNo":1136482742505655433,"buyerId":4501,"shopId":8503,"shopName":"无印良品旗舰店","tradeStatus":1,"payStatus":1,"orderAmount":2036.00,"payAmount":2020.00,"payPlatformOrderNo":"9b235e16-ffa2-4605-af8c-47bee94d2300","delivery":{"receiver":"李四","phoneNumber":"13279228888","address":"陕西省西安市长安区","detailedAddress":"西长安街1号大厦"},"items":[{"id":620,"orderId":3,"goodId":8784,"goodName":"柔和洗面奶","goodPrice":79.90,"goodNumber":8780,"goodAmount":1,"createTime":"2019-11-11 00:21:50"},{"id":622,"orderId":3,"goodId":8704,"goodName":"化妆水","goodPrice":109.90,"goodNumber":8580,"goodAmount":2,"createTime":"2019-11-11 00:21:50"}],"createTime":"2019-11-11 00:21:50","deliveryTime":"2019-11-13 17:35:23","deliveryAmount":8.00,"remark":"尽快发货,谢谢!"}
{"index": {"_id": 4}}
{"id":4,"orderNo":1136482742545655633,"buyerId":4521,"shopId":8503,"shopName":"无印良品旗舰店","tradeStatus":1,"payStatus":1,"orderAmount":2036.00,"payAmount":2020.00,"payPlatformOrderNo":"9b235e16-ffa2-4625-af8c-47bea94d2300","delivery":{"receiver":"王五","phoneNumber":"13279228788","address":"陕西省西安市长安区","detailedAddress":"西长安街1号大厦"},"items":[{"id":620,"orderId":3,"goodId":8784,"goodName":"柔和洗面奶","goodPrice":79.90,"goodNumber":8780,"goodAmount":1,"createTime":"2019-11-11 00:21:50"},{"id":622,"orderId":3,"goodId":8704,"goodName":"化妆水","goodPrice":109.90,"goodNumber":8580,"goodAmount":2,"createTime":"2019-11-11 00:21:50"}],"createTime":"2019-11-11 00:21:50","deliveryTime":"2022-04-20 12:50:23","deliveryAmount":8.00,"remark":"尽快发货,谢谢!"}
//空一行
注意:批量插入的body最后得空一行,否则会报错:
The bulk request must be terminated by a newline [\n]
2 .http调用es查询接口
#查询所有
GET example/_search
#带有参数的查询
GET example/_search?
#在索引example和us的索引中搜索
GET example,us/_search
# 在以g或u开头的索引的所有类型中搜索
GET e*,u*/_search
#在索引example和us的索引中搜索
GET example,us/_search
注意点:
当你搜索包含单一索引时,Elasticsearch转发搜索请求到这个索引的主分片或每个分片的复制分片上,然后聚集每个分片的结果。搜索包含多个索引也是同样的方式——只不过或有更多的分片被关联。
关于示例可以跟的参数如下图所示(GET example/_search?)

6.结构化搜索(request body search)(待学习补充)
参考文档:https://www.kancloud.cn/zy598586050/elasticsearch/2423859
请求体的参数是JSON格式。这种JSON必须遵循DSL(domain search language)语法格式。
1. 查询所有
GET example/_search
{
"query": {
"match_all": {}
}
}
2 分页搜索
和SQL使用LIMIT关键字返回只有一页的结果一样,Elasticsearch接受from和size参数:
size: 结果数,默认10
from: 跳过开始的结果数,默认0。可理解成元素开始的索引下标。
例如我们想分页搜索订单的第一页,每页显示2个。
GET example/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
注意点:
应该当心分页太深或者一次请求太多的结果。结果在返回前会被排序。但是记住一个搜索请求常常涉及多个分片。每个分片生成自己排好序的结果,它们接着需要集中起来排序以确保整体排序正确。
在集群系统中深度分页。为了理解为什么深度分页是有问题的,让我们假设在一个有5个主分片的索引中搜索。当我们请求结果的第一页(结果1到10)时,每个分片产生自己最顶端10个结果然后返回它们给请求节点(requesting node),它再排序这所有的50个结果以选出顶端的10个结果。
现在假设我们请求第1000页——结果10001到10010。工作方式都相同,不同的是每个分片都必须产生顶端的10010个结果。然后请求节点排序这50050个结果并丢弃50040个!你可以看到在分布式系统中,排序结果的花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于10000个结果的原因(通常最大的分页数就是100页,比如说京东的评论数等等)。
3.精确值查找term(单条件查找)
term 查询, 可以用它处理数字(numbers)、布尔值(Booleans)、日期(dates)以及文本(text)。
1.term查询数字
在sql中,如果想根据某个商品的价格查找数据,则会使用where,在es的DSL表达式中,term可以起到同样的作用,term会帮助我们查找到精确值。作为起本身单独使用,是简单的。
GET example/_search
{
"query" : {
"term" : {
"delivery.phoneNumber" : 13279228888
}
}
}
"hits": [
{
"_index": "example",
"_type": "_doc",
"_id": "3",
"_score": 0.9808291,
"_source": {...}
}
]
由于delivery.phoneNumber是keyword类型,所以会匹配精确值,以上score为0.9808291,即匹配度。
通常当查找一个精确值的时候,我们不希望对查询进行评分计算。只希望对文档进行包括或排除的计算,所以我们会使用 constant_score 查询以非评分模式来执行 term 查询并以一作为统一评分。
最终组合的结果是一个 constant_score 查询,它包含一个 term 查询:
GET example/_search
{
"query" : {
"constant_score" : { //用 constant_score 将 term 查询转化成为过滤器
"filter" : {
"term" : {
"delivery.phoneNumber" : 13279228888
}
},
//"boost": 1.2 //boost用来改变分值,例如此处boost为1.2,则查询结果_score为1.2,若不存在,则为1
}
}
}
"hits": [
{
"_index": "example",
"_type": "_doc",
"_id": "3",
"_score": 1,
"_source": {...}
}
]
当进行精确值查找时, 我们会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。
2.term查询文本
使用 term 查询匹配字符串和匹配数字一样容易。例如我们需要查找shopName,由于我们查找的shopName的类型有两种
"shopName": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
模糊查询,直接使用shopName字段即可
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"shopName" : "旗舰店"
}
}
}
}
}
精确查询,需要使用shopName.keyword字段
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"shopName.keyword" : "华为旗舰店"
}
}
}
}
}
3.match与term的区别
转载自:https://blog.csdn.net/tclzsn7456/article/details/79956625
match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,而term会直接对关键词进行查找。一般模糊查找的时候,多用match,而精确查找时可以使用term。
举个例子说明一下:
{
"match": { "title": "my cat"}
}
{
"bool": {
"should": [
{ "term": { "title": "my" }},
{ "term": { "title": "cat" }}
]
}
}
match 会将关键词进行分词分成“my”和“cat”,查找时包含其中任一均可被匹配到。
term结合bool使用,不进行分词,但是有2个关键词,并且使用“或”匹配,也就是会匹配关键字一“my”或关键字“cat”,效果和上面的match是相同的。如果要想精确的匹配“my cat”而不匹配“my lovely cat”,则可以如下方式匹配:
{
"bool": {
"should": [
{ "term": { "title": "my cat" }}
]
}
}
以下写法等价:
match的与对应bool的must
{
"match": {
"title": {
"query": "my cat",
"operator": "and"
}
}
}
{
"bool": {
"must": [
{ "term": { "title": "my" }},
{ "term": { "title": "cat" }}
]
}
}
4.match、match_phrase与multi_match区别
转载自:https://blog.csdn.net/benben0729/article/details/87806960
4.组合过滤器(多条件查找)
1.基础应用
我们需要 _bool _(布尔)过滤器。 这是个 复合过滤器(compound filter) ,它可以接受多个其他过滤器作为参数,并将这些过滤器结合成各式各样的布尔(逻辑)组合。
一个 bool 过滤器由三部分组成:
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
}
}
must
所有的语句都 必须(must) 匹配,与 _AND _等价。
filter
过滤条件,与_must_等价
must_not
所有的语句都 不能(must not) 匹配,与 _NOT _等价。
should
至少有一个语句要匹配,与 _OR _等价。
一个 bool 过滤器的每个部分都是可选的(例如,我们可以只有一个 must 语句),而且每个部分内部可以只有一个或一组过滤器。
{
"query":{
"bool" : {
"should" : [ //二选一满足即可
{ "term" : {"id" : 1}},
{ "term" : {"shopName.keyword" : "华为旗舰店"}}
],
"must_not" : {
"term" : {"shopId" : 9510}
}
}
}
}
{
"query":{
"bool" : {
"should" : [
{ "term" : {"id" : 1}},
{ "term" : {"shopName.keyword" : "华为旗舰店"}}
],
"must_not" : {
"bool" : {
"must": {
"term":{"shopId" : 9510}
}
}
}
}
}
}
2._must_与_filter_区别
- must, 返回的文档必须满足must子句的条件,并且参与计算分值
- filter, 返回的文档必须满足filter子句的条件。但是跟must不一样的是,不会计算分值, 并且可以使用缓存
3._filter_比较高效的原理
转载自:https://blog.csdn.net/pony_maggie/article/details/106062284
为了说明filter查询高效的原因,我们需要引入ES的一个概念 _query context_和 filter context。
query context
_query context_关注的是,文档到底有多匹配查询的条件,这个匹配的程度是由相关性分数决定的,分数越高自然就越匹配。所以这种查询除了关注文档是否满足查询条件,还需要额外的计算相关性分数。
filter context
filter context_关注的是,文档是否匹配查询条件,结果只有两个,是和否。没有其它额外的计算。它常用的一个场景就是过滤时间范围。
并且filter context会自动被ES缓存结果,效率进一步提高。
对于bool查询,must使用的就是_query context,而filter使用的就是_filter context_。
5.查找多个精确值
term 查询对于查找单个值非常有用,但通常我们可能想搜索多个值,不需要使用多个 term 查询,我们只要用单个 terms 查询(注意末尾的 s ), terms 查询好比是 term 查询的复数形式(以英语名词的单复数做比)
{
"query":{
"terms" : {
"id" : [1, 3]
}
}
}
与 term 查询一样,也需要将其置入 filter 语句的常量评分查询中使用:
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"id" : [1, 3]
}
}
}
}
}
6.范围查找
Elasticsearch 有 range 查询,可以用它来查找处于某个范围内的文档。
range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:
- gt: > 大于(greater than)
- lt: < 小于(less than)
- gte: >= 大于或等于(greater than or equal to)
- lte: <= 小于或等于(less than or equal to)
1.数据范围
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"id":{
"gt": 1,
"lt": 3
}
}
}
}
}
}
2.日期范围
显式日期查询
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"deliveryTime":{
"gt": "2019-11-11 00:00:00",
"lt": "2019-11-12 00:00:00"
}
}
}
}
}
}
对 日期计算(date math) 进行操作,比方说,如果我们想查找时间戳在过去一小时内的所有文档:
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"deliveryTime":{
"gt": "now-1h"
}
}
}
}
}
}
这个过滤器会一直查找时间戳在过去一个小时内的所有文档,让过滤器作为一个时间 滑动窗口(sliding window) 来过滤文档。
日期计算还可以被应用到某个具体的时间,并非只能是一个像 now 这样的占位符。只要在某个日期后加上一个双管符号 (||) 并紧跟一个日期数学表达式就能做到:
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"deliveryTime":{
"gt" : "2019-11-11 00:00:00",
"lt" : "2019-11-11 00:00:00||+1M" //早于 2014 年 1 月 1 日加 1 月(2014 年 2 月 1 日 零时)
}
}
}
}
}
}
日期计算是 日历相关(calendar aware) 的,所以它不仅知道每月的具体天数,还知道某年的总天数(闰年)等信息。
3.字符串范围
range 查询同样可以处理字符串字段,字符串范围可采用 字典顺序(lexicographically) 或字母顺序(alphabetically)。例如,下面这些字符串是采用字典序(lexicographically)排序的:
5, 50, 6, B, C, a, ab, abb, abc, b
如果我们想查找从 a 到 b (不包含)的字符串,同样可以使用 range 查询语法:
"range" : {
"title" : {
"gte" : "a",
"lt" : "b"
}
}
二.docker安装ES(单机版)
转载自:https://blog.csdn.net/qq_40942490/article/details/111594267
1.设置max_map_count
不然启动es会启动不起来(因虚拟内存太少导致)
cat /proc/sys/vm/max_map_count
sysctl -w vm.max_map_count=262144
2.下载镜像并运行
#拉取镜像
docker pull elasticsearch:7.7.0
#启动镜像
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 elasticsearch:7.7.0
--name表示镜像启动后的容器名称
-d: 后台运行容器,并返回容器ID;
-e: 指定容器内的环境变量
-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
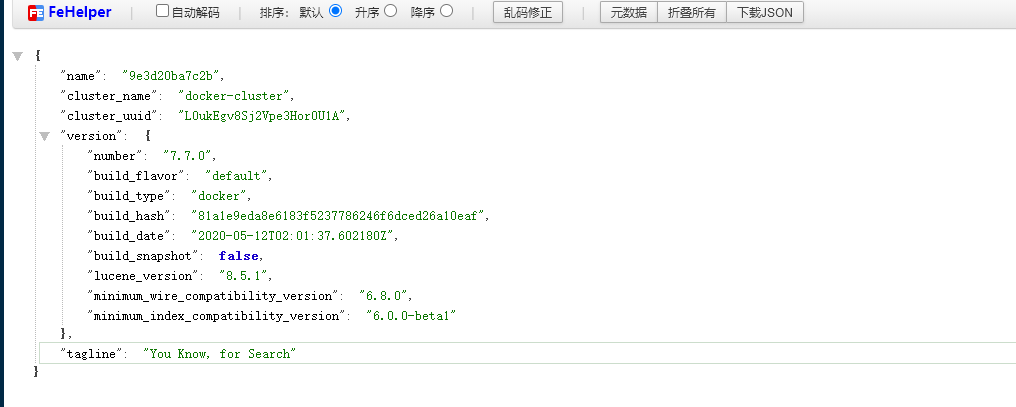
3.浏览器访问ip:9200 如果出现以下界面就是安装成功
4.可装可不装部分:
1.安装elasticsearch-head(es图形界面)
#拉取镜像
docker pull mobz/elasticsearch-head:5
#创建容器
docker run -d --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
2.浏览器打开: http://IP:9100

尝试连接easticsearch会发现无法连接上,由于是前后端分离开发,所以会存在跨域问题,需要在服务端做CORS的配置,解决方法:
docker exec -it elasticsearch /bin/bash (进不去使用容器id进入)
vi config/elasticsearch.yml
#在最下面添加2行
http.cors.enabled: true
http.cors.allow-origin: "*"-
退出并重启es服务
3.安装ik分词器
1.离线安装
这里采用离线安装
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip
将IK分词器上传到/tmp目录中
#将压缩包移动到容器中
docker cp /tmp/elasticsearch-analysis-ik-7.7.0.zip elasticsearch:/usr/share/elasticsearch/plugins
#进入容器
docker exec -it elasticsearch /bin/bash
#创建目录
mkdir /usr/share/elasticsearch/plugins/ik
#将文件压缩包移动到ik中
mv /usr/share/elasticsearch/plugins/elasticsearch-analysis-ik-7.7.0.zip /usr/share/elasticsearch/plugins/ik
#进入目录
cd /usr/share/elasticsearch/plugins/ik
#解压
unzip elasticsearch-analysis-ik-7.7.0.zip
#删除压缩包
rm -rf elasticsearch-analysis-ik-7.7.0.zip
退出并重启容器
2.在线安装
#进入容器
docker exec -it elasticsearch_n1 /bin/bash
cd bin
#安装ik分词器
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip
#重启容器
3.验证ik分词器
1.standard 分词器效果
POST http://localhost:9200/{index}/_analyze
body参数:
{
"analyzer": "standard",
"text": "我是中国人"
}
分词效果:
我 / 是 / 中 / 国 / 人
2.ik_smart 分词器效果
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
分词效果:
我 / 是 / 中国人
3.ik_max_word 分词器效果
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
分词效果:
我 / 是 / 中国人 / 中国 / 国人
三.docker安装ES(集群版)
转载自:https://www.cnblogs.com/caibao666/p/12753274.html
1.真集群版本
1.三台服务器
2.修改每台主机的内核参数vm.max_map_count
3.编辑docker-compose.yaml文件
version: '3'
services:
elasticsearch: # 服务名称
image: elasticsearch:7.7.0 # 使用的镜像
container_name: elasticsearch # 容器名称
restart: always # 失败自动重启策略
environment:
- node.name=node-130 # 节点名称,集群模式下每个节点名称唯一
- network.publish_host=192.168.81.130 # 用于集群内各机器间通信,对外使用,其他机器访问本机器的es服务,一般为本机宿主机IP
- network.host=0.0.0.0 # 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0,即本机
- discovery.seed_hosts=192.168.81.130,192.168.81.131,192.168.81.132 # es7.0之后新增的写法,写入候选主节点的设备地址,在开启服务后,如果master挂了,哪些可以被投票选为主节点
- cluster.initial_master_nodes=192.168.81.130,192.168.81.131,192.168.81.132 # es7.0之后新增的配置,初始化一个新的集群时需要此配置来选举master
- cluster.name=es-cluster # 集群名称,相同名称为一个集群, 三个es节点须一致
# - http.cors.enabled=true # 是否支持跨域,是:true // 这里设置不起作用,但是可以将此文件映射到宿主机进行修改,然后重启,解决跨域
# - http.cors.allow-origin="*" # 表示支持所有域名 // 这里设置不起作用,但是可以将此文件映射到宿主机进行修改,然后重启,解决跨域
- bootstrap.memory_lock=true # 内存交换的选项,官网建议为true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" # 设置内存,如内存不足,可以尝试调低点
ulimits: # 栈内存的上限
memlock:
soft: -1 # 不限制
hard: -1 # 不限制
volumes:
- ./elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml # 将容器中es的配置文件映射到本地,设置跨域, 否则head插件无法连接该节点
- ./data:/usr/share/elasticsearch/data # 存放数据的文件, 注意:这里的esdata为 顶级volumes下的一项。
ports:
- 9200:9200 # http端口,可以直接浏览器访问
- 9300:9300 # es集群之间相互访问的端口,jar之间就是通过此端口进行tcp协议通信,遵循tcp协议。
4.编辑elasticsearch.yml配置文件
network.host: 0.0.0.0
http.cors.enabled: true # 是否支持跨域
http.cors.allow-origin: "*" # 表示支持所有域名
5.初次运行的时候,注释掉compose文件中的volume,需要先运行起来,然后将容器中的data目录cp到宿主机上,否则报错
#注释掉挂载后先执行
docker-compose up -d
#然后执行
docker cp elasticsearch:/usr/share/elasticsearch/data .
#删除容器,重新执行docker-compose
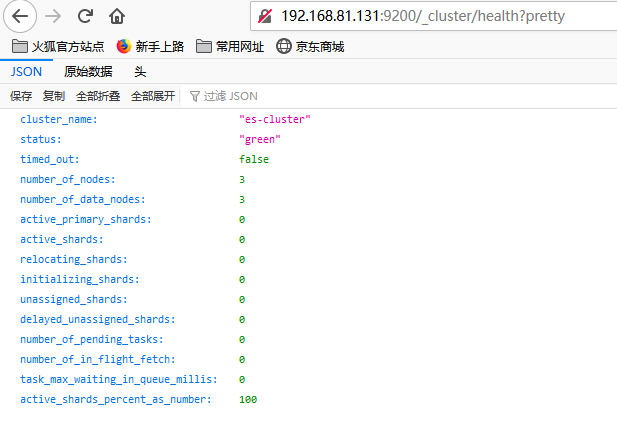
6.访问web界面http://192.168.81.132:9200/_cluster/health?pretty
7.中文分词器
FROM elasticsearch:7.7.0
ADD https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip /usr/share/elasticsearch/plugins/ik/
RUN cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \
&& echo 'Asia/Shanghai' > /etc/timezone \
&& cd /usr/share/elasticsearch/plugins/ik/ \
&& unzip elasticsearch-analysis-ik-7.7.0.zip \
&& rm -f elasticsearch-analysis-ik-7.7.0.zip
执行docker build .
8.curl命令对es的操作示例:
获取:curl -XGET 'http://localhost:9200/odin_device_device_collection'
删:curl -XDELETE 'http://localhost:9200/odin_device_device_collection'
插:curl -XPUT 'http://localhost:9200/odin_device_device_collection' -H 'Content-Type: application/json' -d '数据内容'
查:curl -XGET "http://localhost:9200/odin_device_device_collection/_doc/_search" -H 'Content-Type: application/json' -d'{"query": {"match_all": {}},"from": 0,"size": 300}'
清空:curl -XPOST "http://localhost:9200/odin_device_device_collection/_doc/_delete_by_query" -H 'Content-Type: application/json' -d'{"query": {"match_all": {}}}'
2.伪集群版本
转载自:https://blog.csdn.net/u013887008/article/details/122099169
[root@localhost my-es-cluster]# tree -L 1
.
├── data
├── docker-compose.yml
├── logs
├── node0-elasticsearch.yml
├── node1-elasticsearch.yml
└── node2-elasticsearch.yml
version: '3'
services:
elasticsearch_n0:
image: elasticsearch:7.7.0
container_name: elasticsearch_n0
privileged: true
environment:
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- $PWD/node0-elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- $PWD/data/node0:/usr/share/elasticsearch/data
- $PWD/logs/node0:/usr/share/elasticsearch/logs
ports:
- 9200:9200
- 9300:9300
elasticsearch_n1:
image: elasticsearch:7.7.0
container_name: elasticsearch_n1
privileged: true
environment:
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- $PWD/node1-elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- $PWD/data/node1:/usr/share/elasticsearch/data
- $PWD/logs/node1:/usr/share/elasticsearch/logs
ports:
- 9201:9200
- 9301:9301
elasticsearch_n2:
image: elasticsearch:7.7.0
container_name: elasticsearch_n2
privileged: true
environment:
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- $PWD/node2-elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- $PWD/data/node2:/usr/share/elasticsearch/data
- $PWD/logs/node2:/usr/share/elasticsearch/logs
ports:
- 9202:9200
- 9302:9302
kibana:
image: kibana:7.7.0
container_name: kibana
environment:
- SERVER_NAME=kibana
- ELASTICSEARCH_HOSTS=["http://elasticsearch_n0:9200","http://elasticsearch_n1:9201","http://elasticsearch_n2:9202"]
- XPACK_MONITORING_ENABLED=true
ports:
- 5601:5601
depends_on:
- elasticsearch_n0
#集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: es-cluster
#节点名称
node.name: node0
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最⼤集群节点数
node.max_local_storage_nodes: 3
#⽹关地址
network.host: 0.0.0.0
#端⼝
http.port: 9200
#内部节点之间沟通端⼝
transport.tcp.port: 9300
#es7.x 之后新增的配置,写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.10.211:9300","192.168.10.211:9301","192.168.10.211:9302"]
#es7.x 之后新增的配置,初始化⼀个新的集群时需要此配置来选举master
#数据和存储路径
cluster.initial_master_nodes: ["node0", "node1", "node2"]
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-credentials: true
其他 node1-elasticsearch.yml, node2-elasticsearch.yml 内容一样,如
#集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: es-cluster
#节点名称
node.name: node1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最⼤集群节点数
node.max_local_storage_nodes: 3
#⽹关地址
network.host: 0.0.0.0
#端⼝
http.port: 9201
#内部节点之间沟通端⼝
transport.tcp.port: 9301
#es7.x 之后新增的配置,写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.10.211:9300","192.168.10.211:9301","192.168.10.211:9302"]
#es7.x 之后新增的配置,初始化⼀个新的集群时需要此配置来选举master
#数据和存储路径
cluster.initial_master_nodes: ["node0", "node1", "node2"]
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-credentials: true
1.启动
chmod -R 777 /apps/es-cluster/
docker-compose -f es-cluster-compose.yml up -d
2.使用es-head 插件查看
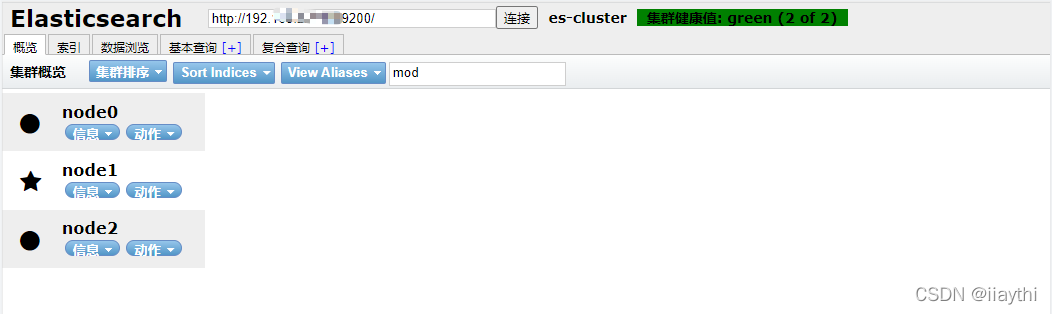
四.ES常用API
转载自:https://blog.csdn.net/weixin_43990804/article/details/111934190
一.基础api
1.查看ES集群的健康状况
curl localhost:9200/_cluster/health?pretty
{
"cluster_name" : "es",
"status" : "yellow", 当前集群状态
"timed_out" : false,
"number_of_nodes" : 3, 当前集群在线的节点个数为3
"number_of_data_nodes" : 3, 在线的数据节点数
"active_primary_shards" : 16055, 活跃的主分片数量
"active_shards" : 32107, 活跃的分片数量,包括主分片和副本。
"relocating_shards" : 0, 正在移动的分片数量
"initializing_shards" : 0, 正初初始化的分片个数为:0
"unassigned_shards" : 3, 未分配的分片个数为:3
"delayed_unassigned_shards" : 0, 由于节点离线导致延迟分配的分片数量
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 99.99065711616318 所有活跃分片/打开的所有索引的分片总数
}
- status字段
- green状态:集群正常主副分片均被分配
- yellow状态:集群主分片已经分配,但副本分片存在无法分配的情况,这时对外提供的服务是正常可用的,数据也都是完整的
- red状态:存在不能分配的主分片
2.查看ES的设置
curl localhost:9200/_cluster/settings?pretty
{
"persistent" : { // 永久设置,重启仍然有效
"action" : {
"auto_create_index" : ".security,.monitoring-*,.watch*,.triggered_watches,.quota,noah*,basp*",
"destructive_requires_name" : "false"
}
},
"transient" : { } // 临时设置,重启失效
}
3.动态设置参数
临时生效:transient修改方法为:curl -XPUT 'http://localhost:9200/_cluster/settings?pretty' -d '{"transient":{"dynamic.parma":"value"}}'
永久生效:persistent修改方法为:curl -XPUT 'http://localhost:9200/_cluster/settings?pretty' -d '{"persistent":{"dynamic.parma":"value"}}'
4.查看ES在线的节点(存在节点缺失的情况可用该命令查看缺失节点为哪些)
curl localhost:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.xx.xxx.xxx 97 99 22 18.64 11.75 9.88 mdi * es.wjl.cn.0
10.xx.xxx.xxx 94 98 37 7.25 7.59 7.74 mdi - es.ejl.cn.0
10.xx.xxx.xxx 93 88 14 8.13 9.16 9.17 mdi - es.wjl.cn.0
5.查看ES的主节点
curl localhost:9200/_cat/master
curl localhost:9200/_cat/master?v // 加上 ?v 将显示字段名.
6.查看所有索引
curl localhost:9200/_cat/indices
curl localhost:9200/_cat/indices?v // 加上 ?v 将显示字段名.
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open java_index jkI8Nh7kSseKq-NV6afXsw 1 1 4 0 9.4kb 4.1kb
green open java_index_test T-PQDsnETYWGdlCzlFeNng 1 1 0 0 416b 208b
green open .apm-custom-link E7lkF1s5QZSByYjzbeqK7Q 1 1 0 0 416b 208b
green open .kibana_task_manager_1 N6p03AdHToKq9AC7vk4ctg 1 1 5 3 57.9kb 33.9kb
green open .apm-agent-configuration -tfJPaTfTX2c4-wYCBJjXg 1 1 0 0 416b 208b
green open .kibana_1 HK6kygrtSViEEn9s4KAkjw 1 1 4 0 61.6kb 30.8kb
7.查看具体某个索引
curl localhost:9200/_cat/indices/{index}
curl localhost:9200/_cat/indices/{index}?v // 加上 ?v 将显示字段名.
- 取索引名最好加上前缀, 因为索引可以模糊匹配
curl -sXGET localhost:9200/_cat/indices/wjl*?v // 查询前缀是wjl的所有索引
8.查询索引的分片情况
curl localhost:9200/_cat/shards?v
index shard prirep state docs store ip node
.kibana_1 0 p STARTED 4 30.8kb 172.19.0.4 node0
.kibana_1 0 r STARTED 4 30.8kb 172.19.0.2 node1
.apm-agent-configuration 0 p STARTED 0 208b 172.19.0.3 node2
.apm-agent-configuration 0 r STARTED 0 208b 172.19.0.2 node1
java_index 0 p STARTED 4 4.1kb 172.19.0.4 node0
java_index 0 r STARTED 4 5.2kb 172.19.0.3 node2
.kibana_task_manager_1 0 r STARTED 5 24kb 172.19.0.3 node2
.kibana_task_manager_1 0 p STARTED 5 33.9kb 172.19.0.2 node1
java_index_test 0 p STARTED 0 208b 172.19.0.4 node0
java_index_test 0 r STARTED 0 208b 172.19.0.2 node1
.apm-custom-link 0 p STARTED 0 208b 172.19.0.4 node0
.apm-custom-link 0 r STARTED 0 208b 172.19.0.3 node2
9.查询指定索引的分片情况
curl localhost:9200/_cat/shards/{index}?v
10.查看segments内存占用情况
curl -sXGET "http://localhost:9200/_cat/nodes?h=name,segments.memory,heap.max&v"
name(es节点名) segments.memory heap.max
es.***.0 5.4gb 29.9gb
es.***.1 5.2gb 29.9gb
11.查看线程池
curl -sXGET "http://localhost:9200/_cat/thread_pool?v"
12.查看ES集群线程池状态
#此处的search是刚才查看线程池中的name
curl -sXGET "http://localhost:9200/_cat/thread_pool/search?v"
如果集群存在入库有延迟的情况,执行thread_poolAPI,如果reject>0,说明集群的处理能力低于入库请求,请求业务方降低入库速率。
node_name name active queue rejected
es.***.0 search 4 0 0
es.***.0 search 61 977 4326
es.***.1 search 61 495 3497
如果reject>0,说明集群的处理能力低于查询请求,需要降低查询速率。
13.打开指定索引
curl -XPOST "http://localhost:9200/{index}/_open"
14.关闭指定索引
curl -XPOST "http://localhost:9200/{index}/_close"
15.查看某个索引的mapping
curl -sXGET "http://localhost:9200/{index}/_mapping"
五.Java操作es
参考链接1:https://mp.weixin.qq.com/s/6qk-fkX-mo0meo5D6Wz2-Q
参考链接2:https://www.yuque.com/genwoshuohuaqingtoubi/dwv59c/dh569i#sVSWb
1.引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
或者
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>4.4.5</version>
</dependency>
#base
server:
port: 8080
#spring
spring:
application:
name: springboot-elasticsearch-example
#elasticsearch
elasticsearch:
schema: http
address: 127.0.0.1:9200
connectTimeout: 5000
socketTimeout: 5000
connectionRequestTimeout: 5000
maxConnectNum: 100
maxConnectPerRoute: 100
2.实例化http请求对象
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(
RestClient.builder(
//ES集群的相关信息,如果有多个就配置多个
new HttpHost("192.168.10.211",9200,"http"),
new HttpHost("192.168.10.211",9201,"http"),
new HttpHost("192.168.10.211",9202,"http")
)
);
return restHighLevelClient;
}
/** 协议 */
@Value("${elasticsearch.schema:http}")
private String schema;
/** 集群地址,如果有多个用“,”隔开 */
@Value("${elasticsearch.address}")
private String address;
/** 连接超时时间 */
@Value("${elasticsearch.connectTimeout:5000}")
private int connectTimeout;
/** Socket 连接超时时间 */
@Value("${elasticsearch.socketTimeout:10000}")
private int socketTimeout;
/** 获取连接的超时时间 */
@Value("${elasticsearch.connectionRequestTimeout:5000}")
private int connectionRequestTimeout;
/** 最大连接数 */
@Value("${elasticsearch.maxConnectNum:100}")
private int maxConnectNum;
/** 最大路由连接数 */
@Value("${elasticsearch.maxConnectPerRoute:100}")
private int maxConnectPerRoute;
@Bean
public RestHighLevelClient restHighLevelClient() {
// 拆分地址
List<HttpHost> hostLists = new ArrayList<>();
String[] hostList = address.split(",");
for (String addr : hostList) {
String host = addr.split(":")[0];
String port = addr.split(":")[1];
hostLists.add(new HttpHost(host, Integer.parseInt(port), schema));
}
// 转换成 HttpHost 数组
HttpHost[] httpHost = hostLists.toArray(new HttpHost[]{});
// 构建连接对象
RestClientBuilder builder = RestClient.builder(httpHost);
// 异步连接延时配置
builder.setRequestConfigCallback(requestConfigBuilder -> {
requestConfigBuilder.setConnectTimeout(connectTimeout);
requestConfigBuilder.setSocketTimeout(socketTimeout);
requestConfigBuilder.setConnectionRequestTimeout(connectionRequestTimeout);
return requestConfigBuilder;
});
// 异步连接数配置
builder.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.setMaxConnTotal(maxConnectNum);
httpClientBuilder.setMaxConnPerRoute(maxConnectPerRoute);
return httpClientBuilder;
});
return new RestHighLevelClient(builder);
}
3.es中的curd
参考链接:https://gyoomi.blog.csdn.net/article/details/104011232?spm=1001.2014.3001.5502
package cn.elasticsearch.demo;
import cn.elasticsearch.demo.entity.Student;
import cn.elasticsearch.demo.entity.User;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
@SpringBootTest
class DemoApplicationTests {
@Autowired
RestHighLevelClient restHighLevelClient;
@Autowired
ElasticsearchRestTemplate elasticsearchRestTemplate;
//创建索引
@Test
void testCreateIndex() throws IOException {
//1.创建索引请求
CreateIndexRequest indexRequest = new CreateIndexRequest("mapping_index");
//2.设置分片和副本数(可以使用默认值,分片1,备份1),可不设置
//写法1
indexRequest.settings(Settings.builder()
.put("index.number_of_shards", 3)
.put("index.number_of_replicas", 1)
);
//写法2
// indexRequest.settings("{\"index\":{\"number_of_shards\":\"9\",\"number_of_replicas\":\"2\"}}",XContentType.JSON);
//3.创建mapping映射类型,可以使用插入数据后es自动推算的映射类型,可不设置
//写法1,实际就是拼接字符串,推荐使用json字符串
// XContentBuilder xContentBuilder = XContentFactory.jsonBuilder()
// .startObject()
// .startObject("house")
// .startObject("properties")
// .startObject("house_id")
// .field("type", "long")
// .field("store", true)
// .endObject()
// .startObject("house_guid")
// .field("type", "text")
// .field("store", true)
.field("analyzer", "ik_smart")
// .endObject()
// .startObject("house_name")
// .field("type", "text")
// .field("store", true)
.field("analyzer", "ik_smart")
// .endObject()
// .endObject()
// .endObject()
// .endObject();
// indexRequest.mapping(xContentBuilder);
//写法2
indexRequest.mapping(
"{\n" +
" \"properties\":{\n" +
" \"age\":{\n" +
" \"type\":\"long\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\":\"text\",\n" +
" \"fields\":{\n" +
" \"keyword\":{\n" +
" \"type\":\"keyword\",\n" +
" \"ignore_above\":256\n" +
" }\n" +
" }\n" +
" }\n" +
" }\n" +
"}",
XContentType.JSON);
//4.客户端执行请求创建索引
CreateIndexResponse createIndexResponse =restHighLevelClient.indices().create(indexRequest, RequestOptions.DEFAULT);
}
//创建映射(已废弃)
@Test
void testCreateMapping() throws IOException {
//创建索引请求
try {
elasticsearchRestTemplate.putMapping(Student.class);
} catch (Exception e) {
elasticsearchRestTemplate.createIndex(Student .class);
elasticsearchRestTemplate.putMapping(Student .class);
}
}
//获取index
@Test
void testGet() throws IOException {
GetIndexRequest javaIndex = new GetIndexRequest("index_for_kibana");
Boolean bool = restHighLevelClient.indices().exists(javaIndex,RequestOptions.DEFAULT);
System.out.println(bool);
}
//删除index
@Test
void testDelete() throws IOException {
DeleteIndexRequest javaIndex = new DeleteIndexRequest("mapping_index");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(javaIndex,RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
//测试添加文档
@Test
void addDocument() throws IOException {
User user = new User();
user.setName("张张");
user.setAge(26);
//创建请求
IndexRequest javaIndex = new IndexRequest("index_for_kibana");
//填充规则
//文档编号
javaIndex.id("1");
//将对象放入请求中
javaIndex.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,接收响应结果
IndexResponse indexResponse = restHighLevelClient.index(javaIndex,RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
//测试判断文档是否存在
@Test
void existDocument() throws IOException {
GetRequest javaIndex = new GetRequest("index_for_kibana","1");
Boolean bool = restHighLevelClient.exists(javaIndex,RequestOptions.DEFAULT);
System.out.println(bool);
}
//测试获取文档信息
@Test
void getDocument() throws IOException {
GetRequest javaIndex = new GetRequest("index_for_kibana","1");
GetResponse getResponse = restHighLevelClient.get(javaIndex,RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());
System.out.println(getResponse);
}
//修改获取文档信息
@Test
void updateDocument() throws IOException {
User user = new User();
user.setName("测试数据");
user.setAge(18);
UpdateRequest javaIndex = new UpdateRequest("java_index","1");
javaIndex.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(javaIndex,RequestOptions.DEFAULT);
System.out.println(updateResponse.toString());
System.out.println(updateResponse.status());
}
//删除文档信息
@Test
void deleteDocument() throws IOException {
DeleteRequest javaIndex = new DeleteRequest("java_index","1");
DeleteResponse delete = restHighLevelClient.delete(javaIndex,RequestOptions.DEFAULT);
System.out.println(delete);
System.out.println(delete.status());
}
//测试批量添加文档下信息
@Test
void batchAddDocument() throws IOException {
//创建批量操作对象
BulkRequest bulk = new BulkRequest();
ArrayList<User> list = new ArrayList<>();
list.add(new User().setName("张一山").setAge(16));
list.add(new User().setName("张二牛").setAge(11));
list.add(new User().setName("张三").setAge(22));
list.add(new User().setName("张武").setAge(19));
for(int i=0;i<list.size();i++) {
bulk.add(new IndexRequest("index_for_kibana").id((i+2)+"")
.source(JSON.toJSONString(list.get(i)),XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(bulk,RequestOptions.DEFAULT);
System.out.println(bulkResponse);
//查看状态,是否失败,返回false代表成功
System.out.println(bulkResponse.hasFailures());
}
//20220414测试
@Test
void batchAddDoc() throws Exception {
//创建批量操作对象
BulkRequest bulk = new BulkRequest();
String [] name = {"张","王","李","赵","杨","刘","陈","黄"};
String [] school = {"清华大学","北京大学","交通大学"};
for (int j = 0; j < 100; j++) {
for (int i = 300*j; i < 300 + 300*j; i++) {
bulk.add(new IndexRequest("large_all_index")
.id((i+1)+"")
.source(JSON.toJSONString(new User()
.setName(name[(i+1)%7]+name[(2*i)%7])
.setAge(i%55).setSchool(school[i%3])
.setRemark(name[(i+1)%7]+name[(2*i)%7]+"想去"+school[i%3])
.setDate(new Date())),XContentType.JSON));
}
// RestHighLevelClient client = ElasticSearchPoolUtil.getClient();
BulkResponse bulkResponse = restHighLevelClient.bulk(bulk,RequestOptions.DEFAULT);
// ElasticSearchPoolUtil.returnClient(client);
System.out.println(bulkResponse);
//查看状态,是否失败,返回false代表成功
System.out.println(bulkResponse.hasFailures());
}
}
}
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









