






以爬取JD商品信息为例:
1.使用webDriver爬取数据(已经不太流行了):
webDriver介绍:
WebDriver是直接调用Web浏览器,启动一个浏览器实例作为webDriver的remote server
使用webDriver需要先下载chromedriver驱动(用于启动对应的浏览器,以google浏览器为例):
1.先查看自己的浏览器是什么版本的:
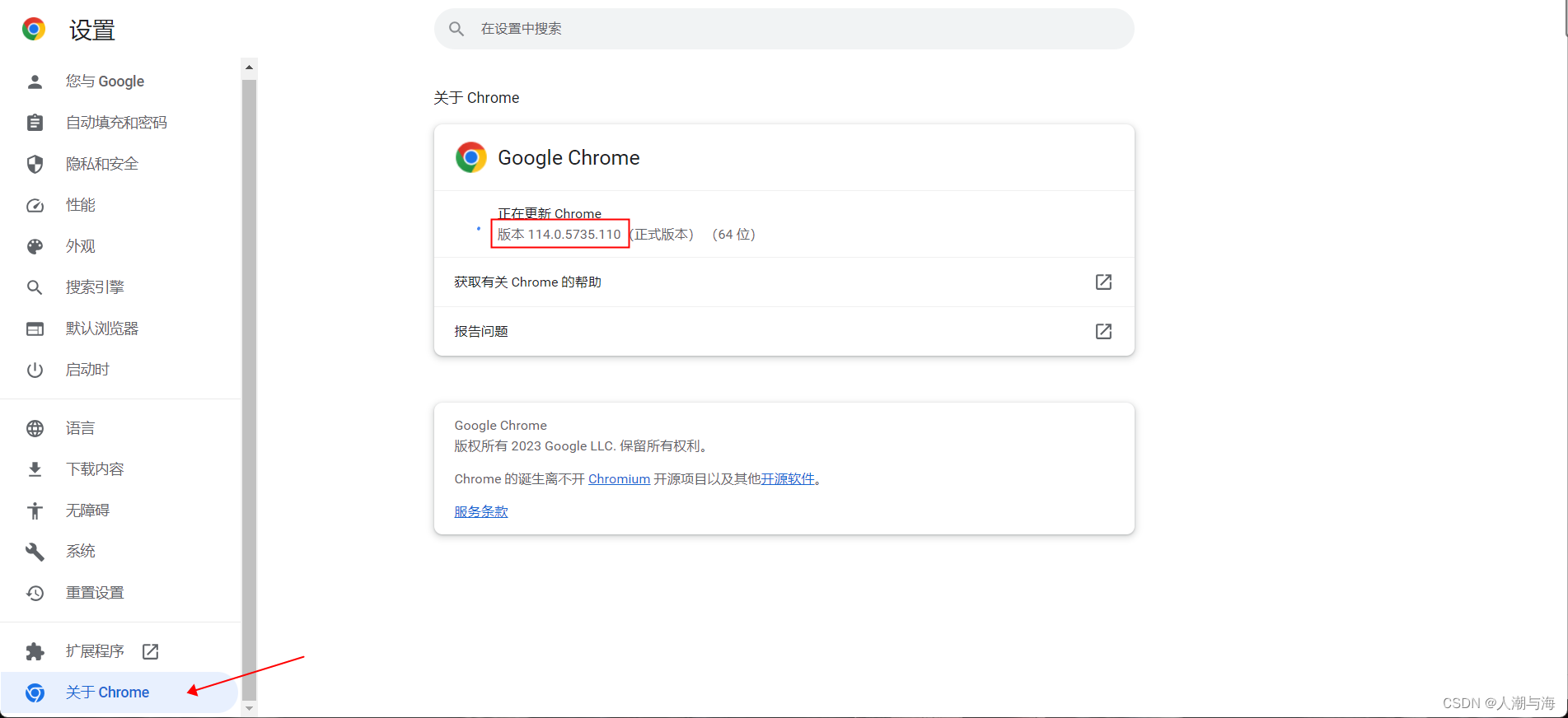
2.下载匹配的chromedriver驱动:
如果你的浏览器版本是118.0.5993.70或以上到该链接找到你的版本进行下载:
Chrome for Testing availability (googlechromelabs.github.io)
如果不是到该链接找到你的版本进行下载:
ChromeDriver - WebDriver for Chrome - Downloads (chromium.org)
注意:可能会一直找不到对应的版本,则找个和浏览器版本最相近的版本
准备就绪后就可以开始写代码了(java):
导入依赖:
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>31.0.1-jre</version> </dependency> <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-chrome-driver</artifactId> </dependency> <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-api</artifactId> </dependency>
代码演示:
public Map WebDriver(String url) {
// url = "https://item.jd.com/xxxxxxxxxxxxx.html"(商品详情页面的url)
// 我们的爬取不通过登录,因为JD的登录很麻烦再加上JD的商品详情界面的价格是通过请求去拿取的而且每一次请求都会更改用户的token和cookie,所以pass掉登录爬取。那有怎么不让页面跳登录呢,我则是在让页面加载完dom树时就直接给暂停加载了。
//创建ChromeOptions对象,用来配置和管理webDriver的。
ChromeOptions chromeOptions = new ChromeOptions();
//设置页面停止加载条件(eager:要等待整个dom树加载完成,即DOMContentLoaded 这个事件完 成,仅对html的内容进行下载解析。
// normal:正常情况下,selenium 会等待整个界面加载完成(指对html和子资源的下载与解析,入JS文件,图片等,不包含ajax)
// none:当html下载完成之后,不等待解析完成,selenium 会直接返回)
chromeOptions.setPageLoadStrategy(PageLoadStrategy.EAGER);
//解决 403 出错问题
chromeOptions.addArguments("--remote-allow-origins=*");
// chromeOptions.addArguments("--headless")(该方法用来管理浏览器是否显示,不过在linux系统上不添加该方法是会报错的)
//设置系统驱动属性(第二个参数就是你安装的chromedriver的地址)
System.setProperty("webdriver.chrome.driver", "D:\\迅雷下载\\chromedriver_win32\\chromedriver.exe");
//创建webDriver对象
WebDriver webDriver = new ChromeDriver(chromeOptions);
//webDriver需要访问的网址
webDriver.get(url);
//创建JavascriptExecutor对象
JavascriptExecutor executor = (JavascriptExecutor) webDriver;
//执行JavaScript代码来停止页面
executor.executeScript("return window.stop();");
//截取商品id
String productId = url.substring(20).split(".html")[0];
//获取商品名称
String productName = webDriver.findElement(By.className("sku-name")).getText();
//创建list装需要的参数
List<String> txtList=new ArrayList<>();
//获取商品内容
//By.cssSelector():该方法和前端获取标签一样,“#”开头表示标签的id;“.”开头则是标签的class;什么都不加则是标签;和前端的js一模一样
List<WebElement> elements = webDriver.findElements(By.cssSelector(".p-parameter ul li"));
for (int i = 0; i < elements.size(); i++) {
txtList.add(elements.get(i).getText());
}
//获取商品图片
List<String> imgList=new ArrayList<>();
//图片
List<WebElement> imgs = webDriver.findElements(By.cssSelector(".lh li img"));
for (int i = 0; i < imgs.size(); i++) {
String src = imgs.get(i).getAttribute("src");
if (!(src.contains("https") || src.contains("http"))){
src="https:"+src;
}
src=src.replaceAll("(/n[0-9]/)(.*)(jfs)", "/n0/jfs");
src=src.replaceAll("\\.avif","");
imgList.add(src);
}
/*
接下来就是重头戏了:
由于开头说过通过商品详情界面拿取价格是很麻烦的,所以为了获取商品价格我则先从商品详情页面拿取到商品的名称,从url中拿取到商品的id,然后再到搜索的页面搜索该商品。
*/
//搜索页面url(productName:商品名称)
String searchUrl = "https://search.jd.com/Search?keyword="+productName;
webDriver.get(searchUrl);
//执行JavaScript代码来停止页面
executor.executeScript("return window.stop();");
//再根据商品id找到对应的商品价格。由于JD的搜索页面的每一个商品的class都会根据商品的id来命名所以只要在固定的格式上加上productId就大功告成了
txtList.add("价格:"+webDriver.findElement(By.className("J_"+productId)).getText());
//wd.close()方法关闭当前的浏览器窗口,quit方法不仅关闭窗口,还会彻底的退出webdriver,
// 释放与driver server之间的连接。所以简单来说quit是更加彻底的close,quit会更好的释放资源。
webDriver.quit();
Map<String,Object> map = new HashMap<>();
map.put("txtList",txtList);
map.put("imgList",imgList);
return map;
}
2.使用HttpClient爬取数据:
该方法就没那么繁琐了,不过容易有被封ip的危险(webDriver也会,只要请求不太频繁大多数不会,可以去查一下怎么预防封ip)。而且该方法不需要暂停页面什么的,不用担心会跳转登录页面:
导入依赖:
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency> <!--解析网页jsoup--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.3</version> </dependency>
代码演示:
String url = "https://item.jd.com/10073465383533.html"; //创建httpClient对象 CloseableHttpClient httpClient = HttpClients.createDefault(); //创建HttpGet对象 HttpGet get = new HttpGet(url);
设置请求头,请求头是用正常浏览器访问时请求头中的User-Agent(打开你要爬取的网址,然后随便找一个请求复制他里面的User-Agent):
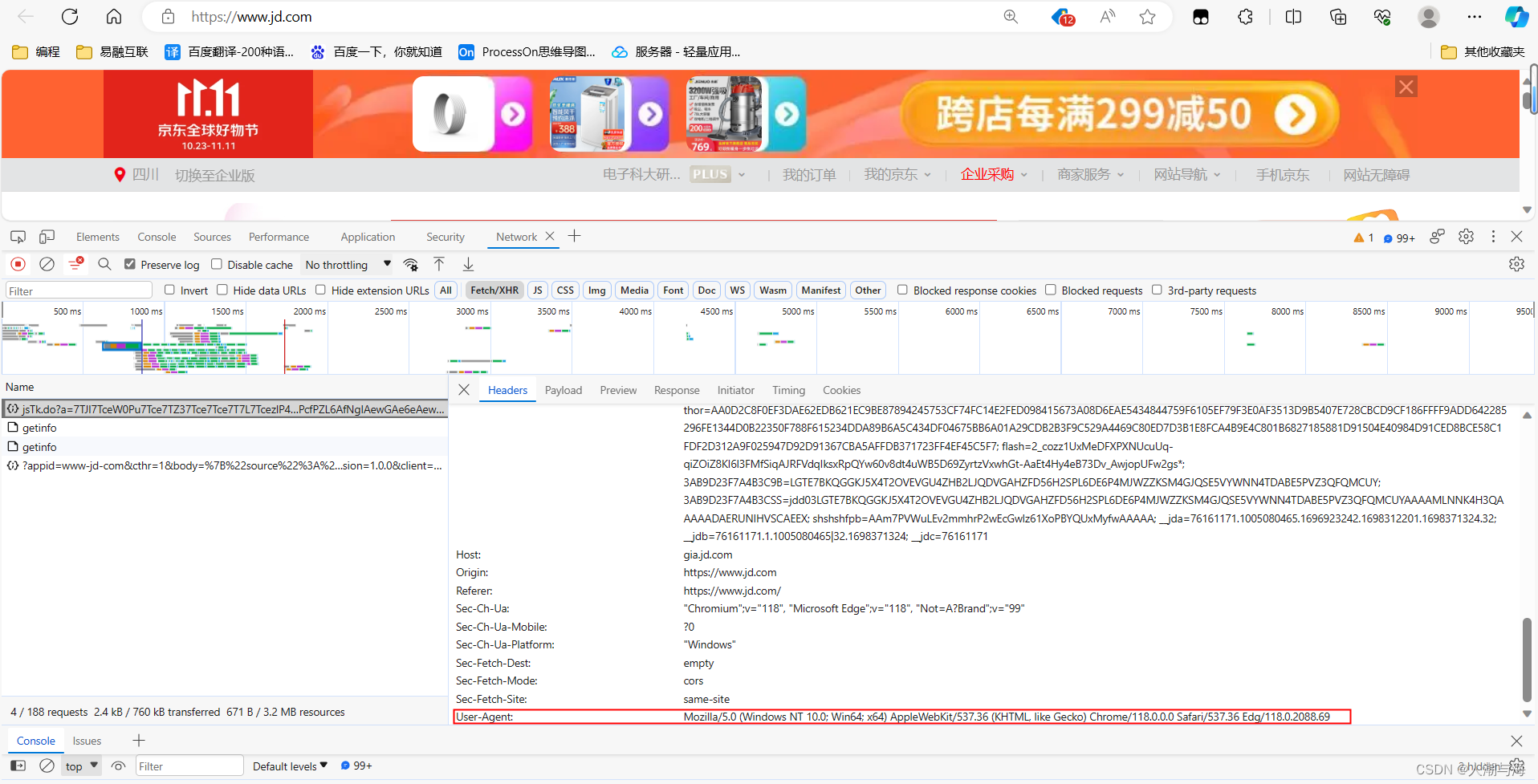
//设置请求头,请求头是用正常浏览器访问时请求头中的User-Agent
get.addHeader("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.57");
//发起请求并获取页面
CloseableHttpResponse execute = httpClient.execute(get);
//将页面转为document
Document document = Jsoup.parse(EntityUtils.toString(execute.getEntity()));
List<String> txtList=new ArrayList<>();
//截取商品id
String productId = url.substring(20).split(".html")[0];
//document的一些方法就不做阐述了,百度一下或者问问前端的朋友一下就明白了
String productName = document.getElementsByClass("sku-name").text();
//获取商品信息
Elements elementsByClass = document.getElementsByClass("p-parameter");
for (int i = 0; i < elementsByClass.size(); i++) {
txtList.add(elementsByClass.get(i).text());
}
}
//由于第二个url是需要传参的所以需要创建URIBuilder对象
URIBuilder uriBuilder = new URIBuilder("https://search.jd.com/Search");
//设置传参
uriBuilder.setParameter("keyword",productName);
//设置HttpGet对象
get = new HttpGet(uriBuilder.build());
//设置请求头
get.addHeader("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.57");
//发起请求并获取页面
CloseableHttpResponse execute1 = httpClient.execute(get);
//将页面转为document
Document document1 = Jsoup.parse(EntityUtils.toString(execute1.getEntity()));
//获取商品价格
String price = document1.getElementsByClass("J_"+productId).text();
txtList.add("价格:"+price);
//获取完数据关闭HttpClient
httpClient.close();














 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









