









0x00 从一个简单程序分析内存
关于Linux的内核的书看了很多,但是其中还算是linux内核源代码情景分析比较详细。/2016/11/4修改
#include <stdio.h>
void greet(){
printf("Hello Word !");
}
int main(void){
greet();
}说明
经过反汇编后,我们可以看见每行指令前边的地址,其实我们在编译我们写的代码的时候,我们所用的的不同的编译器、链接器都会为该代码分配地址,在Windows或者Linux上,所分配的地址都是虚拟地址,其实在程序经过编译器和链接器是,链接器(具体的软件已经含有)有固定的链接脚本(记得后缀名是.lds),这个链接脚本就为上面这个Hello World程序分配的相同的开始地址。
分析
不扯太多,其实此时分配都是虚拟地址,程序运行时的物理地址都是运行时操作系统分配的,运行的物理地址每次都可能不同,然后就是这本书开始讲了,聊聊这个从虚拟地址到物理地址的映射过程。
- 分阶段映射:
假如这段程序分配的虚拟地址入口为:0x8048568 - 段式映射阶段(相关的寄存器: 代码段寄存器CS)
首先这个寄存器很常见,会点汇编的都知道,凡是寄存器都有格式定义吧,每一位代表什么,有什么作用吧,这一阶段主要分析CS段,在Linux内核中,存在KERNEL_CS和USER_CS,但是他们的寄存器地址是一样的,首先根据此时程序运行的CS值(index),在GDT表中去选择。。。这里也有实模式和保护模式的区别,在保护模式里边,需要根据CS的值,然后去GDT表里边找到相应的值。对,没错,进入保护模式后就是这样的麻烦。去找到GDT表如下:
ENTRY(gdt_table){
.quad 0x0000000000000000 //index==0
.quad 0x0000000000000000 //index==1
.quad 0x00cf9a000000ffff //....===2
.quad 0x00cf92000000ffff
.quad 0x00cffa000000ffff
.quad 0x00cff2000000ffff
.quad 0x0000000000000000
.quad 0x0000000000000000
}全局描述符
上面这个表就是全局描述符表,里边成员都是段描述符,大概看看,在这个表中,第一个成员:
0x0000000000000000 全0对吧,这是在intel手册里边规定的,好像像XV6这个系统也是这样,第一个也是全0,用intel的芯片估计都要这样干。这不是重点,这个表中的成员好像都是64位,那么这64是什么含义吧:

这个图片是在intel的手册里边找到的,下边是前32位,上边是后32位,哦,原来这64位有不同的功能。
CS段寄存器包含有Index、TI、RPL信息:
———Index———TI - RPL
0000 0000 XXXX X–X—-XX
前面提到过,CS是16位寄存器,上面正好表现出这16位包含的信息,前13位是索引值,就是gdt_table的值,通过ENTRY()将四个段(_KERNEL_CS、_KERNEL_DS、_USER_CS、_USER_DS)映射到4GB的虚拟空间,从虚拟地址到线性地址的映射保持原值不变,此后在页式映射到时候,所提到的原值地址就是虚拟地址,这里我以前看的时候一直在想原值不变是什么意思,太尴尬了,这才明白,那么这里不变是什么意思,上边的GDT图片可以看出里边的base address是31—-0,这就是那个没变的地址,可以这么理解:虚拟地址空间是虚构的,因为我们现在有一个32位的目标地址,但是呢,这4G的空间—-真正对应内存不存在吧,这些32位构成的可能(组合),就是2的32次方吧,这是数学上这么看,但是在计算机文化里,就叫空间,没有对应的物理内存,那就叫虚拟空间吧。
以上就是段式保护机制的重点。
其实,在Linux中段式保护机制是个虚设,主要是下面讲的页式存储。
2016/4/13晚 再续
下面讲的是页式保护机制,上面提到了原值地址就是虚拟地址,i386 CPU要访问内存三次,第一次是页面目录,第二次是页面表,第三次是访问真正的目标。如何实现的三次访问:
先来一个图吧:
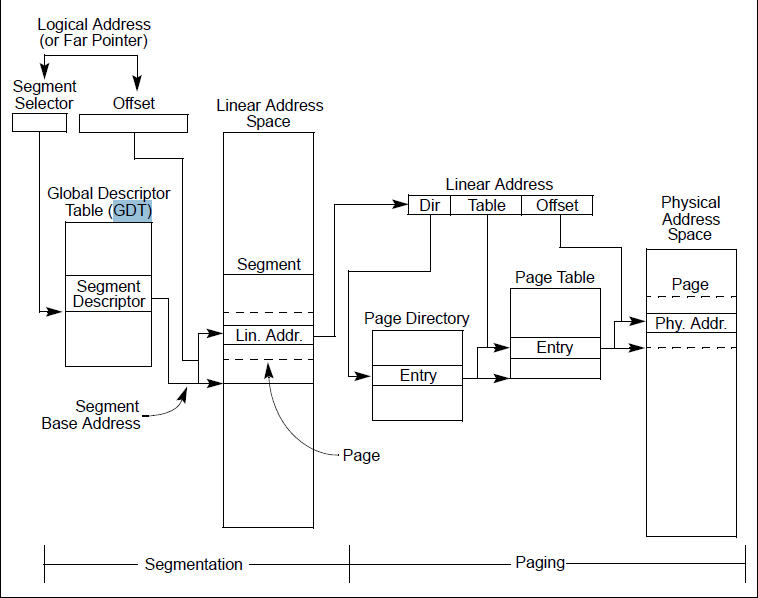
上面这个图中有一个 liner address,就是页式保护的具体,详细图片:
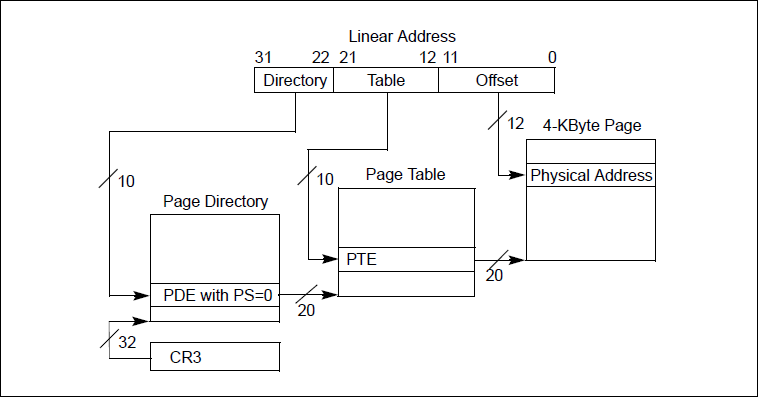
第一步: 通过页目录表找到页面表
还是以上面的程序为例:
hello程序执行后,调用函数greeting,这里的虚拟地址也就是线性地址为0x08048354
反汇编代码:call 08048354
将线性地址二进制展开后的结果是:
0000 1000 0000 0100 1000 0011 0101 0100
第1个段位(高10位): 0000 1000 00
对映十进制的32,也就是在页目录表的偏移32找到其页面表的物理地址,也就是页面表的指针,它的低12位是0,因为页面表是4KB大小,所以肯定是边界对齐了。
第二步: 通过页面表找到页的起始物理地址高
接下来是线性地址的第二个段位(中间10位): 00 0100 10 00
对映十进制的72,也就是在刚才找到的页面表的偏移72找到目标页的起始物理地址,高20位有效的地址,低12位填充为0.假如其实物理地址是0X740000.
第三步: 得到最终的物理地址
通过找到的页起始物理地址,加上线性地址的第三个段位的偏移地址得到最终的物理地址,最终的物理地址就是0x740000+0x354=0x740354
最后说明我们的这个Hello程序,就存在0x740354为起始位置的内存中,或者是磁盘中。
Linux如何实现以上过程?
下面,我将在Linux源码中找到相关映射顺序及源代码:(2016/4/18更新)
正在学习于渊的一个操作系统的编写,因为看《linux源代码情景分析》这本书,看不下去了,希望尽快看完于渊的书,学到操作系统的大概知识。(2016/6/26)
其实看内存管理看了好几遍,但是一直不知道这到底是有多重要,在操作系统里边是什么地位,因为一直不知道这个为什么要内存管理,这让高手们见笑了,并且以前对操作系统没有宏观的了解,最后觉得,学操作系统原理什么的,看再多的书,还不如先写一个操作系统,然后就选择了看于渊的写orange的那本书,发现的确看完那书,对操作系统有了宏观的认识了,有时间再看两遍,其实我觉得要是他在书中体现一下如何与Intel 64及IA-32 架构软件开发者手册(1~3卷)结合写orange的思想过程就完美了,这样也能让我们看到作者设计系统的思路了。
//2016/11/14 更新
这几天一直在纠结到底用那个linux内核,刚开始用的是3.4.2的内核,但是与毛老师的本书变化有点大,尤其是没有i386架构啦,那还看个屁呀,所以这在历史的关键时刻,跑回来2.6.22.6的内核,好多内核的标记、自己写的注释又得重新添加了//
好吧! 接着2.6.22.6的内核开始…
现在,我就从i386的内核从启动开始过一遍:
在2.6以后的代码,i386的bootsect.s就没什么用的,原来的bootsect.s的功能是生成一个512byte的程序,加载到传说中的0x7c00处,然后将本身和setup.s加载到0x90000处,然后跳转到setup.s执行,接下来。。。。。但是现在的bootsect.s打印出:
"Direct booting from floppy is no longer supported.\r\n"
"Please use a boot loader program instead.\r\n"
"\n"
"Remove disk and press any key to reboot . . .\r\n" 现在不支持从软盘启动了,现在需要bootloader了。
那么从bootloader接力的第一行代码是哪?网上有人说是这样:
在grub的boot_func中的big_linux_boot 里,描述了实际上grub的stage2将内核的
bootsect和setup实模式代码载入到地址0x90000后,是skip了头0x200个字节的,直接跳转到地址0x90200处执行的。
下次得去u-boot找到相应的代码才能证明!
现在就姑且认为他是对的吧,setup还是原来的setup,功能没有多大变化:
设置好GDT表和IDT表、打开A20,进入保护模式等等。
movw $1, %ax # protected mode (PE) bit
lmsw %ax # This is it!
jmp flush_instr
flush_instr:
xorw %bx, %bx # Flag to indicate a boot
xorl %esi, %esi # Pointer to real-mode code
movw %cs, %si
subw $DELTA_INITSEG, %si
shll $4, %esi # Convert to 32-bit pointer
# jump to startup_32 in arch/i386/boot/compressed/head.S
........
.byte 0x66, 0xea # prefix + jmpi-opcode
code32: .long startup_32 # will be set to %cs+startup_32
.word __BOOT_CS
.code32
startup_32:
movl $(__BOOT_DS), %eax
movl %eax, %ds
movl %eax, %es
movl %eax, %fs
movl %eax, %gs
movl %eax, %ss
xorl %eax, %eax
1: incl %eax # check that A20 really IS enabled
movl %eax, 0x00000000 # loop forever if it isn't
cmpl %eax, 0x00100000
je 1b
# Jump to the 32bit entry point
jmpl *(code32_start - start + (DELTA_INITSEG << 4))(%esi) 这里就是置PE位,进入32位保护模式,然后jmpl *(code32_start - start + (DELTA_INITSEG << 4))(%esi), 代码就是arch/i386/boot/compressed/head.S
最后在head.s来了一个跳转:jmp %ebp / 跳转到arch6/i386/kernel/head.s */
最终我们会跑到init/main.c/start_kernel函数,没错这里是每一个架构的CPU都会跑到这里:第一个C语言函数。
asmlinkage void __init start_kernel(void)
{
char * command_line;
extern struct kernel_param __start___param[], __stop___param[];
smp_setup_processor_id();
/*
* Need to run as early as possible, to initialize the
* lockdep hash:
*/
unwind_init();
lockdep_init();
local_irq_disable();
early_boot_irqs_off();
early_init_irq_lock_class();
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them
*/
lock_kernel();
tick_init();
boot_cpu_init();
page_address_init();
printk(KERN_NOTICE);
printk(linux_banner);
setup_arch(&command_line);
setup_command_line(command_line);
unwind_setup();
setup_per_cpu_areas();
smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
/*
* Set up the scheduler prior starting any interrupts (such as the
* timer interrupt). Full topology setup happens at smp_init()
* time - but meanwhile we still have a functioning scheduler.
*/
sched_init();
/*
* Disable preemption - early bootup scheduling is extremely
* fragile until we cpu_idle() for the first time.
*/
preempt_disable();
build_all_zonelists();
page_alloc_init();
printk(KERN_NOTICE "Kernel command line: %s\n", boot_command_line);
parse_early_param();
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param,
&unknown_bootoption);
if (!irqs_disabled()) {
printk(KERN_WARNING "start_kernel(): bug: interrupts were "
"enabled *very* early, fixing it\n");
local_irq_disable();
}
sort_main_extable();
trap_init();
rcu_init();
init_IRQ();
pidhash_init();
init_timers();
hrtimers_init();
softirq_init();
timekeeping_init();
time_init();
profile_init();
if (!irqs_disabled())
printk("start_kernel(): bug: interrupts were enabled early\n");
early_boot_irqs_on();
local_irq_enable();
/*
* HACK ALERT! This is early. We're enabling the console before
* we've done PCI setups etc, and console_init() must be aware of
* this. But we do want output early, in case something goes wrong.
*/
console_init();
if (panic_later)
panic(panic_later, panic_param);
lockdep_info();
/*
* Need to run this when irqs are enabled, because it wants
* to self-test [hard/soft]-irqs on/off lock inversion bugs
* too:
*/
locking_selftest();
#ifdef CONFIG_BLK_DEV_INITRD
if (initrd_start && !initrd_below_start_ok &&
initrd_start < min_low_pfn << PAGE_SHIFT) {
printk(KERN_CRIT "initrd overwritten (0x%08lx < 0x%08lx) - "
"disabling it.\n",initrd_start,min_low_pfn << PAGE_SHIFT);
initrd_start = 0;
}
#endif
vfs_caches_init_early();
cpuset_init_early();
mem_init();
kmem_cache_init();
setup_per_cpu_pageset();
numa_policy_init();
if (late_time_init)
late_time_init();
calibrate_delay();
pidmap_init();
pgtable_cache_init();
prio_tree_init();
anon_vma_init();
#ifdef CONFIG_X86
if (efi_enabled)
efi_enter_virtual_mode();
#endif
fork_init(num_physpages);
proc_caches_init();
buffer_init();
unnamed_dev_init();
key_init();
security_init();
vfs_caches_init(num_physpages);
radix_tree_init();
signals_init();
/* rootfs populating might need page-writeback */
page_writeback_init();
#ifdef CONFIG_PROC_FS
proc_root_init();
#endif
cpuset_init();
taskstats_init_early();
delayacct_init();
check_bugs();
acpi_early_init(); /* before LAPIC and SMP init */
/* Do the rest non-__init'ed, we're now alive */
rest_init();
}
上面这段代码只是感觉有必要放在这,毕竟我们终于看到了C,但是这只是内存管理的开始。















 3739
3739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









