







 本文介绍了线性降维的三种方法:PCA(主成分分析)、LDA(线性判别分析)和MDS(多维缩放)。PCA通过最大化方差来寻找主要成分;LDA是监督学习方法,力求最大化类别间方差和最小化类内方差;MDS则尝试保持降维后样本间距离不变。文章提供了KNN算法的背景,解释了距离度量对KNN的影响,并讨论了高维数据的维度灾难问题。最后,文章通过代码示例展示了PCA和LDA的实现过程。
本文介绍了线性降维的三种方法:PCA(主成分分析)、LDA(线性判别分析)和MDS(多维缩放)。PCA通过最大化方差来寻找主要成分;LDA是监督学习方法,力求最大化类别间方差和最小化类内方差;MDS则尝试保持降维后样本间距离不变。文章提供了KNN算法的背景,解释了距离度量对KNN的影响,并讨论了高维数据的维度灾难问题。最后,文章通过代码示例展示了PCA和LDA的实现过程。
1. KNN
为什么要在介绍降维之前学习KNN呢?因为以KNN为代表的一类算法,由于其为非参数化模型,无法通过一组固定的参数和固定的模型进行表征。此外,KNN还是惰性学习算法的典型例子。惰性是指它仅仅对训练数据集有记忆功能,而不会从训练集中通过学习得到一个判别函数。惰性学习算法一般思想简单,且没有训练过程。与之相对应的则是急切学习,需要以数据集为基础进行训练建模、总结规律,然后利用测试集对建立的模型进行测试。KNN为代表的一类算法,即没有参数、不需要训练过程,也无法使用例如在损失函数中加入正则项之类的方法对维度系数进行约束,所以易造成过拟合,进而导致传说中的维度风暴。
1.1 KNN思想及特性
KNN,即K-Nearest Neighbor,又称K近邻算法,是一个理论上非常成熟的算法,也是最简单的算法之一。
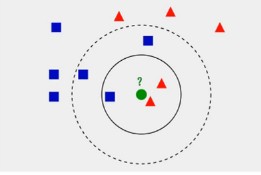
该算法的思路也确实简单:如果一个样本在特征空间中的K个最相似(即特征空间中按照某个度量计算的距离最近)的样本中大多数属于某一个类别,则该样本也属于这个类别。如上图中所示,对于绿色的点,观察与它距离最近的三个点,其中两个为红色三角形,则判定绿色的点也属于红色三角形所属的类。
KNN中的K表示选择的最近邻数量,不同的K值对分类结果影响很大,同样如上图所示,如果选择K=3,图中实线圈所示,可将绿色样本判定为红色三角形类;如果选择K=5,图中虚线圈所示,蓝色方块数量较多,可判定属于蓝色方块所属类。可见选择不同的K值,可以产生不同的分类结果。
这种基于记忆的学习算法最明显的优点在于可以快速的适应新的训练数据。缺点也显而易见,随着样本数量的增多,计算复杂度也随之增加,必须使用高效的数据结构(如KD Tree等)才能一定程度上提高计算速度。但随着训练样本数量的增多,不仅对存储空间占用明显,数据从硬盘调度时间也会极大影响计算速度。
此外,KNN还具有精度高,即使与SVM/DF/RF相比也好不逊色,且随着K值得增加,算法对异常值的容忍度也越来越高。KNN还有一个明显特点就是,只要给定训练集、距离度量、K值以及分类决策,其分类结果是唯一的,故不适合作为集成学习中的弱学习器。
1.2 KNN实现流程
KNN算法描述如下:
输入:训练数据集 T = { ( x i , y i ) , i = 1 , 2 , 3 , . . . , N } T = \{(x_i,y_i),i=1,2,3,...,N\} T={
(xi,yi),i=1,2,3,...,N},其中 x i ∈ R n x_i\isin R^n xi∈Rn为实例的特征向量, y i ∈ { c i , i = 1 , 2 , 3 , . . . , K } y_i\isin\{c_i,i=1,2,3,...,K\} yi∈{
ci,i=1,2,3,...,K}\为样本所属类别。
输出:实例x所属于的类别y。
根据给定的距离度量,在训练集T中找出与x最近的K个点,涵盖这K个点的x的领域记为 N k ( x ) N_k(x) Nk(x)。
根据分类决策(如多数表决等)决定x所属的类别y。
y = a r g m a x c i ∑ x ∈ N i ( x ) I ( y i = c j ) i = 1 , 2 , 3 , . . . , N ; j = 1 , 2 , 3 , . . . , K y = arg \underset{c_i}{max}\underset{x\isin N_i(x)}{\sum}{I(y_i = c_j)} \\ i = 1,2,3,...,N; j=1,2,3,...,K y=argcimaxx∈Ni(x)∑I(yi=cj)i=1,2,3,...,N;j=1,2,3,...,K
上式中, I I I为指示函数,即当 y i = c j y_i=c_j yi=cj时 I = 1 I=1 I=1,否者 I = 0 I=0 I=0。
从以上流程中可以看出,当训练集、距离度量、K值和分类决策确定后,对于任何一个输入实例。其所属的类是唯一确定的。使用KNN对数据进行处理前,还需要对数据进行标准化操作,归一化或标准化(标准正态分布)均可。在sklearn中已经集成了KNN模块,可以非常方便的调用:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(
n_neighbors=5,
p=2,
metric='minkowski'
)
knn.fit(X_train_std, y_train)代码中,n_neighbors表示近邻数,即为K值,metric表示采用的度量,此为闵可夫斯基距离,P为闵可夫斯基距离的权值。
1.3 KNN与度量
距离度量的选择对于KNN分类结果的影响不言而喻,常用的度量包括以下几种。
闵可夫斯基距离
闵可夫斯基距离(Minkovski Distance),又称闵式距离,不是一种距离,是一类距离的定义。对于两个n维变量 a ( x 11 , x 12 , . . . , x 1 n ) a(x_{11},x_{12},...,x_{1n}) a(x11,x12,...,x1n)和 b ( x 21 , x 22 , . . . , x 2 n ) b(x_{21},x_{22},...,x_{2n}) b(x21,x22,...,x2n)之间的闵式距离定义为:
d 12 = ( ∑ n k = 1 ∣ x 1 k − x 2 k ∣ p ) 1 p d_{12} = \left( \underset{k=1}{\overset{n}{\sum}}|x_{1k} - x_{2k}|^p \right)^{\frac{1}{p}} d12=(k=1∑n∣x1k−x2k∣p)p1
其中p是一个变参数:
当 p = 1 p=1 p=1时,闵式距离为曼哈顿距离;
当 p = 2 p=2 p=2时,闵式距离为欧氏距离;
当 p = + ∞ p=+ \infty p=+∞,闵式距离就变为切比雪夫距离,即对应参数相减的绝对值最大值:
L p = m a x ∣ x i ( l ) − x j ( l ) ∣ l L_p = \underset{l}{max|x_i^{(l)} - x_j^{(l)}|} Lp=lmax∣xi(l)−xj(l)∣
马氏距离
根据经验我们知道,如果数据没有进行标准化操作,不同特征的度量标准没有统一,直接使用欧式距离进行度量会导致判断出错。马氏距离是一种有效的计算两个位置样本相似度的方法。与欧式距离不同的是其考虑到各种特性之间的联系,并且这种联系与尺度无关,即独立于测量尺度。
先回顾一些协方差的定义, C o v ( X , Y ) = E [ ( X − μ x ) ( Y − μ y ) ] Cov(X,Y) = E[(X - \mu_x)(Y - \mu_y)] Cov(X,Y)=E[(X−μx)(Y−μy)]协方差用于衡量两个变量的总体误差,方差是协方差的一种特殊情况。简单的描述就是:两个变量在变化过程中是否为同向变化?同向或反向变化的程度如何?丛数值来看,协方差数值越大,说明两个变量同向变化的程度就越大,反之亦然。协方差代表了两个变量之间是否同时偏离均值,以及偏离的方向是同向还是反向。
马氏距离的定义为,用来衡量一个样本P和数据分布D的集合的距离。假设样本点为: x → = ( x 1 , x 2 , x 3 , . . . , x N ) T \overrightarrow{x} = (x_1,x_2,x_3,...,x_N)^T x=(x1,x2,x3,...,xN)T,数据集的分布的均值为: μ → = ( μ 1 , μ 2 , μ 3 , . . . , μ N ) T \overrightarrow{\mu} = (\mu_1,\mu_2,\mu_3,...,\mu_N)^T μ=(μ1,μ2,μ3,...,μN)T,协方差矩阵为S,此时协方差矩阵S中的元素为数据集中各个特征向量之间的协方差。则这个样本P与数据集合的马氏距离为:
D M ( x → ) = ( x → − μ → ) T S − 1 ( x → − μ → ) D_{\tiny M}(\overrightarrow{x}) = \sqrt{(\overrightarrow{x} - \overrightarrow{\mu})^{\tiny T}S^{\tiny{-1}}(\overrightarrow{x} - \overrightarrow{\mu})} DM(x)=(x−μ)TS−1(x−μ)
马氏距离也可以用来衡量两个来自同一分布的样本x和y之间的相似性:
d ( x → , y → ) = ( x → − y → ) T S − 1 ( x → − y → ) d(\overrightarrow{x},\overrightarrow{y}) = \sqrt{(\overrightarrow{x} - \overrightarrow{y})^{\tiny T}S^{\tiny{-1}}(\overrightarrow{x} - \overrightarrow{y})}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









