视频结构化与非线性编辑部分
镜头检测
镜头是视频流数据的最小物理数据单元,所谓镜头检测就是给定有n个镜头的视频V,找到每个镜头的开始和结尾部分。也被称作边界检测(boundary detection)或转换检测(transition detection)。
镜头边缘检测算法的实质及核心问题
实质:找到一种或几种良好的视频图像特征,通过判断相邻图像帧之间的特征是否发生剧烈变化,来完成视频镜头边缘检测任务。
核心问题:如何选择特征,如何定义相似度函数
//或者是关键问题:(1) 自适应阈值 (2)渐变镜头数学模型
镜头、关键帧、场景、组
镜头(Shot):摄像机拍下的不间断帧序列,是视频数据流进一步结构化的基础结构层。
关键帧(Key Frame):可以用来代表镜头内容的图像。
场景(Scene):语义上相关和时间上相邻的若干组镜头组成了一个场景。场景是视频所蕴含的高层抽象概念和语义的表达。
组(Group):介于物理镜头和语义场景之间的结构。
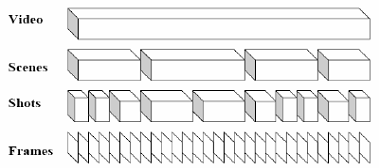
视频结构化分析包含哪些基本步骤、内容(又:视频目录生成构造的主要步骤)
镜头边缘检测
关键帧提取
时空特征提取
时间可适性成组
场景结构构造
镜头空间特征和时间特征的区别
镜头时间特征:包含运动信息,即镜头中前后两帧的差异累积
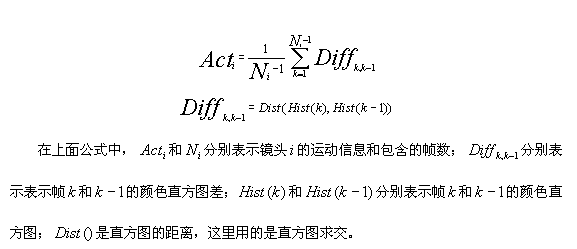
镜头空间特征:

如何匹配视频镜头之间的相似度
视觉相似性(颜色直方图等空间特征)
时间局部性(如运动相似度)
镜头可用关键帧代表,也用聚类质心。
视频时序结构图构造的主要步骤
视频解码
视频切分
关键帧提取
视频聚类分析
构造时序图
按照时序图浏览
镜头边缘检测算法
绝对帧间差法
相邻图像所有像素和的差,大于某一阈值,发生较大变化。
图像像素差法
先统计图像对应像素变化超过阈值像素点个数,再统计这个个数是否超过某一特定阈值,如果是,那么发生较大变化。
图像数值差法
将图像分成若干个子块区域,在这些区域中比较对应像素数值的差别。
颜色直方图法
直方图差;带权重的直方图差;直方图的交(两者取小的)
双阈值法
高阈值检测突变镜头,低阈值确定渐变镜头起始。
关键帧提取算法
镜头边界法
镜头中第一帧和最后一帧作为关键帧
颜色特征法
较多颜色特征(直方图)转变,作为关键帧。
运动分析法
相机焦距变化:选择首尾两帧作为关键帧; 相机角度变化:与上一帧重叠小于30%,作为关键帧
聚类的关键帧提取
常用K-means。求帧与质心距离,距离大形成新的聚类,否则加入原有聚类;每次计算后都更新质心;非监督过程。
渐变镜头的数学模型
Dissolve的数学模型:
(f(x,y)场景A g(x,y) 场景B L1:场景A持续时间,L2:场景B持续时间,F:场景A,B Dissolve持续时间)
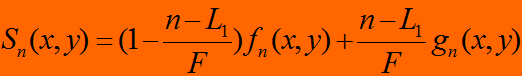
均值:
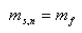 (
(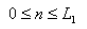 )
)
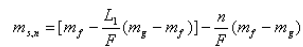 (
(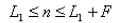 )
)
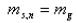 (
(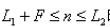 )
)
方差:
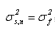 ()
()
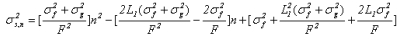 ()
()
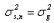 ()
()
视频数据压缩部分
无损压缩、有损压缩概念
无损压缩:压缩的数据和原始数据完全一样。
有损压缩:压缩的数据和原始数据不相同,但非常相近。
YUV色彩模型
Y代表灰度,UV代表色度。Y保持不变,按一定比例采样色度,如每个方向上编码原来一半的分辨率,则U,V都取原来的1/4数据。
压缩中量化的概念和方法
压缩中量化的概念:将数字按给定规律规整到某一特定范围。
方法(量化表):
H.261
MPEG-1
视频数据在时序上压缩的方法有哪些?
差分编码
运动补偿(基本思想与具体步骤)
压缩视频中I、B、P帧的定义,区别,特点
I :关键帧。解码时直接读取。
B:双向差别帧,本帧与前后帧的差别。
P:本帧与前一帧的区别。解码时与前一帧叠加。
如何利用YUV色彩模型压缩视频数据
Y:亮度
U和V:红色蓝色色差值
Y选取选取,而UV个点采集,因为人眼对色差分辨率不高。
YUV:4:4:4 每个Y对应1个UV
YUV: 4:2:2 每2个Y对应1个UV
YUV:4:2:0 每4个Y对应1个UV
静态图像压缩(JPEG)方法的基本流程
转换到YUV颜色空间
采样(4:1:1)
分块(8X8)
离散余弦变换
zigzag扫描排序
量化(浮点变整数)
DC系数进行差分脉冲调制编码
DC系数中间格式计算
AC系数行程长度编码
AC系数中间格式计算
熵编码
给出一种简单的视频压缩方案
视频数据空间压缩的方法(与JPEG相似)
运动补偿方法的步骤
计算运动向量
搜索匹配子块
计算视频帧之间的残差
对残差进行编码传输
其它
离散信源的熵定义
Huffman编码的具体方法
编码时,从最小概率两个符号开始,其中一个支路为0,另一个为1,再把两支路合并,重复以上操作。
Run-length编码的具体方法
(X,Y) , X代表数字,Y代表出现了几次
运动补偿中子块匹配具体方法
方法一:直接搜索,对子块两两进行匹配计算,找到最小MAD,注:(2p+1)*(2p+1)窗口
方法二:对数搜索,先计算偏移为offset的9个子块的匹配,找到最小MAD,然后质心转移到该块,同时offset减为原来的一半,继续计算。
方法三:分层搜索,第一层是原图,后几层是对上一层进行下采样,取原来长宽的一半。在每层找最小MAX。
————————————————————————————————————————————————————————————————————
语音编码的理论依据
编码方式是采样,然后模数变换,但如果不处理,编码量会很大,所以需要进行压缩,之所以能进行压缩,是因为
(1)语音信号在时域存在冗余
(2)语音信号在频域存在冗余
(3)人的听觉特征:掩蔽效应(一个频率很强,很难听到相邻频度的);对不同频率敏感度不同;对语音相位变化不敏感
人对音量强弱的主观感受受哪些因素影响
频率音色
短时平稳假设
语音信号特性是随时间变化的,本质上是一个非平稳过程,但不同的语音是由人的口腔肌肉运动构成声道的某种形状而产生的响应,而这种肌肉晕哦东频率相对于语音频率来说是缓慢的,因而在一个短时间范围内,其特性基本保持不变,即相对稳定,可以视作一个准稳态过程。基于这样的考虑,对语音信号进行分段考虑,每一段称为一帧,一般假设为10-30ms。
语音信号处理方法
频域 时域 实频域
语音信号时域分析
预处理
短时加窗
能量
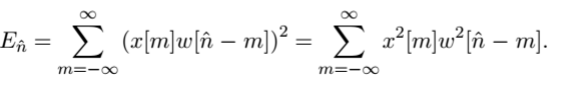
过零率
一个短时帧内,离散采样信号由正到负和由负到正的次数。可以基本反应平均频率。
端点检测
在语音信号中确定起始点,并把语音和非语音时段区分开来。
1.基于短时能量和短时过零率的端点检测:语音段能量比噪声段能量大,可以很好区分;过零率粗略描述频率,判别清音和浊音,有声和无声;过零率检测清音,短时能量检测浊音,两者配合。开始出在静音段,两者之一超过最低门限,进入过渡段,都降到门限之下,回到静音段。两者之一超过高门限,进入语音段,这时若两者都降到门限下,则为噪声段。
2.倒谱特征端点检测。倒谱距离代替短时能量。
基频 - 自相关法
最低且最强的频率。
短时傅里叶分析
恢复
语图
横坐标时间,纵坐标频率。
将语音分成很多帧,每帧对应一个频谱,将其映射到灰度表示,添加时间维度,得到随时间变化的频谱图。
提取频谱的包络(连接共振峰点的平滑曲线),也就是将频谱分为包络(低频) + 频谱细节(高频)。
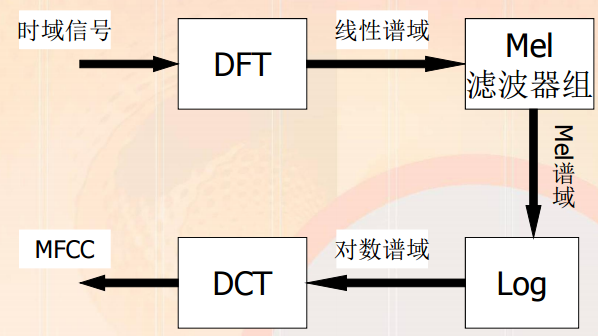
mel频率倒谱系数MFCC
1)预加重
分帧(10-30ms)
加窗(hamming)
目的:高频部分需要增益
2)对短时分析窗进行DFT得到频谱
3)频谱通过Mel滤波器得到Mel频谱
Mel频率是基于人类听觉感知实验得到的,只关注某些特定频率分量。
人类听觉:1kHz以上线性,1kHz以上对数
4)倒谱分析,取对数,做DCT变换,取2-13个系数为MFCC系数。
均值归一化。
ELSE
对数能量
帧能量
帧间差
一阶差分与二阶差分
动态时间规整(DTW,dynamic time warping)
非线性时间规整模式匹配算法:将时间规整与距离测度结合起来,采用优化技术,以最优匹配为目标,寻找最优时间规整函数。
D[c(k)]=d[c(k)] + minD[c(k-1)]
适用于特定人,基元较少场合,用于孤立词识别;计算量大,依赖端点检测,依赖原本发音,无法动态训练,无充分利用时序动态特性。
VQ(Vector Quantization)
将某一区域(范围)内矢量归为一类。
基本要素:聚类,量化。聚类指生成码本,对特征矢量空间进行划分;量化指参照码本进行归类的过程。
二维矢量空间中,有6类矢量,每一类一个中心(室心),对应一个码字,矢量集合组成码本(codebook)
归类主要看靠近哪一矢量。
常用参数:LPCC,,MPCC等的矢量表示。
隐式马尔可夫模型(HMM):
MM:状态可见,即观测结果。
HMM:状态不可见,状态之间转移仍然是概率的;输出是概率的函数。
离散HMM,连续密度HMM,半连续HMM
基本要素:
状态S:所有状态构成了状态空间
初始状态概率:1(初始)时刻系统处于状态Sl的概率
状态转移矩阵:aij --- n时刻系统在Si状态下,n+1时刻系统转移到Sj的概率:
观察矢量序列:任意时刻,系统状态xn隐藏在内部,外界能得到一个观察矢量y
HMM产生Y的概率:
问题1:训练问题
-根据已知观测确定模型参数
-Baum-Welch算法
问题2:估计问题
-根据已知模型求位置观测似然度
-Forward-Backward算法
问题3:最优路径搜索,状态序列分割问题
-Viterbi算法
隐藏状态转移,输出特定状态下特征。
当前状态只与前一状态有关,而与更早的状态无关。
当前状态的输出只与当前状态有关,而与其它任何状态均无关。(独立性)
————————————————————————————————————————————————————————————————————
数字音乐
音乐的基本要素
音高(频率),音强(振幅),音长(时值),音色(发声体谐波特性)
音乐制作流程
作曲作词,编曲,录音,混音
音乐合成软件
Overture, SONAR, AU
语言编程
基于Nyquist的音乐合成(lisp,基本声音的合成),openAL(三维音效),matlab, Flash Action Script
(play(osc 69)) 播放单音节
(play(scale 0.1 (osc 69))) 调节音量
(play(stretch 0.1(osc 69))) 调节播放时间
(play(seq(osc 50)(osc 69))) 连续播放
(play(sim(osc 69)(osc 50))) 声音叠加
(play(sim (at 0.0 (note c4 0.2))
(at 0.5 (note c1 0.2))
(at 1.0 (note c4 0.2))
))
openAL
alutInit(NULL,0);初始化
载入wav并绑定
alutLoadWAVFile("ccc.wav",&format,&data,&size,&freq,&loop);
alBufferData(Buffers[CCZ],format,data,size,freq);
alSourcei(Sources[CCZ], AL_BUFFER,Biffers[CCZ]);
设置参数
alListenerfv(AL_POSITION,ListenerPos);
alSourcef(Sources[CCZ],AL_PITCH,1.0f):
音乐识别
节奏:组织起来音的长短关系
旋律:长短,高低,强弱不同的一连串乐音有组织的进行
和声:和弦(三个或以上乐音组合) + 和声进行(和弦的横向组织)
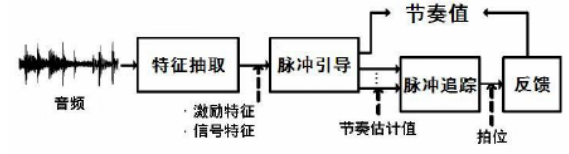
节奏识别
框架:
特征提取:时域分析 / 频域分析
音准评分
旋律
抢拍与慢拍
节奏分析
演唱情绪
声音圆润
语音识别(歌词)
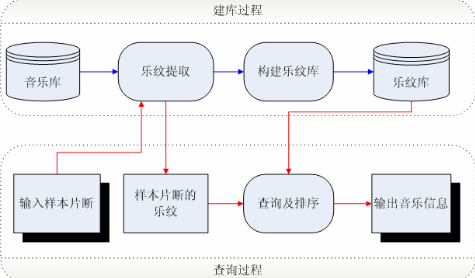
乐纹检索
乐纹:代表一段音乐重要声学特征的基于内容的紧致数学签名。
(经过处理后仍能识别,不同歌曲区别性大)
通过特征点对索引技术构建乐纹库; 三重链表查询。
哼唱检索
三层表示:
底层:基频
符号层:综合基频曲线,谐波和能量等信息切分成格式化音符序列。
乐句:寻找轮廓因子。
基于轮廓因子检索。Midomi公司。







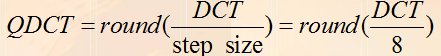

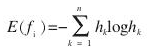
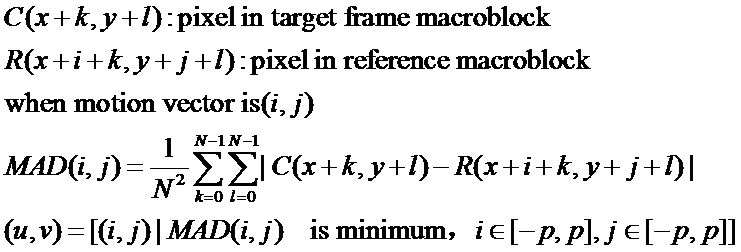
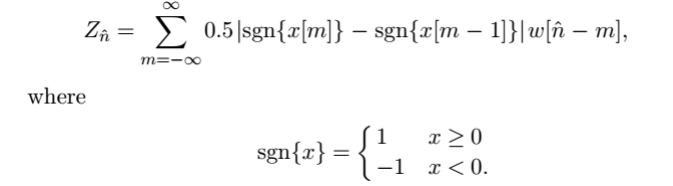
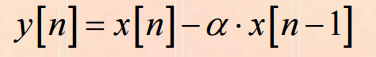
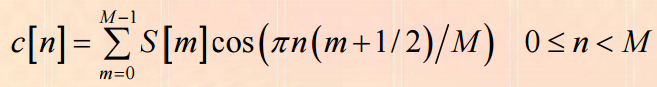
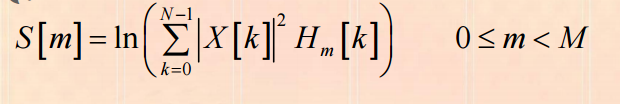

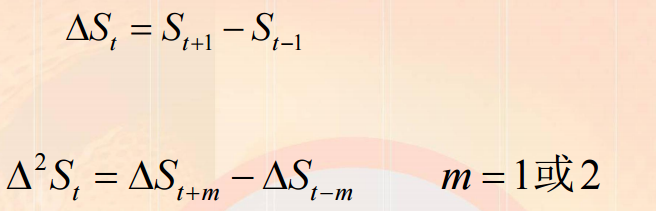
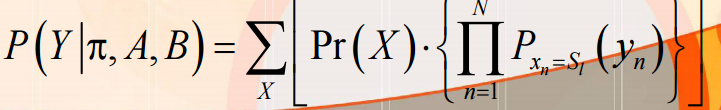














 4593
4593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









