






EM算法如何呢?比如说食堂的大师傅炒了一份菜,要等分成两份给两个人吃,显然没有必要拿来天平一点一点的精确的去称分量,最简单的办法是先随意的把菜分到两个碗中,然后观察是否一样多,把比较多的那一份取出一点放到另一个碗中,这个过程一直迭代地执行下去,直到大家看不出两个碗所容纳的菜有什么分量上的不同为止。EM算法就是这样,假设我们估计知道A和B两个参数,在开始状态下二者都是未知的,并且知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
教材云:
极大似然估计法是求估计值的另一种方法,最早由高斯(R.A,Gauss)提出,后来为费史(Fisher)在1912年重新提出,并证明该方法的一些性质.它是建立在极大似然原理基础上的一个统计方法.
极大似然原理:一个随机试验有若干种可能的结果A,B,C,….若在一次试验中,结果A出现,则一般认为试验条件对A出现有利,也即A出现的概率很大.
例子:
设甲箱中有99个白球,1个黑球;乙箱中有1个白球,99个黑球.现随机取出一箱,再从中随机取出一球,结果是黑球,这时我们自然更多地相信这个黑球是取自乙箱的.
因此极大似然估计就是要选取这样的数值作为参数的估计值,使所选取的样本在被选的总体中出现的可能性为最大,或者换句话说叫:已经出现的情况应该具有最大的概率。
一般步骤:
(1) 写出似然函数,L是关于样本和待估参数的函数;
(2) 对似然函数取对数,并整理;
(3) 求导数,解似然方程
由于样本x1,x2,x3...等都同时出现,故待估参数的值应使该事件概率最大化。
转自:http://hi.baidu.com/xyp86/blog/item/8f5b1e1b75ce141c8618bf94.html
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variabl)。最大期望经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。最大期望算法经过两个步骤交替进行计算,第一步是计算期望(E),也就是将隐藏变量象能够观测到的一样包含在内从而计算最大似然的期望值;另外一步是最大化(M),也就是最大化在 E 步上找到的最大似然的期望值从而计算参数的最大似然估计。M 步上找到的参数然后用于另外一个 E 步计算,这个过程不断交替进行。
最大期望过程说明
我们用 表示能够观察到的不完整的变量值,用 表示无法观察到的变量值,这样 和 一起组成了完整的数据。 可能是实际测量丢失的数据,也可能是能够简化问题的隐藏变量,如果它的值能够知道的话。例如,在混合模型(Mixture Model)中,如果“产生”样本的混合元素成分已知的话最大似然公式将变得更加便利(参见下面的例子)。
估计无法观测的数据
让 代表矢量 θ: 定义的参数的全部数据的概率分布(连续情况下)或者概率集聚函数(离散情况下),那么从这个函数就可以得到全部数据的最大似然值,另外,在给定的观察到的数据条件下未知数据的条件分布可以表示为:
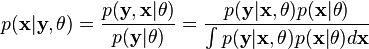
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/aladdina/archive/2009/05/02/4141114.aspx















 2712
2712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









