







目录
lambda表达式
lambda 表达式的概念和基本用法
lambda 表达式定义了一个匿名函数,并且可以捕获一定范围内的变量。lambda 表达式的语法形式可简单归纳如下:
[ capture ] ( params ) opt -> ret { body; };
其中 capture 是捕获列表,params 是参数列表,opt 是函数选项,ret 是返回值类型,body是函数体。
因此,一个完整的 lambda 表达式看起来像这样:
auto f = [](int a) -> int { return a + 1; };
std::cout << f(1) << std::endl; // 输出: 2
可以看到,上面通过一行代码定义了一个小小的功能闭包,用来将输入加 1 并返回。
其实很多时候,lambda 表达式的返回值是非常明显的。因此,C++11 中允许省略 lambda 表达式的返回值定义:
auto f = [](int a){ return a + 1; };
这样编译器就会根据 return 语句自动推导出返回值类型。
需要注意的是,初始化列表不能用于返回值的自动推导:
auto x1 = [](int i){ return i; }; // OK: return type is int
auto x2 = [](){ return { 1, 2 }; }; // error: 无法推导出返回值类型
这时我们需要显式给出具体的返回值类型。
另外,lambda 表达式在没有参数列表时,参数列表是可以省略的。因此像下面的写法都是正确的:
auto f1 = [](){ return 1; };
auto f2 = []{ return 1; }; // 省略空参数表
使用 lambda 表达式捕获列表
lambda 表达式还可以通过捕获列表捕获一定范围内的变量:
[] 不捕获任何变量。
[&] 捕获外部作用域中所有变量,并作为引用在函数体中使用(按引用捕获)。
[=] 捕获外部作用域中所有变量,并作为副本在函数体中使用(按值捕获)。
[=,&foo] 按值捕获外部作用域中所有变量,并按引用捕获 foo 变量。
[bar] 按值捕获 bar 变量,同时不捕获其他变量。
[this] 捕获当前类中的 this 指针,让 lambda 表达式拥有和当前类成员函数同样的访问权限。如果已经使用了 & 或者 =,就默认添加此选项。捕获 this 的目的是可以在 lamda 中使用当前类的成员函数和成员变量。
下面看一下它的具体用法,如下所示。
【实例】lambda 表达式的基本用法。
class A
{
public:
int i_ = 0;
void func(int x, int y)
{
auto x1 = []{ return i_; }; // error,没有捕获外部变量
auto x2 = [=]{ return i_ + x + y; }; // OK,捕获所有外部变量
auto x3 = [&]{ return i_ + x + y; }; // OK,捕获所有外部变量
auto x4 = [this]{ return i_; }; // OK,捕获this指针
auto x5 = [this]{ return i_ + x + y; }; // error,没有捕获x、y
auto x6 = [this, x, y]{ return i_ + x + y; }; // OK,捕获this指针、x、y
auto x7 = [this]{ return i_++; }; // OK,捕获this指针,并修改成员的值
}
};
int a = 0, b = 1;
auto f1 = []{ return a; }; // error,没有捕获外部变量
auto f2 = [&]{ return a++; }; // OK,捕获所有外部变量,并对a执行自加运算
auto f3 = [=]{ return a; }; // OK,捕获所有外部变量,并返回a
auto f4 = [=]{ return a++; }; // error,a是以复制方式捕获的,无法修改
auto f5 = [a]{ return a + b; }; // error,没有捕获变量b
auto f6 = [a, &b]{ return a + (b++); }; // OK,捕获a和b的引用,并对b做自加运算
auto f7 = [=, &b]{ return a + (b++); }; // OK,捕获所有外部变量和b的引用,并对b做自加运算
从上例中可以看到,lambda 表达式的捕获列表精细地控制了 lambda 表达式能够访问的外部变量,以及如何访问这些变量。
需要注意的是,默认状态下 lambda 表达式无法修改通过复制方式捕获的外部变量。如果希望修改这些变量的话,我们需要使用引用方式进行捕获。
一个容易出错的细节是关于 lambda 表达式的延迟调用的:
int a = 0;
auto f = [=]{ return a; }; // 按值捕获外部变量
a += 1; // a被修改了
std::cout << f() << std::endl; // 输出?
在这个例子中,lambda 表达式按值捕获了所有外部变量。在捕获的一瞬间,a 的值就已经被复制到f中了。之后 a 被修改,但此时 f 中存储的 a 仍然还是捕获时的值,因此,最终输出结果是 0。
如果希望 lambda 表达式在调用时能够即时访问外部变量,我们应当使用引用方式捕获。
从上面的例子中我们知道,按值捕获得到的外部变量值是在 lambda 表达式定义时的值。此时所有外部变量均被复制了一份存储在 lambda 表达式变量中。此时虽然修改 lambda 表达式中的这些外部变量并不会真正影响到外部,我们却仍然无法修改它们。
那么如果希望去修改按值捕获的外部变量应当怎么办呢?这时,需要显式指明 lambda 表达式为 mutable:
int a = 0;
auto f1 = [=]{ return a++; }; // error,修改按值捕获的外部变量
auto f2 = [=]() mutable { return a++; }; // OK,mutable
需要注意的一点是,被 mutable 修饰的 lambda 表达式就算没有参数也要写明参数列表。
lambda 表达式的类型
lambda 表达式的类型
lambda 表达式的类型在 C++11 中被称为“闭包类型(Closure Type)”。它是一个特殊的,匿名的非 nunion 的类类型。
因此,我们可以认为它是一个带有 operator() 的类,即仿函数。因此,我们可以使用 std::function 和 std::bind 来存储和操作 lambda 表达式:
std::function<int(int)> f1 = [](int a){ return a; };
std::function<int(void)> f2 = std::bind([](int a){ return a; }, 123);
另外,对于没有捕获任何变量的 lambda 表达式,还可以被转换成一个普通的函数指针:
using func_t = int(*)(int);
func_t f = [](int a){ return a; };
f(123);
lambda 表达式可以说是就地定义仿函数闭包的“语法糖”。它的捕获列表捕获住的任何外部变量,最终均会变为闭包类型的成员变量。而一个使用了成员变量的类的 operator(),如果能直接被转换为普通的函数指针,那么 lambda 表达式本身的 this 指针就丢失掉了。而没有捕获任何外部变量的 lambda 表达式则不存在这个问题。
这里也可以很自然地解释为何按值捕获无法修改捕获的外部变量。因为按照 C++ 标准,lambda 表达式的 operator() 默认是 const 的。一个 const 成员函数是无法修改成员变量的值的。而 mutable 的作用,就在于取消 operator() 的 const。
需要注意的是,没有捕获变量的 lambda 表达式可以直接转换为函数指针,而捕获变量的 lambda 表达式则不能转换为函数指针。看看下面的代码:
typedef void(*Ptr)(int*);
Ptr p = [](int* p){delete p;}; // 正确,没有状态的lambda(没有捕获)的lambda表达式可以直接转换为函数指针
Ptr p1 = [&](int* p){delete p;}; // 错误,有状态的lambda不能直接转换为函数指针
上面第二行代码能编译通过,而第三行代码不能编译通过,因为第三行的代码捕获了变量,不能直接转换为函数指针。
Lambda表达式工作原理
编译器会把一个lambda表达式生成一个匿名类的匿名对象,并在类中重载函数调用运算符,实现了一个operator()方法。
auto print = []{cout << "Hello World!" << endl; };
编译器会把上面这一句翻译为下面的代码:
class print_class
{
public:
void operator()(void) const
{
cout << "Hello World!" << endl;
}
};
//用构造的类创建对象,print此时就是一个函数对象
auto print = print_class();
Lambda表达式的优缺点
优点:可以直接在需要调用函数的位置定义短小精悍的函数,而不需要预先定义好函数
使用Lamdba表达式变得更加紧凑,结构层次更加明显、代码可读性更好
缺点:Lamdba表达式语法比较灵活,增加了阅读代码的难度。
对于函数复用无能为力
C++仿函数
仿函数(functor)又称为函数对象(function object)是一个能行使函数功能的类。仿函数的语法几乎和我们普通的函数调用一样,不过作为仿函数的类,都必须重载operator()运算符,仿函数与Lamdba表达式的作用是一致的。举个例子:
#include <iostream>
#include <string>
using namespace std;
class Functor
{
public:
void operator() (const string& str) const
{
cout << str << endl;
}
};
int main()
{
Functor myFunctor;
myFunctor("Hello world!");
return 0;
}
右值引用
C++左值和右值
在 C++ 或者 C 语言中,一个表达式(可以是字面量、变量、对象、函数的返回值等)根据其使用场景不同,分为左值表达式和右值表达式。确切的说 C++ 中左值和右值的概念是从 C 语言继承过来的。
值得一提的是,左值的英文简写为“lvalue”,右值的英文简写为“rvalue”。很多人认为它们分别是"left value"、“right value” 的缩写,其实不然。lvalue 是“loactor value”的缩写,可意为存储在内存中、有明确存储地址(可寻址)的数据,而 rvalue 译为 “read value”,指的是那些可以提供数据值的数据(不一定可以寻址,例如存储于寄存器中的数据)。
通常情况下,判断某个表达式是左值还是右值,最常用的有以下 2 种方法。
- 可位于赋值号(=)左侧的表达式就是左值;反之,只能位于赋值号右侧的表达式就是右值。举个例子:
int a = 5;
5 = a; //错误,5 不能为左值
其中,变量 a 就是一个左值,而字面量 5 就是一个右值。值得一提的是,C++ 中的左值也可以当做右值使用,例如:
int b = 10; // b 是一个左值
a = b; // a、b 都是左值,只不过将 b 可以当做右值使用
- 有名称的、可以获取到存储地址的表达式即为左值;反之则是右值。
以上面定义的变量 a、b 为例,a 和 b 是变量名,且通过 &a 和 &b 可以获得他们的存储地址,因此 a 和 b 都是左值;反之,字面量 5、10,它们既没有名称,也无法获取其存储地址(字面量通常存储在寄存器中,或者和代码存储在一起),因此 5、10 都是右值。
C++右值引用
前面提到,其实 C++98/03 标准中就有引用,使用 “&” 表示。但此种引用方式有一个缺陷,即正常情况下只能操作 C++ 中的左值,无法对右值添加引用。举个例子:
int num = 10;
int &b = num; //正确
int &c = 10; //错误
如上所示,编译器允许我们为 num 左值建立一个引用,但不可以为 10 这个右值建立引用。因此,C++98/03 标准中的引用又称为左值引用。
注意,虽然 C++98/03 标准不支持为右值建立非常量左值引用,但允许使用常量左值引用操作右值。也就是说,常量左值引用既可以操作左值,也可以操作右值,例如:
int num = 10;
const int &b = num;
const int &c = 10;
我们知道,右值往往是没有名称的,因此要使用它只能借助引用的方式。这就产生一个问题,实际开发中我们可能需要对右值进行修改(实现移动语义时就需要),显然左值引用的方式是行不通的。
为此,C++11 标准新引入了另一种引用方式,称为右值引用,用 “&&” 表示。
话说,C++标准委员会在选定右值引用符号时,既希望能选用现有 C++ 内部已有的符号,还不能与 C++ 98 /03 标准产生冲突,最终选定了 2 个 ‘&’ 表示右值引用。
需要注意的,和声明左值引用一样,右值引用也必须立即进行初始化操作,且只能使用右值进行初始化,比如:
int num = 10;
//int && a = num; //右值引用不能初始化为左值
int && a = 10;
和常量左值引用不同的是,右值引用还可以对右值进行修改。例如:
int && a = 10;
a = 100;
cout << a << endl;
程序输出结果为 100。
另外值得一提的是,C++ 语法上是支持定义常量右值引用的,例如:
const int&& a = 10;//编译器不会报错
但这种定义出来的右值引用并无实际用处。一方面,右值引用主要用于移动语义和完美转发,其中前者需要有修改右值的权限;其次,常量右值引用的作用就是引用一个不可修改的右值,这项工作完全可以交给常量左值引用完成。
学到这里,一些读者可能无法记清楚左值引用和右值引用各自可以引用左值还是右值,这里给大家一张表格,方便大家记忆:
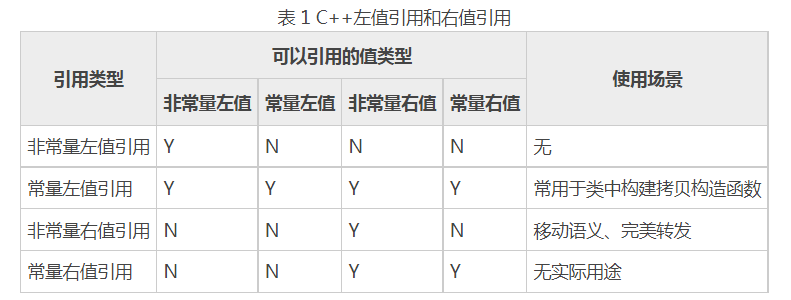
表中,Y 表示支持,N 表示不支持。
final和override关键字
override
当在父类中使用了虚函数的时候,会出现需要在某个子类中对这个虚函数进行重写的情况,当我们重写的时候,一不小心把函数名写错了,但是编译器并不会报错,因为它并不知道你的目的是重写虚函数,而是把它当成了新的函数。这时,override的作用就出来了,它指定了子类的这个虚函数是重写的父类的,如果你名字不小心写错了的话,编译器是不会编译通过的。
class A
{
virtual void foo();
};
class B : public A
{
virtual void f00(); //OK,这个函数是B新增的,不是继承的
virtual void f0o() override; //Error, 加了override之后,这个函数一定是继承自A的,A找不到就报错
};
final
当不希望某个类被继承,或不希望某个虚函数被重写,可以在类名和虚函数后添加final关键字,添加final关键字后被继承或重写,编译器会报错。
class Base
{
virtual void foo();
};
class A : public Base
{
void foo() final; // foo 被override并且是最后一个override,在其子类中不可以重写
};
class B final : A // 指明B是不可以被继承的
{
void foo() override; // Error: 在A中已经被final了
};
class C : B // Error: B is final
{
};















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









