







浮点数与IEEE754 (<-reference link)
浮点数
1. 什么是浮点数
在计算机系统的发展过程中,曾经提出过多种方法表达实数。典型的比如相对于浮点数的定点数(Fixed Point Number)。在这种表达方式中,小数点固定的位于实数所有数字中间的某个位置。货币的表达就可以使用这种方式,比如 99.00 或者 00.99 可以用于表达具有四位精度(Precision),小数点后有两位的货币值。由于小数点位置固定,所以可以直接用四位数值来表达相应的数值。SQL 中的 NUMBER 数据类型就是利用定点数来定义的。还有一种提议的表达方式为有理数表达方式,即用两个整数的比值来表达实数。
定点数表达法的缺点在于其形式过于僵硬,固定的小数点位置决定了固定位数的整数部分和小数部分,不利于同时表达特别大的数或者特别小的数。最终,绝大多数现代的计算机系统采纳了所谓的浮点数表达方式。这种表达方式利用科学计数法来表达实数,即用一个尾数(Mantissa,尾数有时也称为有效数字——Significand;尾数实际上是有效数字的非正式说法),一个基数(Base),一个指数(Exponent)以及一个表示正负的符号来表达实数。比如 123.45 用十进制科学计数法可以表达为 1.2345 × 102 ,其中 1.2345 为尾数,10 为基数,2 为指数。浮点数利用指数达到了浮动小数点的效果,从而可以灵活地表达更大范围的实数。
2. IEEE 浮点数
计算机中是用有限的连续字节保存浮点数的。在 IEEE 标准中,浮点数是将特定长度的连续字节的所有二进制位分割为特定宽度的符号域,指数域和尾数域三个域,其中保存的值分别用于表示给定二进制浮点数中的符号,指数和尾数。这样,通过尾数和可以调节的指数(所以称为"浮点")就可以表达给定的数值了。
IEEE 754 指定:
n 两种基本的浮点格式:单精度和双精度。
Ø IEEE 单精度格式具有 24 位有效数字精度,并总共占用 32 位。
Ø IEEE 双精度格式具有 53 位有效数字精度,并总共占用 64 位。
n 两种扩展浮点格式:单精度扩展和双精度扩展。此标准并未规定这些格式的精确精度和和大小,但它指定了最小精度和大小。例如,IEEE 双精度扩展格式必须至少具有 64 位有效数字精度,并总共占用至少 79 位。
具体的格式参见下面的图例:

3. 浮点格式
浮点格式是一种数据结构,用于指定包含浮点数的字段、这些字段的布局及其算术解释。浮点存储格式指定如何将浮点格式存储在内存中。IEEE 标准定义了这些格式,但具体选择哪种存储格式由实现工具决定。
汇编语言软件有时取决于所使用的存储格式,但更高级别的语言通常仅处理浮点数据类型的语言概念。这些类型在不同的高级语言中具有不同的名称,并且与表中所示的IEEE 格式相对应。
| IEEE 精度 | C、C++ | Fortran (仅限 SPARC) |
| 单精度 | float | REAL 或 REAL*4 |
| 双精度 | double | DOUBLE PRECISION 或 REAL*8 |
| 双精度扩展 | long double | REAL*16 |
IEEE 754 明确规定了单精度浮点格式和双精度浮点格式,并为这两种基本格式分别定义了一组扩展格式。表中显示的long double 和 REAL*16 类型适用于 IEEE 标准定义的一种双精度扩展格式。
3.1.单精度格式
IEEE 单精度格式由三个字段组成:23 位小数 f ; 8 位偏置指数 e ;以及 1 位符号 s。这些字段连续存储在一个 32 位字中(如下图所示)。

Ø 0:22 位包含 23 位小数 f,其中第 0 位是小数的最低有效位,第 22 位是最高有效位。
IEEE 标准要求浮点数必须是规范的。这意味着尾数的小数点左侧必须为 1,因此我们在保存尾数的时候,可以省略小数点前面这个 1,从而腾出一个二进制位来保存更多的尾数。这样我们实际上用 23 位长的尾数域表达了 24 位的尾数。
Ø 23:30 位包含 8 位偏置指数 e,第 23 位是偏置指数的最低有效位,第 30 位是最高有效位。
阶码用移码表示
8 位的指数为可以表达 0 到 255 之间的 256 个指数值。但是,指数可以为正数,也可以为负数。为了处理负指数的情况,实际的指数值按要求需要加上一个偏差(Bias)值作为保存在指数域中的值,单精度数的偏差值为 127;偏差的引入使得对于单精度数,实际可以表达的指数值的范围就变成 -127(0 - 偏差值127) 到 128 (255 - 偏差值127)之间(包含两端)。在本文中,最小指数和最大指数分别用 emin 和 emax 来表达。稍后将介绍实际的指数值 -127(保存为全0)以及 +128(保存为全 1)保留用作特殊值的处理。
Ø 最高的第 31 位包含符号位s。s为0表示数值为正数,而s为1则表示负数。
3.2.双精度格式
IEEE 双精度格式由三个字段组成:52 位小数 f ; 11 位偏置指数 e ;以及 1 位符号s。这些字段连续存储在两个 32 位字中(如下图所示)。在 SPARC 体系结构中,较高地址的 32 位字包含小数的 32 位最低有效位,而在 x86体系结构中,则较低地址的 32-位字包含小数的 32 位最低有效位。

如果用 f[31:0] 表示小数的 32 位最低有效位,则在这 32 位最低有效位中,第 0 位是整个小数的最低有效位,而第 31 位则是最高有效位。在另一个 32 位字中, 0:19 位包含 20 位小数的最高有效位 f[51:32],其中第 0 位是这20 位最高有效位中的最低有效位,而第 19 位是整个小数的最高有效位; 20:30 位包含11 位偏置指数 e,其中第 20 位是偏置指数的最低有效位,而第 30 位是最高有效位;最高的第 31 位包含符号位 s。
上图将这两个连续的 32 位字按一个 64 位字那样进行了编号,其中
Ø 0:51 位包含 52 位小数 f,其中第 0 位是小数的最低有效位,第 51 位是最高有效位。
IEEE 标准要求浮点数必须是规范的。这意味着尾数的小数点左侧必须为 1,因此我们在保存尾数的时候,可以省略小数点前面这个 1,从而腾出一个二进制位来保存更多的尾数。这样我们实际上用 52 位长的尾数域表达了 53 位的尾数。
Ø 52:62 位包含 11 位偏置指数 e,第 52 位是偏置指数的最低有效位,第 62 位是最高有效位。
11 位的指数为可以表达 0 到 2047 之间的2048个指数值。但是,指数可以为正数,也可以为负数。为了处理负指数的情况,实际的指数值按要求需要加上一个偏差(Bias)值作为保存在指数域中的值,单精度数的偏差值为1023;偏差的引入使得对于单精度数,实际可以表达的指数值的范围就变成 -1023到1024之间(包含两端)。在本文中,最小指数和最大指数分别用 emin 和 emax 来表达。稍后将介绍实际的指数值-1023(保存为全0)以及 +1024(保存为全 1)保留用作特殊值的处理。
Ø 最高的第 63 位包含符号位s。s为0表示数值为正数,而s为1则表示负数。
3.3.双精度扩展格式 (SPARC)
SPARC 浮点环境的四倍精度格式符合双精度扩展格式的 IEEE 定义。四倍精度格式占用 32 位字并包含以下三个字段:112 位小数 f、15 位偏置指数 e 和 1 位符号 s。这三个字段连续存储,如图2-3 所示。
地址最高的 32 位字包含小数的 32 位最低有效位,用 f[31:0] 表示。紧邻的两个 32 位字分别包含 f[63:32]和 f[95:64]。下面的 0:15 位包含小数的 16 位最高有效位 f[111:96],其中第 0 位是这 16 位的最低有效位,而第 15 位是整个小数的最高有效位。16:30 位包含 15 位偏置指数 e,其中第 16 位是该偏置指数的最低有效位,而第 30 位是最高有效位;第 31 位包含符号位 s。
下图将这四个连续的 32 位字按一个 128 位字那样进行了编号,其中 0:111 位存储小数 f ; 112:126 位存储15 位偏置指数 e ;而第 127 位存储符号位 s。

3.4.双精度扩展格式 (x86)
该浮点环境双精度扩展格式符合双精度扩展格式的 IEEE 定义。它包含四个字段:63 位小数 f、1 位显式前导有效数位 j、15 位偏置指数 e 以及 1 位符号 s。
在 x86 体系结构系列中,这些字段连续存储在十个相连地址的 8 位字节中。由于 UNIXSystem V Application Binary Interface Intel 386 Processor Supplement (Intel ABI) 要求双精度扩展参数,从而占用堆栈中三个相连地址的 32 位字,其中地址最高字的 16 位最高有效位未用,如下图所示。

地址最低的 32 位字包含小数的 32 位最低有效位 f[31:0],其中第 0 位是整个小数的最低有效位,而第 31 位则是 32 位最低有效位的最高有效位。地址居中的 32 位字中,0:30 位包含小数的 31 位最高有效位 f[62:32](其中第 0 位是这 31 位最高有效位的最低有效位,而第 30 位是整个小数的最高有效位);地址居中 32 位字的第 31 位包含显式前导有效数位 j。
地址最高的 32 位字中,0:14 位包含 15 位偏置指数 e,其中第 0 位是该偏置指数的最低有效位,而第 14 位是最高有效位;第 15 位包含符号位 s。虽然地址最高的 32 位字的最高 16 位未被 x86 体系结构系列使用,但如上所述,它们对于符合 Intel ABI 规定是至关重要的。
4. 将实数转换成浮点数
4.1 浮点数的规范化
同样的数值可以有多种浮点数表达方式,比如上面例子中的 123.45 可以表达为 12.345 × 101,0.12345 × 103 或者 1.2345 × 102。因为这种多样性,有必要对其加以规范化以达到统一表达的目标。规范的(Normalized)浮点数表达方式具有如下形式:
±d.dd...d × βe , (0 ≤ d i < β)
其中 d.dd...d 即尾数,β 为基数,e 为指数。尾数中数字的个数称为精度,在本文中用 p 来表示。每个数字 d 介于 0 和基数之间,包括 0。小数点左侧的数字不为 0。
基于规范表达的浮点数对应的具体值可由下面的表达式计算而得:
±(d 0 + d 1β-1 + ... + d p-1β-(p-1))βe , (0 ≤ d i < β)
对于十进制的浮点数,即基数 β 等于 10 的浮点数而言,上面的表达式非常容易理解,也很直白。计算机内部的数值表达是基于二进制的。从上面的表达式,我们可以知道,二进制数同样可以有小数点,也同样具有类似于十进制的表达方式。只是此时 β 等于 2,而每个数字 d 只能在 0 和 1 之间取值。比如二进制数1001.101 相当于 1 × 2 3 + 0 × 22 + 0 × 21 + 1 × 20 + 1 × 2-1 + 0 × 2-2 + 1 × 2-3,对应于十进制的 9.625。其规范浮点数表达为 1.001101 × 23。
4.2 根据精度表示浮点数
以上面的9.625为例,其规范浮点数表达为 1.001101 × 23,
因此按单精度格式表示为:
1 10000010 00110100000000000000000
同理按双精度格式表示为:
1 10000000010 0011010000000000000000000000000000000000000000000000
5. 特殊值
通过前面的介绍,你应该已经了解的浮点数的基本知识,这些知识对于一个不接触浮点数应用的人应该足够了。不过,如果你兴趣正浓,或者面对着一个棘手的浮点数应用,可以通过本节了解到关于浮点数的一些值得注意的特殊之处。
我们已经知道,单精度浮点数指数域实际可以表达的指数值的范围为 -127 到 128 之间(包含两端)。其中,值-127(保存为全0)以及 +128(保存为全1)保留用作特殊值的处理。本节将详细 IEEE 标准中所定义的这些特殊值。
浮点数中的特殊值主要用于特殊情况或者错误的处理。比如在程序对一个负数进行开平方时,一个特殊的返回值将用于标记这种错误,该值为 NaN(Not a Number)。没有这样的特殊值,对于此类错误只能粗暴地终止计算。除了 NaN 之外,IEEE 标准还定义了 ±0,±∞ 以及非规范化数(Denormalized Number)。
对于单精度浮点数,所有这些特殊值都由保留的特殊指数值 -127 和 128 来编码。如果我们分别用 emin 和 emax 来表达其它常规指数值范围的边界,即 -126 和 127,则保留的特殊指数值可以分别表达为 emin - 1 和 emax + 1; 。基于这个表达方式,IEEE 标准的特殊值如下所示:
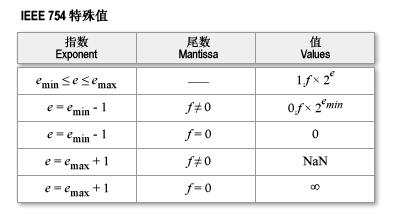
其中 f 表示尾数中的小数点右侧的(Fraction)部分。第一行即我们之前介绍的普通的规范化浮点数。随后我们将分别对余下的特殊值加以介绍。
5.1 NaN
NaN 用于处理计算中出现的错误情况,比如 0.0 除以 0.0 或者求负数的平方根。由上面的表中可以看出,对于单精度浮点数,NaN 表示为指数为 emax + 1 = 128(指数域全为 1),且尾数域不等于零的浮点数。IEEE 标准没有要求具体的尾数域,所以 NaN 实际上不是一个,而是一族。不同的实现可以自由选择尾数域的值来表达NaN,比如 Java 中的常量 Float.NaN 的浮点数可能表达为 01111111110000000000000000000000,其中尾数域的第一位为 1,其余均为 0(不计隐藏的一位),但这取决系统的硬件架构。Java 中甚至允许程序员自己构造具有特定位模式的 NaN 值(通过 Float.intBitsToFloat() 方法)。比如,程序员可以利用这种定制的 NaN 值中的特定位模式来表达某些诊断信息。
定制的 NaN 值,可以通过 Float.isNaN() 方法判定其为 NaN,但是它和 Float.NaN 常量却不相等。实际上,所有的 NaN 值都是无序的。数值比较操作符 <,<=,> 和 >= 在任一操作数为 NaN 时均返回 false。等于操作符== 在任一操作数为 NaN 时均返回 false,即使是两个具有相同位模式的 NaN 也一样。而操作符 != 则当任一操作数为 NaN 时返回 true。这个规则的一个有趣的结果是 x!=x 当 x 为 NaN 时竟然为真。
可以产生 NaN 的操作如下所示:
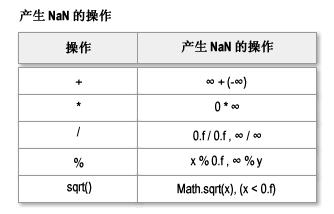
此外,任何有 NaN 作为操作数的操作也将产生 NaN。用特殊的 NaN 来表达上述运算错误的意义在于避免了因这些错误而导致运算的不必要的终止。比如,如果一个被循环调用的浮点运算方法,可能由于输入的参数问题而导致发生这些错误,NaN 使得 即使某次循环发生了这样的错误,也可以简单地继续执行循环以进行那些没有错误的运算。你可能想到,既然 Java 有异常处理机制,也许可以通过捕获并忽略异常达到相同的效果。但是,要知道,IEEE 标准不是仅仅为 Java 而制定的,各种语言处理异常的机制不尽相同,这将使得代码的迁移变得更加困难。何况,不是所有语言都有类似的异常或者信号(Signal)处理机制。
注意: Java 中,不同于浮点数的处理,整数的 0 除以 0 将抛出 java.lang.ArithmeticException 异常。
5.2 无穷
和 NaN 一样,特殊值无穷(Infinity)的指数部分同样为 emax + 1 = 128,不过无穷的尾数域必须为零。无穷用于表达计算中产生的上溢(Overflow)问题。比如两个极大的数相乘时,尽管两个操作数本身可以用保存为浮点数,但其结果可能大到无法保存为浮点数,而必须进行舍入。根据 IEEE 标准,此时不是将结果舍入为可以保存的最大的浮点数(因为这个数可能离实际的结果相差太远而毫无意义),而是将其舍入为无穷。对于负数结果也是如此,只不过此时舍入为负无穷,也就是说符号域为 1 的无穷。有了 NaN 的经验我们不难理解,特殊值无穷使得计算中发生的上溢错误不必以终止运算为结果。
无穷和除 NaN 以外的其它浮点数一样是有序的,从小到大依次为负无穷,负的有穷非零值,正负零(随后介绍),正的有穷非零值以及正无穷。除 NaN 以外的任何非零值除以零,结果都将是无穷,而符号则由作为除数的零的符号决定。
回顾我们对 NaN 的介绍,当零除以零时得到的结果不是无穷而是 NaN 。原因不难理解,当除数和被除数都逼近于零时,其商可能为任何值,所以 IEEE 标准决定此时用 NaN 作为商比较合适。
5.3 有符号的零
因为 IEEE 标准的浮点数格式中,小数点左侧的 1 是隐藏的,而零显然需要尾数必须是零。所以,零也就无法直接用这种格式表达而只能特殊处理。
实际上,零保存为尾数域为全为 0,指数域为 emin - 1 = -127,也就是说指数域也全为 0。考虑到符号域的作用,所以存在着两个零,即 +0 和 -0。不同于正负无穷之间是有序的,IEEE 标准规定正负零是相等的。
零有正负之分,的确非常容易让人困惑。这一点是基于数值分析的多种考虑,经利弊权衡后形成的结果。有符号的零可以避免运算中,特别是涉及无穷的运算中,符号信息的丢失。举例而言,如果零无符号,则等式 1/(1/x) = x 当x = ±∞ 时不再成立。原因是如果零无符号,1 和正负无穷的比值为同一个零,然后 1 与 0 的比值为正无穷,符号没有了。解决这个问题,除非无穷也没有符号。但是无穷的符号表达了上溢发生在数轴的哪一侧,这个信息显然是不能不要的。零有符号也造成了其它问题,比如当 x=y 时,等式1/x = 1/y 在 x 和 y 分别为 +0 和 -0 时,两端分别为正无穷和负无穷而不再成立。当然,解决这个问题的另一个思路是和无穷一样,规定零也是有序的。但是,如果零是有序的,则即使 if (x==0) 这样简单的判断也由于 x 可能是 ±0 而变得不确定了。两害取其轻者,零还是无序的好。
5.4 非规范化数
我们来考察浮点数的一个特殊情况。选择两个绝对值极小的浮点数,以单精度的二进制浮点数为例,比如 1.001 × 2-125 和 1.0001 × 2-125 这两个数(分别对应于十进制的 2.6448623 × 10-38 和 2.4979255 × 10-38)。显然,他们都是普通的浮点数(指数为 -125,大于允许的最小值 -126;尾数更没问题),按照 IEEE 754 可以分别保存为00000001000100000000000000000000(0x1100000)和 00000001000010000000000000000000(0x1080000)。
现在我们看看这两个浮点数的差值。不难得出,该差值为 0.0001 × 2-125,表达为规范浮点数则为 1.0 × 2-129。问题在于其指数大于允许的最小指数值,所以无法保存为规范浮点数。最终,只能近似为零(Flush to Zero)。这中特殊情况意味着下面本来十分可靠的代码也可能出现问题:
if (x != y) {
z = 1 / (x -y);
}
正如我们精心选择的两个浮点数展现的问题一样,即使 x 不等于 y,x 和 y 的差值仍然可能绝对值过小,而近似为零,导致除以 0 的情况发生。
为了解决此类问题,IEEE 标准中引入了非规范(Denormalized)浮点数。规定当浮点数的指数为允许的最小指数值,即 emin 时,尾数不必是规范化的。比如上面例子中的差值可以表达为非规范的浮点数 0.001 × 2-126,其中指数-126 等于 emin。注意,这里规定的是"不必",这也就意味着"可以"。当浮点数实际的指数为 emin,且指数域也为emin 时,该浮点数仍是规范的,也就是说,保存时隐含着一个隐藏的尾数位。为了保存非规范浮点数,IEEE 标准采用了类似处理特殊值零时所采用的办法,即用特殊的指数域值 emin - 1 加以标记,当然,此时的尾数域不能为零。这样,例子中的差值可以保存为 00000000000100000000000000000000(0x100000),没有隐含的尾数位。
有了非规范浮点数,去掉了隐含的尾数位的制约,可以保存绝对值更小的浮点数。而且,也由于不再受到隐含尾数域的制约,上述关于极小差值的问题也不存在了,因为所有可以保存的浮点数之间的差值同样可以保存。
6. 范围和精度
很多小数根本无法在二进制计算机中精确表示(比如最简单的 0.1)由于浮点数尾数域的位数是有限的,为此,浮点数的处理办法是持续该过程直到由此得到的尾数足以填满尾数域,之后对多余的位进行舍入。换句话说,除了我们之前讲到的精度问题之外,十进制到二进制的变换也并不能保证总是精确的,而只能是近似值。事实上,只有很少一部分十进制小数具有精确的二进制浮点数表达。再加上浮点数运算过程中的误差累积,结果是很多我们看来非常简单的十进制运算在计算机上却往往出人意料。这就是最常见的浮点运算的"不准确"问题。
参见下面的 Java 示例:
System.out.print("34.6-34.0=" + (34.6f-34.0f));
这段代码的输出结果如下:
34.6-34.0=0.5999985
产生这个误差的原因是 34.6 无法精确的表达为相应的浮点数,而只能保存为经过舍入的近似值。这个近似值与 34.0之间的运算自然无法产生精确的结果。
存储格式的范围和精度
| 格式 | 有效数字(二进制) | 最小正正规数 | 最大正数 | 有效数字(十进制) |
| 单精 | 24 | 1.175... 10-38 | 3.402... 10+38 | 6-9 |
| 双精度 | 53 | 2.225... 10-308 | 1.797...10+308 | 15-17 |
| 双精度扩展(SPARC) | 113 | 3.362... 10-4932 | 1.189...10+4932 | 33-36 |
| 双精度扩展(x86) | 64 | 3.362... 10-4932 | 1.189...10+4932 | 18-21 |
7. 舍入
值得注意的是,对于单精度数,由于我们只有 24 位的指数(其中一位隐藏),所以可以表达的最大指数为 224 - 1 = 16,777,215。特别的,16,777,216 是偶数,所以我们可以通过将它除以 2 并相应地调整指数来保存这个数,这样16,777,216 同样可以被精确的保存。相反,数值 16,777,217 则无法被精确的保存。由此,我们可以看到单精度的浮点数可以表达的十进制数值中,真正有效的数字不高于 8 位。事实上,对相对误差的数值分析结果显示有效的精度大约为 7.22 位。参考下面的示例:
| 真值(true value) | 存储值(stored value) |
| 16,777,215 | 1.6777215E7 |
| 16,777,216 | 1.6777216E7 |
| 16,777,217 | 1.6777216E7 |
| 16,777,218 | 1.6777218E7 |
| 16,777,219 | 1.677722E7 |
| 16,777,220 | 1.677722E7 |
| 16,777,221 | 1.677722E7 |
| 16,777,222 | 1.6777222E7 |
| 16,777,223 | 1.6777224E7 |
| 16,777,224 | 1.6777224E7 |
| 16,777,225 | 1.6777224E7 |
根据标准要求,无法精确保存的值必须向最接近的可保存的值进行舍入。这有点像我们熟悉的十进制的四舍五入,即不足一半则舍,一半以上(包括一半)则进。不过对于二进制浮点数而言,还多一条规矩,就是当需要舍入的值刚好是一半时,不是简单地进,而是在前后两个等距接近的可保存的值中,取其中最后一位有效数字为零者。从上面的示例中可以看出,奇数都被舍入为偶数,且有舍有进。我们可以将这种舍入误差理解为"半位"的误差。所以,为了避免 7.22 对很多人造成的困惑,有些文章经常以 7.5 位来说明单精度浮点数的精度问题。
提示: 这里采用的浮点数舍入规则有时被称为舍入到偶数(Round to Even)。相比简单地逢一半则进的舍入规则,舍入到偶数有助于从某些角度减小计算中产生的舍入误差累积问题。因此为 IEEE 标准所采用。
移码:
x包含:符号位和n个数值位
[x]移 = 2^n + x
x的移码可以通过将x的补码的符号位取反获得
如 :
x有4个数值位
x = +1010; [x]补 = 01010; [x]移 = 11010;
x = -1010; [x]补 = 10110; [x]移 = 00110;















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









