







堆的定义:堆可以看做一个完全二叉树,如果每一个除了叶子节点以外的节点,它的关键字都比它的左右孩子的关键字大,那么这个完全二叉树称之为堆(大顶堆),与之相对应的还有小顶堆。
堆排序算法流程:
(1)构建初始大顶堆
(2)对大顶堆进行调整,将堆顶与“堆尾”互换,现在最后一个元素一定是最大的,就可以对前面(n-1)个元素进行堆排序,进行调整,现在堆顶变成第二大的元素
(3)如此循环步骤(2)重复n-1次
补充:
若要从小到大排序:构建大顶堆
若要从大到小排序:构建小顶堆
例:
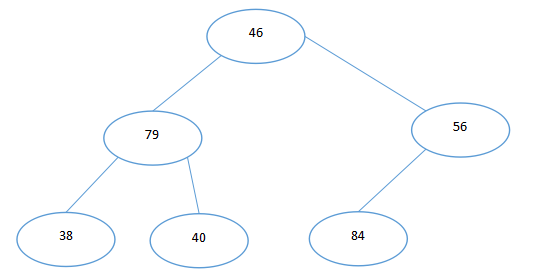
从小到大排列46,79,56,38,40,84
未加任何处理形成的完全二叉树:
(1)创建初始大顶堆(目的和结果:找到第一个最大的数,同时让它的左右子树都独立成为大顶堆)
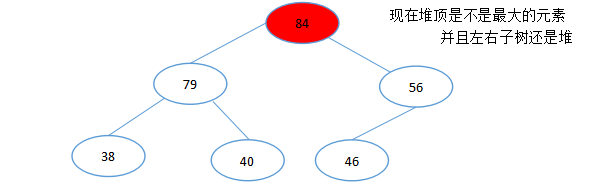
现在我们就稍稍明白一点了:每一次进行调整都能把堆顶变成剩余数字中的最大值
然后我们初始大顶堆创建完了时候进行剩下的n-1次调整就可以了
那~~如何进行调整呢??
(2)我们从最后一个位置开始,将它和堆顶互换,然后现在除了堆顶不满足堆的定义以外,其他地方都满足堆的定义,那么我们就从堆顶开始进行新一轮的调整就好了。

(互换完的不是堆的树,然后进行调整,会有新奇的事情发生哟:)
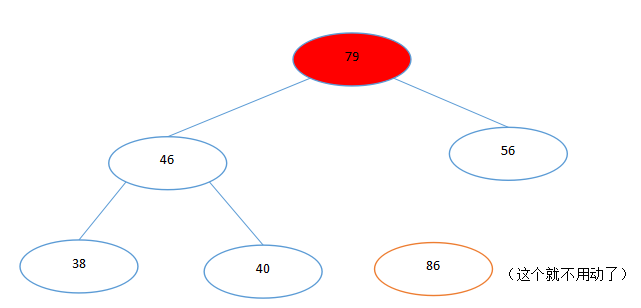
然后继续进行,是不是很神奇...
堆排序算法效率分析:
时间复杂度:
堆排序对于记录数较少的文件并不值得提倡,但对n较大的文件还是很有效的。因为其运行时间主要耗费在创建初始堆和调整建新堆时的反复“筛选”上, 对深度为k的堆,筛选算法中的关键字比较至多为 2(k-1)次,则在建立含n个元素,深度为h的堆时,总共进行的关键字比较次数不超过4*n,又因为n个结点的完全二叉树的深度为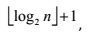
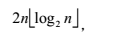
由此堆排序在最坏的情况下,它的时间复杂度也为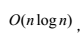
空间复杂度:
同时堆排序只需要一个记录大小的辅助空间,空间复杂度为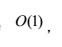
稳定性:
堆排序不稳定
综上所述,堆排序还是很优秀了,那为什么很多人还不了解呐,可能因为看起来很吓人吧,但是你看完学完之后还觉得它难吗 ~ - ~
从小到大排序Code:
//堆排序算法
#include<bits/stdc++.h>
using namespace std;
const int maxn = 10010;
int num[maxn]; //待排序数组
void HeapAdjust(int n); //调整为大顶堆
void HeapSort(int n) ; //堆排序
void HeapAdjust(int s, int n)
{
int temp = num[s];
for(int j = 2*s; j <= n; j*=2)
{
if(j < n && num[j] < num[j+1]) j++; //选出来左右子树中最大的
if(temp >= num[j]) break; //如果比左右子树中最大的还大,那就说明不用调换了,直接退出
else {
num[s] = num[j];
s = j; // s用来记录当前的最底下
}
}
num[s] = temp;
}
void HeapSort(int n)
{
for(int i = n/2; i >= 1; --i)
HeapAdjust(i, n); //构建初始大顶堆
for(int i = n; i > 1; --i) //一个值一个值的调整
{
swap(num[i], num[1]);
HeapAdjust(1, i-1);
}
}
int main()
{
int n;
scanf("%d", &n);
for(int i = 1; i <= n; i++)
scanf("%d", &num[i]);
HeapSort(n);
for(int i = 1; i <= n; i++)
printf("%d ", num[i]);
return 0;
}















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









