







🐵个人主页:ximury.blog.csdn.net
🐸Github:github.com/ximury
🐹精言佳句:岁月缱绻,葳蕤生香
项目概览
目录
.
├── config
│ ├── config.conf
│ ├── config_init.py
│ └── config_reader.py
├── csv
│ └── comment-1292052.csv
├── main.py
├── picture
│ └── fish-1292052.png
├── README.md
├── requirements.txt
├── src
│ ├── get_comments.py
│ └── movie_cloud.py
└── static
├── SIMLI.TTF
└── stop_words.txt
简述
- config.conf
项目配置文件 - requirements.txt
项目所需依赖,执行pip3 install -r requirements.txt安装即可 - stop_words.txt
生成词云图用到的停用词文件
功能实现
爬取评论
import json
from os import path
from urllib.parse import urlencode
from urllib.request import urlopen, Request
import ssl
import pandas as pd
from lxml import etree
from config.config_reader import movieConfig, netConfig
def get_comment(base_url, file_name, user_agent, request_info):
users_list = []
stars_list = []
time_list = []
content_list = []
# ssl验证问题:忽略不信任的证书。就可以访问该网站
context = ssl._create_unverified_context()
for i in range(0, 1200, 100):
# url编码后,传入Request()函数;headers参数伪装浏览器
request_info["start"] = i
full_url = f"{base_url}?{urlencode(request_info)}"
print(full_url)
req = Request(url=full_url, headers={"User-agent": user_agent})
try:
with urlopen(req, context=context) as res:
print(res.getcode())
res = json.loads(res.read()) # json转dict
# 解析 HTML
selector = etree.HTML(res["html"])
# 用 xpath 获取单页所有评论
comments = selector.xpath('//div[@class="comment"]')
# 遍历所有评论,获取详细信息
for comment in comments:
# 获取用户名
user = comment.xpath(".//h3/span[2]/a/text()")[0]
# 获取评星
star = comment.xpath(".//h3/span[2]/span[2]/@class")[0][7:8]
# 获取时间
date_time = comment.xpath(".//h3/span[2]/span[3]/@title")
# 有的时间为空,需要判断下
if len(date_time) != 0:
date_time = date_time[0]
date_time = date_time[:10]
else:
date_time = None
# 获取评论文字
comment_text = comment.xpath(".//p/span/text()")[0].strip()
# 添加所有信息到列表
users_list.append(user)
stars_list.append(star)
time_list.append(date_time)
content_list.append(comment_text)
except Exception as e:
print(e)
# 用字典包装
comment_dic = {
"user": users_list,
"star": stars_list,
"time": time_list,
"comments": content_list,
}
# 转换成 DataFrame 格式
comment_df = pd.DataFrame(comment_dic)
# 保存数据
project_path = path.dirname(path.dirname(__file__))
comment_df.to_csv(f"{project_path}/csv/{file_name}.csv")
if __name__ == "__main__":
# 伪装成浏览器
user_agent = (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/97.0.4692.99 Safari/537.36"
)
base_url = f"{netConfig.url}/subject/{movieConfig.subject}/comments"
request_info = {
"percent_type": "",
"start": 0,
"limit": 100,
"sort": "new_score",
"status": "P",
"comments_only": "1",
}
file_name = "comment-{}".format(movieConfig.subject)
get_comment(
base_url=base_url,
file_name=file_name,
user_agent=user_agent,
request_info=request_info,
)
生成词云图
import shutil
from os import path
import jieba
import pandas as pd
import stylecloud
from IPython.display import Image
from config.config_reader import cloudConfig
def generate_cloud_map(subject, icon):
project_path = path.dirname(path.dirname(__file__))
df = pd.read_csv(f"{project_path}/csv/comment-{subject}.csv", index_col=0)
cts_list = df["comments"].values.tolist()
cts_str = "".join([str(i).replace("\n", "").replace(" ", "") for i in cts_list])
stop_words = []
with open(f"{project_path}/static/stop_words.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# jieba 分词
word_list = jieba.cut(cts_str)
words = []
for word in word_list:
if word not in stop_words:
words.append(word)
cts_str = ",".join(words)
print(cts_str)
# 如果icon_name找不到,报错:TypeError: 'NoneType' object is not subscriptable
icon_name = f"fas fa-{icon}"
file_name = f"{icon}-{subject}.png"
file_path = f"{project_path}/picture/"
stylecloud.gen_stylecloud(
text=cts_str,
max_words=300,
collocations=False,
font_path=f"{project_path}/static/SIMLI.TTF",
# fa-arrow-circle-right,fa-user-graduate,fa-bone,fa-apple-alt
icon_name=icon_name,
size=800,
output_name=file_name,
)
# 若dst是file_path+file_name则会覆盖,而file_path则不会覆盖
shutil.move(src=file_name, dst=file_path + file_name)
Image(filename=file_path + file_name)
if __name__ == "__main__":
generate_cloud_map(subject=cloudConfig.subject, icon=cloudConfig.icon_name)
效果展示

自定义词云图形状
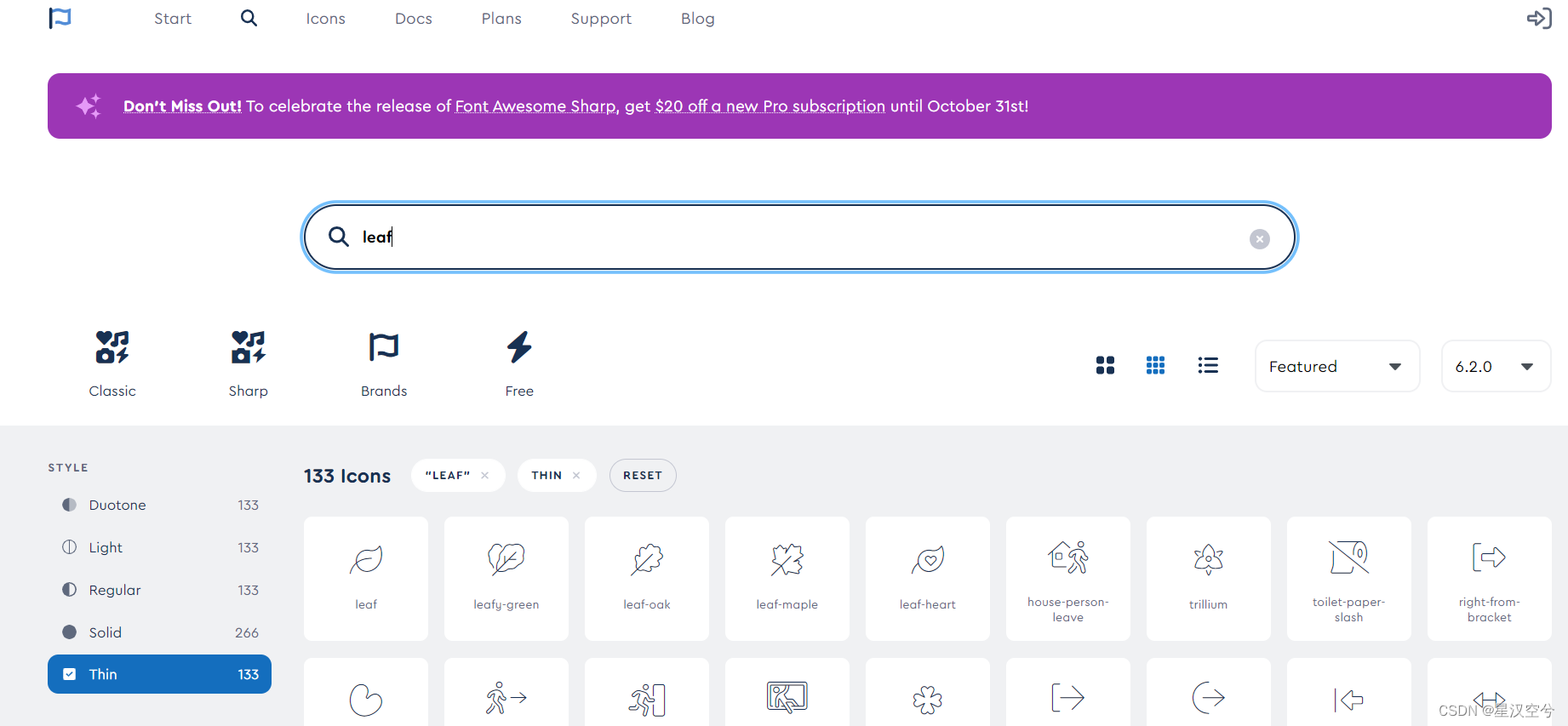
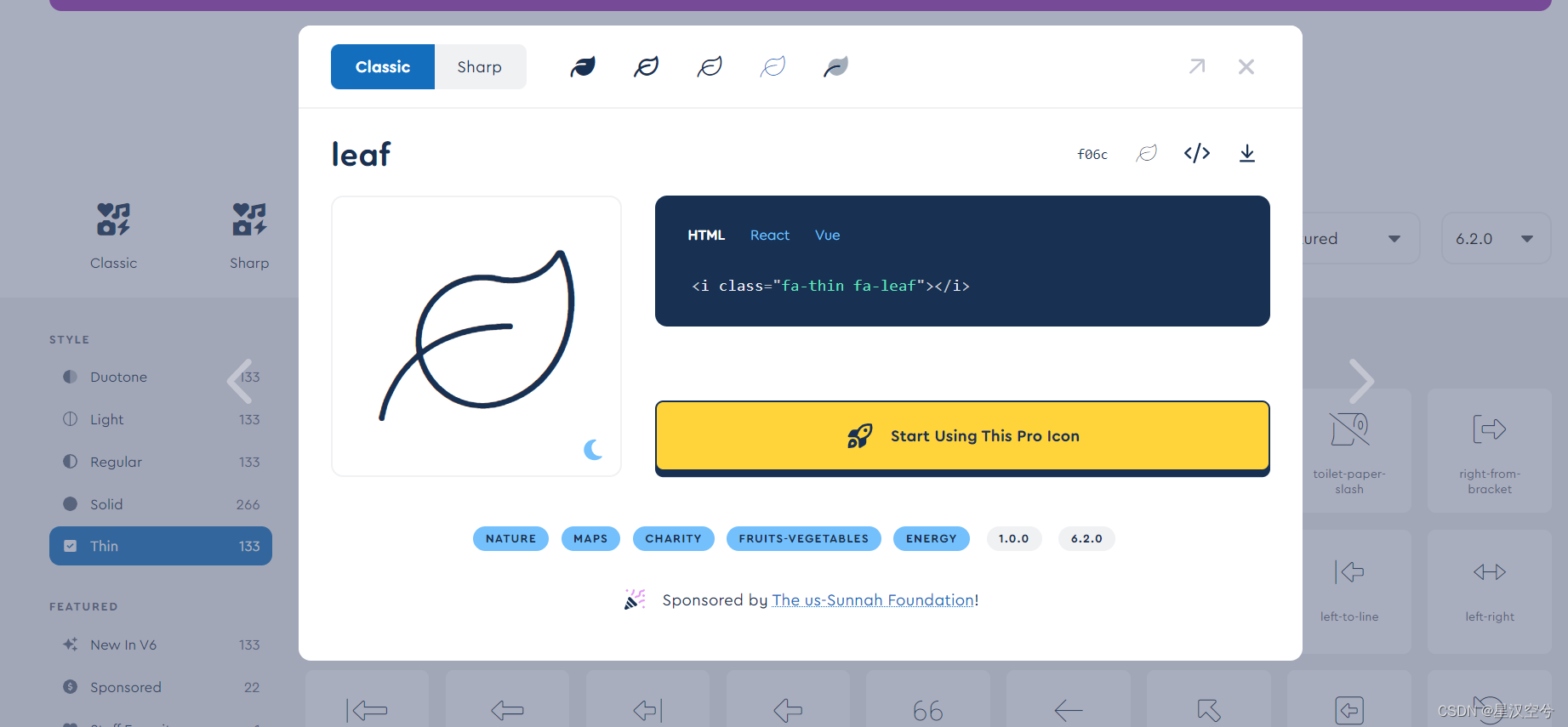
图标地址
选取图标


















 2197
2197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











