







1、第一范式
要求表中字段,具有原子性,不可再分解
-
错误的表设计
一个【联系方式】有手机号码、邮箱地址、和微信号,所以不符合第一范式

-
正确的表设计
【联系方式】字段,应拆分为手机号码,电子邮箱,居住地址,三个字段

此处的【居住地址】是否就是不符合第一范式呢?也必须拆分成:省、市、区,详细地址几个字段呢?
具有原子性,不可再分解。是要根据使用方便来自定义的最小单位
如果该字段只作为整体使用,没有场景单独获取或操作其中的省、市、区、详细地址一项,就是符合第一范式的,否则就要拆分字段
2、第二范式
表中必须存在业务主键 (单一业务主键 或 联合业务主键),非业务主键必须依赖业务主键
-
错误的表设计
这里姓名并不完整依赖联合主键(学号、课程名称),只是依赖学号,所以不符合第二范式

-
正确的表设计
正确的设计,应该是拆分成两张不同的表,一个是学分表,一个是学生表

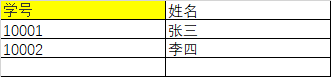
3、第三范式
非业务主键必须依赖业务主键,非业务主键之间不能传递依赖。
是对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖
-
错误的表设计
这里老师级别字段依赖了指导老师字段,所以不符合第三范式

-
正确的表设计
正确的设计,应该是拆分成两张不同的表,一个是学生表,一个是老师表

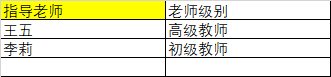
4、反范式
严格遵守三范式的未必是最好的数据库设计。为了提高运行效率,有时就必须降低范式标准,适当保留冗余数据。
具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。
降低范式标准就是增加冗余字段,减少关联查询,方便设置索引,达到用空间换时间的目的。
5、范式与反范式优缺点
| – | 优点 | 缺点 | 总结 |
|---|---|---|---|
| 范式 | 范式化的表减少了数据冗余,数据表更新操作快, 占用存储空间少 | 查询时需要对多个表进行关联,查询性能降低, 更难进行索引优化 | 时间换空间 |
| 反范式 | 可以减少表关联,查询性能变高,可以更好的进行索引优化 | 存在冗余字段数据,数据维护成本更高,数据一致性难以保证, 占用存储空间更大 | 空间换时间 |















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









