







1.xpath(XML PATH LANUAGE)语法
上下文:引用池或者引用区。
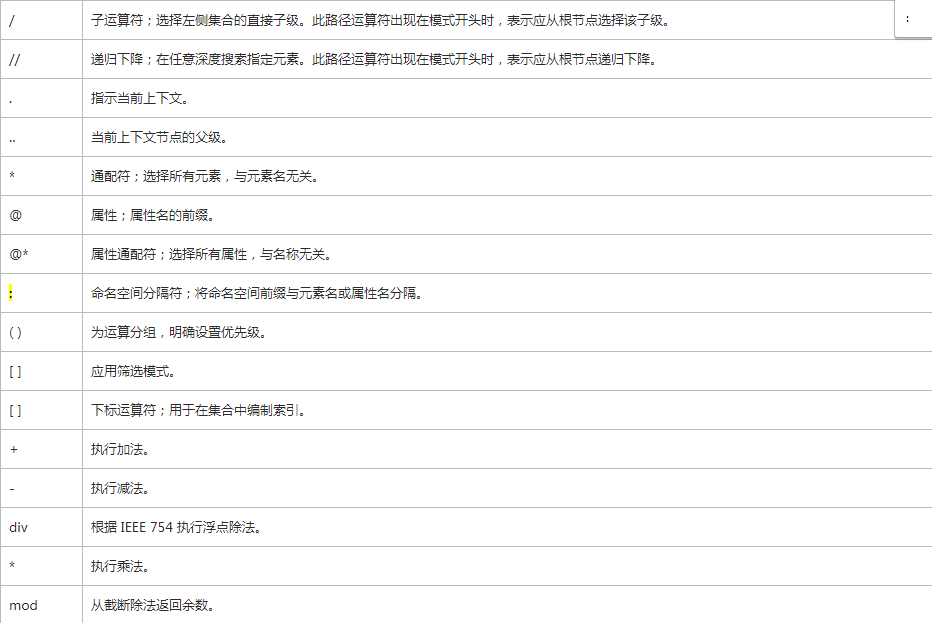
.的作用:
即使我们对取出来的子节点进行操作,默认还是对根节点进行的操作.使用点可以将根切换到目前的引用对象.
2.xpath与html的结合使用
1.导入相关依赖:
<!-- xpath依赖 -->
<dependency>
<groupId>jaxen</groupId>
<artifactId>jaxen</artifactId>
<version>1.1.1</version>
</dependency>
<!-- r能够重新整理HTML文档的每个元素并生成结构良好(Well-Formed)的 HTML 文档。 -->
<dependency>
<groupId>net.sourceforge.htmlcleaner</groupId>
<artifactId>htmlcleaner</artifactId>
<version>2.9</version>
</dependency>
<dependency>
<groupId>jaxen</groupId>
<artifactId>jaxen</artifactId>
<version>1.1.1</version>
</dependency>
<!-- r能够重新整理HTML文档的每个元素并生成结构良好(Well-Formed)的 HTML 文档。 -->
<dependency>
<groupId>net.sourceforge.htmlcleaner</groupId>
<artifactId>htmlcleaner</artifactId>
<version>2.9</version>
</dependency>
2.通过xpath对文档进行操作
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import org.htmlcleaner.CleanerProperties;
import org.htmlcleaner.DomSerializer;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class TestReg {
public static void XpathUtil(String path)
throws XPathExpressionException, SAXException, IOException, ParserConfigurationException {
//生成xpathfactory和xpath对象
XPathFactory xpathfactory = XPathFactory.newInstance();
XPath xpath = xpathfactory.newXPath();
//对文档流进行加工
HtmlCleaner hc = new HtmlCleaner();
TagNode tn;
try {
tn = hc.clean(getInputStream(path));
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
Document dom = new DomSerializer(new CleanerProperties()).createDOM(tn);
//通过xpath对dom进行操作
XPathExpression express = xpath.compile("/*");
Object str = express.evaluate(dom, XPathConstants.NODESET);
NodeList nodelist = (NodeList) str;
for (int i = 0; i < nodelist.getLength(); i++) {
Node temp = nodelist.item(i);
temp.removeChild(temp.getChildNodes().item(0));
}
}
// 获取输入流
public static String getInputStream(String filepath) throws IOException, FileNotFoundException {
FileInputStream fis = new FileInputStream(new File(filepath));
StringBuffer value = new StringBuffer();
int len = -1;
byte[] tmp = new byte[1024];
while ((len = fis.read(tmp)) != -1) {
value.append(new String(tmp, 0, len, "utf-8"));
}
return value.toString();
}
}
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import org.htmlcleaner.CleanerProperties;
import org.htmlcleaner.DomSerializer;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class TestReg {
public static void XpathUtil(String path)
throws XPathExpressionException, SAXException, IOException, ParserConfigurationException {
//生成xpathfactory和xpath对象
XPathFactory xpathfactory = XPathFactory.newInstance();
XPath xpath = xpathfactory.newXPath();
//对文档流进行加工
HtmlCleaner hc = new HtmlCleaner();
TagNode tn;
try {
tn = hc.clean(getInputStream(path));
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
Document dom = new DomSerializer(new CleanerProperties()).createDOM(tn);
//通过xpath对dom进行操作
XPathExpression express = xpath.compile("/*");
Object str = express.evaluate(dom, XPathConstants.NODESET);
NodeList nodelist = (NodeList) str;
for (int i = 0; i < nodelist.getLength(); i++) {
Node temp = nodelist.item(i);
temp.removeChild(temp.getChildNodes().item(0));
}
}
// 获取输入流
public static String getInputStream(String filepath) throws IOException, FileNotFoundException {
FileInputStream fis = new FileInputStream(new File(filepath));
StringBuffer value = new StringBuffer();
int len = -1;
byte[] tmp = new byte[1024];
while ((len = fis.read(tmp)) != -1) {
value.append(new String(tmp, 0, len, "utf-8"));
}
return value.toString();
}
}















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









