







 本文探讨了GPU利用率低的原因及解决办法,包括数据加载、数据增强、NMS算法优化及环境配置,强调了环境对GPU性能的影响。
本文探讨了GPU利用率低的原因及解决办法,包括数据加载、数据增强、NMS算法优化及环境配置,强调了环境对GPU性能的影响。
今天训练faster R-CNN时,发现之前跑的很好的程序(是指在运行程序过程中,显卡利用率能够一直维持在70%以上),今天看的时候,显卡利用率很低,所以在想是不是我的训练数据torch.Tensor或者模型model没有加载到GPU上训练,于是查找如何查看tensor和model所在设备的命令。
import torch import torchvision.models as models model=models.vgg11(pretrained=False) print(next(model.parameters()).is_cuda)#False data=torch.ones((5,10)) print(data.device)#cpu
上述是我在自己的笔记本上(显然没有GPU)的打印情况。
上次被老板教授了好久,出现西安卡利用率一直很低的情况千万不能认为它不是问题,而一定要想办法解决。比如可以在加载训练图像的过程中(__getitem__方法中)设定数据增强过程中每个步骤的时间点,对每个步骤的时间点进行打印,判断花费时间较多的是哪些步骤,然后尝试对代码进行优化,因为torhc.utils.data中的__getitem__方法是由CPU上的一个num_workers执行一遍的,如果__getitem__方法执行太慢,则会导致IO速度变慢,即GPU在大多数时间都处于等待CPU读取数据并处理成torch.cuda.tensor的过程,一旦CPU读取一个batch size的数据完毕,GPU很快就计算结束,从而看到的现象是:GPU在绝大多数时间都处于利用率很低的状态。所以我总结的是,如果GPU显卡利用率比较低,最可能的就是CPU数据IO耗费时间太多(我之前就是由于数据增强的裁剪过程为了裁剪到object使用了for循环,导致这一操作很耗时间),还有可能的原因是数据tensor或者模型model根本就没有加载到GPU cuda上面。其实还有一种可能性很小的原因就是,在网络前向传播的过程中某些特殊的操作对GPU的利用率不高,当然指的是除了网络(卷积,全连接)操作之外的其他的对于tensor的操作,比如我之前的faster R-CNN显卡利用率低就是因为RPN中的NMS算法速度太慢,大约2-3秒一张图,虽然这时候tensor特征图在CUDA上面,而且NMS也使用了CUDA kernel编译后的代码,也就是说NMS的计算仍然是利用的CPU,但是由于NMS算法并行度不高,所以对于GPU的利用不多,导致了显卡利用率低,之前那个是怎么解决的呢?哈哈,说到底还是环境的问题非常重要,之前的faster R-CNN代码在python2 CUDA9.0 pytorch 0.4.0 环境下编译成功我就没有再仔细纠结环境问题,直接运行了,直到后来偶然换成python3 CUDA9.0 pytorch 0.4.1 环境才极大地提高了显卡利用率,并且通过设置了几十个打印时间点之后发现,真的就是NMS的速度现在基本能维持在0.02-0.2数量级范围内。
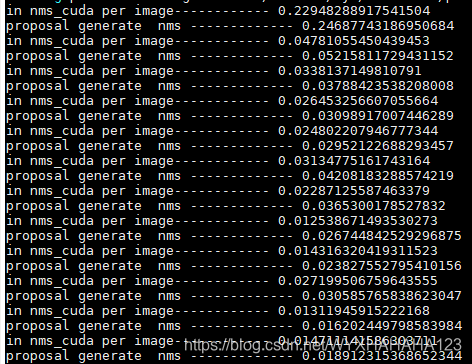
下图分别表示之前(显卡利用率很低)时的NMS处理单张图像所消耗的时间(之所以会有长有短是因为我支持不同分辨率的图像训练),后面一张图是GPU利用率一直能维持在很高的情况下NMS处理时间,由于数据增强部分的代码完全没有修改,故而换了环境之后我就没有再打印数据增强每个步骤所消耗的时间了。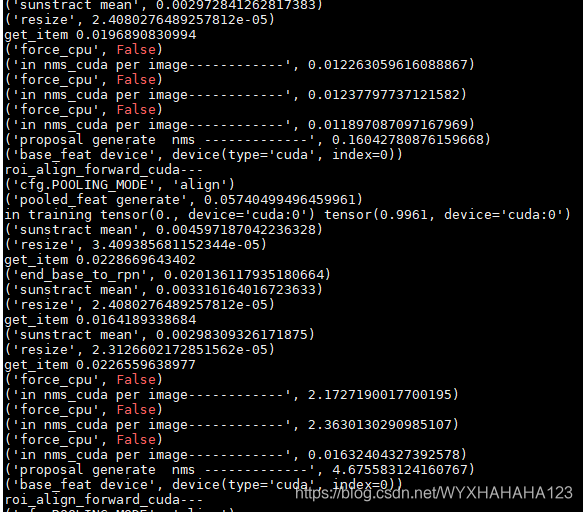


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









