









感谢这篇文章的博主,笔芯
https://baijiahao.baidu.com/s?id=1600682192551404789&wfr=spider&for=pc
前两天需要从网络下载图片,于是就学了学爬虫,很多文章教程我都没看懂,但是上边链接里的看懂了。。。所以十分的感谢
从哪里获取图片呢?
我们从:https://unsplash.com,网站展示:

从哪里下手呢?
先来看一下网站的元素,因为网站都是图片,所以先找找图片的元素写在哪里
1,打开网站,点击开发者工具:

2,找到图片们的位置,对着任意一张图片,点击右键,点击查看元素,找到定位如下所示:

这些就是我们美丽的可爱的图片们的位置了
3,我们是要dang很多很多图片,也就是整个图片集,所以我们需要定位一下:
使用我们传说中的selector来定位,平时一般用xpath多一些:
python中定位语法是:find_elements_by_css_selector
鼠标放在图中所指的位置右击对css 选择器路径进行复制就行了,完美

4,可以说最重要的部分学会了,那么我们接下来就很轻松啦:
浏览器启动解析?
启动浏览器打开对应的网址,需要放大一下屏幕,滚动条向下滑一下,超级简单的。。。

图片定位?
#gridMulti img就是我们刚才复制的css 选择器,因为我们是要找每个元素的链接,也就是src,我们的image_elements获取的是网站所有的图片,相当于是个列表,所以我们需要用for循环来遍历出每个网址并打印出来,这个在结果中可以看出来在下边可以看到

如何获取图片并保存呢?
从发送的请求内容中我们来获取图片的src,也就是get方法
然后我们BytesIO实现了在内存中读写bytes,一般是操作二进制的数据,open和save方法是打开和保存这个应该都懂
format方法是字符串格式化
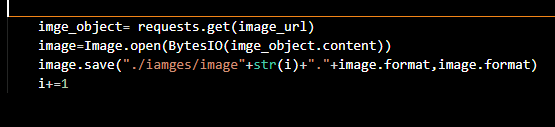
整合所有的代码:
是不是很简单

我们在终端运行后的结果:
只截了一小部分

我们再来看我们图片:

大功告成
















 2034
2034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











