







上一篇:目录
神经网络虽然用到了数学,但是它不像数学这样“严谨”,它不像传统的机器学习手段(比如决策树、随机森林、近邻法等)一样,能让我们清楚地知道它到底学了什么,虽然现在有很多人致力于研究神经网络背后原理——它到底学到了什么?确实也有一些振奋人心的成果产出,不过还是远远不够的。
神经网络我们经常称其为“黑箱”也就是我们不知道它到底学了什么,不知道为什么它为什么能如此好的工作(这里“不知道”的意思是说现在还不能很严谨地解释)
我理解的神经网络(监督式学习),其实就像个小孩子,一开始他不会做这件事,所以它一开始只能“蒙”,“蒙”代表着随机,这不重要,重要的是要有一个好的老师(家长)告诉他,这件事最应该怎样做(标签),就在这一次次地试错,改错中,这个小孩子就不断地成长(模型训练),最后能够独挡一面(进行预测)。
一台简单的预测机
先来看一个简单的例子,假设我们不知道华里和公里之间的转换关系,但我们知道二者间的关系是线性的(公里数=华里数*C,C为常数),我们现在仅知道二者的一些正确匹配数据

因为我们不知道系数C到底是什么,所以我们随机初始化C=1,我们希望得到一个合适的系数C的值,当我们告诉它华里数时,它能输出公里数
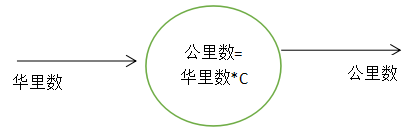
当我们使用第一组数据时,华里数2乘以系数C=1,得出公里数等于2,但我们已经知道,实际的值应该为1,所以我们知道此时程序的输出有误差,为+1,也就是说我们初始化的C太大了!一个显而易见的方法是,我们减小C的值,让C从1变到0.9以此希望得到更接近于实际解的输出。
我们继续使用表中的数据当华里数为3时,此时乘以C=0.9,得到输出结果为2.7,但我们已经知道实际解应为1.5,有+1.2的误差,也就说明我们的系数C还是太大, 故我们继续更新(减小)系数C为0.8。
当然在该例中,我们很清楚的知道C的实际值应该为0.5,即公里=华里*0.5,刚刚我们仅仅用了两个数据,将随机得到的系数1更新为0.8,想象一下,如果我们有很多数据,就可以用这个“很笨”的方法得到最后相对满意的解。
让我们在来看一下这个方法,我们并未像做数学题一样也,一步到位,精确求解问题。相反,我们尝试得到一个答案并多次改进答案,这种方法也称为迭代,能够使我们持续地,一点点地改进答案。更通俗一点说,就是蒙,一开始随便蒙,但我们会根据已知的数据改变我们蒙的策略,如果蒙的结果大了,那我下次就往小了蒙,如果蒙的结果大了,那下次就往大了蒙,这跟我们人的思维方式是很相似的。
我们也可以给上例一个高大上的名字:有监督学习(有标签数据),后边会慢慢介绍。
分类与预测
来看这样一个例子,我们现在得到了一批小虫子的特征值,有长度、宽度两个特性,现在让你来将这两类小虫子分开。
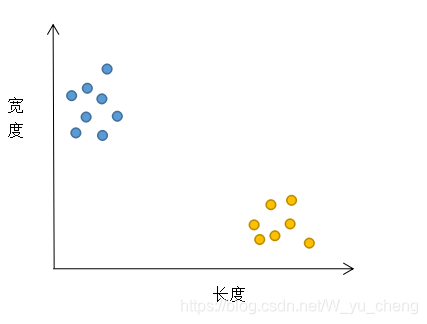
(在这些数据中)显然,我们能够找到这样一条线,将两类昆虫分开,使用的策略也是“蒙”,一开始随机指定一个斜率,然后根据样本数据不断更新斜率,直到这条直线能够将昆虫正确分类,这就是分类。
假设我们经过很多次迭代已经找到了这样一条这样的直线,现在给了一个新的数据,我们能够判读出这个数据所代表的点在直线上方还是下方,在上方就称其为蓝色小虫,在下方就称其为黄色小虫,也就实现了预测这一功能。
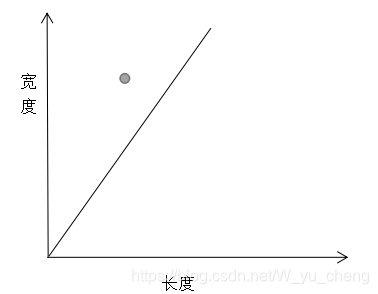
如何训练简单的分类器
此部分我们将更加深入的介绍如何进行权重的更新,即如何得到一个合适的量。
承接上例,我们继续对小虫子分类,我们还是希望能够找到一条好的分类线将两类小虫分开

显然这样的线是存在的

我们还是可以假设分界线是一条直线y=Ax(这里没有b的原因是,直线过不过原点对此问题没有任何影响),还是用‘蒙数’的方法,我们尝试从A=0.25开始,在上图中绘制该线:

显然,这条直线无法工作!我们不能根据未知点在直线的上/下侧,来得出虫子的种类。**显而易见的,我们希望直线能向上移动一些!**那么到底要向上移动多少呢?
观查表中数据,宽度为3的小虫,长度应为1,但如果我们使用上述直线预测长度 我们将得到:y=0.253=0.75。相较于实际长度1来说,0.75过小。
在我们调整参数A的值之前,思考这样一个问题,直线y的值应该是什么?我们希望直线能够把所有不同的小虫分开,而不是落在直线上,所以,对于x=3.0时,我们将y的目标值设为1.1(这只是比1.0大一点,恰好可以完成分类问题,选择1.2,1.3甚至100也是可以的,但这样又可能会使得两类小虫全部在直线的下方,使得分类器毫无用处)。
定义 误差值 = 期望值 - 实际值
这样y的误差Δy=Ey - y =1.1-0.75=0.35

那么Δy与A的调整量ΔA之间有什么关系呢?(A+ΔA)作为调整后的权重系数,则目标值E = (A+ΔA)x
有 E - y =(A+ΔA)x - x = Δy
简单化简后,Δy = ΔA*x
我们就得到了A的调整量ΔA=Δy/x,也就是说,我们可以通过求导数的方法,确定权重的相对好的更新量。
小结:
神经网络其实就是蒙数,开始的权重是随机的(蒙的),然后通过不断的试错来调整这些参数,输出量偏大就将权重调小,反之则加大。确定更新量的大小,可以通过求导数的方法来确定更新量(这实际上已经用到了梯度下降极小化损失函数的思想了)
下一篇:感知机模型原理和对偶形式与二分类问题及python实现


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









