






 本文介绍了目标检测技术,重点讲解了YOLO算法的工作原理、优点与局限性,以及在安防监控、自动驾驶等领域的应用。详细步骤包括项目来源、环境配置、数据集准备、模型训练和预测,强调了实践中的关键因素和注意事项。
本文介绍了目标检测技术,重点讲解了YOLO算法的工作原理、优点与局限性,以及在安防监控、自动驾驶等领域的应用。详细步骤包括项目来源、环境配置、数据集准备、模型训练和预测,强调了实践中的关键因素和注意事项。
一、什么是目标检测
目标检测(object detection)是计算机视觉中使用的一种技术,用于识别和定位图像或视频中的对象。
图像定位是指使用边界框(bounding boxes)来识别一个或多个对象的正确位置的过程,这些边界框对应于围绕对象的矩形形状。
这个过程有时会与图像分类或图像识别混淆,后者旨在将图像或图像中的对象预测为类别或类别之一。
下面的插图对应于上述解释的计算机视觉技术。

二、什么是YOLO ?
YOLO(You Only Look Once)是一种快速且准确的目标检测算法。它的核心思想是将目标检测问题视为一个回归问题,通过将图像分成网格,并对每个网格预测物体位置和类别来完成目标检测。具体而言,YOLO将图像分成S*S个网格,每个网格负责检测一个物体。对于每个网格,YOLO会预测出K个候选框,每个候选框包含物体的位置和类别概率。通过对所有网格的预测结果进行综合,可以得到整张图像中所有物体的位置和类别。
YOLO算法具有实时性高、对小目标物体检测效果好、准确性高等优点,因此在智能监控、自动驾驶、视频监控和安防、工业质检、零售和物流等多个领域得到了广泛的应用。同时,YOLO算法也存在一些缺点,如对大目标物体的检测效果相对较差,需要在训练过程中进行大量的数据增强和数据集筛选,以及对硬件资源的要求较高等。
三、YOLO目标检测在领域的应用
YOLO目标检测在我们日常生活中有不同的应用。在这一部分我们将涵盖以下领域:
1.安防监控:在视频监控系统中,YOLO可以实时检测和识别出人员、车辆等关键目标。通过快速准确地识别异常行为或潜在威胁,它极大地增强了安防系统的效能。
2. 自动驾驶:在自动驾驶汽车中,YOLO用于检测道路上的车辆、行人、交通标志等关键元素,从而辅助车辆进行安全驾驶和决策。
3. 工业自动化:在制造业中,YOLO可以用于检测生产线上的产品缺陷或进行质量控制。它可以帮助企业实现自动化检测和预警,提高生产效率和质量。
4. 零售分析:在零售行业中,YOLO可以用于分析顾客行为,如检测顾客在商店内的移动轨迹、停留时间以及关注的商品等。这有助于零售商优化店铺布局、提升库存管理以及制定更精准的营销策略。
5. 无人机应用:无人机配备YOLO算法后,可以在空中进行地面物体的检测和分类。这在航拍、环境监测、灾害救援等领域具有广泛的应用前景。
6. 医疗影像分析:在医疗领域,YOLO可以辅助医生进行医疗影像分析,如自动检测X光、CT或MRI图像中的异常区域。这有助于提高诊断的准确性和效率。
四、YOLO的具体操作步骤
1.项目来源
项目来源于GitHub上的一个开源项目,具体链接为:GitHub - bubbliiiing/yolov4-pytorch at bilibili。这个项目提供了YOLO算法的实现,并且经过了优化和改进,方便我们进行使用和二次开发。
2.使用环境
YOLO算法需要使用Python3.8和PyTorch框架进行实现。在本项目中,我们使用的是PyTorch版本1.13.1。请确保你的环境中已经安装了相应版本的Python和PyTorch。
3.安装相关库
在开始之前,你需要安装一些必要的Python库。这些库包括:
opencv-python:用于图像处理和目标检测结果的可视化。
pillow:用于图像处理和转换。
numpy:用于数值计算和数组操作。
onnx:用于模型转换和部署。
tensorboard:用于可视化训练过程中的损失和准确率等指标。
可使用pip命令来安装这些库
pip install opencv-python
pip install pillow
pip install numpy
pip install onnx
pip install tensorboard
在安装过程中,可能会遇到下载速度较慢的问题。为了提高安装速度,你可以选择性地添加镜像源。以下是一些常用的镜像网址:
1、南京邮电大学开源镜像网站地址:https://mirrors.njupt.edu.cn/
2、清华大学开源软件镜像站地址:https://mirror.tuna.tsinghua.edu.cn/
3、中国科大开源软件镜像站地址:http://mirrors4.ustc.edu.cn/
4、网易开源镜像站地址:http://mirrors.163.com/
5、阿里云开源镜像站地址:http://mirrors.aliyun.com/
6、腾讯云开源镜像站地址:https://mirrors.cloud.tencent.com/
7、豆瓣开源镜像站地址:http://pypi.douban.com/simple/
4.下载和准备数据集
为了训练和测试YOLO模型,我们需要一个带有标注信息的数据集。VOC(Visual Object Classes)数据集是一个常用的目标检测数据集,包含了多种不同的物体类别和相应的标注信息。
你可以通过以下链接下载VOC数据集:
链接:https://pan.baidu.com/s/19Mw2u_df_nBzsC2lg20fQA
提取码: j5ge
该数据集已经预先划分好了训练集、测试集和验证集,因此你无需再次进行划分操作。下载完成后,解压数据集,并按照项目的要求将其放置在正确的文件夹中。
5.下载权重
在进行模型训练之前,我们通常可以使用预训练的权重作为初始点,以加速训练过程并提高模型的性能。对于YOLO算法,你可以从互联网上下载已经训练好的权重文件。
以下是下载YOLO预训练权重的链接:
链接: https://pan.baidu.com/s/1oXz13QwLx1lnXct538qL2Q
提取码: 16qc
其中,yolo4_weights.pth是针对COCO数据集的权重文件,而yolo4_voc_weights.pth则是针对VOC数据集的权重文件。根据你的需求选择相应的权重文件进行下载。
下载完成后,将权重文件放置在你的项目文件夹中,确保在训练模型时能够正确加载这些权重。
注意事项:
确保下载的数据集和权重文件与你的项目要求相匹配,避免因为版本或格式不兼容导致的问题。
在下载数据集和权重文件时,请注意检查文件的完整性和正确性,以确保后续的实验能够顺利进行。
6.训练模型
1.图像收集与存储
首先,我们需要收集一系列目标检测任务所需的图片。这些图片应涵盖目标物体的不同角度、大小和背景,以便模型能够学习到物体的多样性和泛化能力。在本例中,我们将这些图片存储在VOCdevkit文件夹下的VOC2007文件夹中的JPEGImages子文件夹中。
注意事项:
①确保收集的图片数量和多样性足够,以覆盖目标检测任务的各种场景。
②在进行图像标注时,务必保持标注的准确性和一致性。尽量使用统一的标注规范,避免因为标注错误或不一致性导致模型性能下降。同时,标注的名称应使用英文或拼音,避免使用特殊字符或空格,以确保后续处理过程中的兼容性。
③存储数据时,保持文件夹结构的清晰和规范至关重要。建议按照数据集的标准格式进行组织,如VOC数据集的结构。此外,图片文件最好使用同一格式,本数据集的图片已统一为jpg格式,这样可以避免在训练和测试过程中因格式不统一导致的问题。
2.图像标注
接下来,我们需要对收集到的图片进行标注,即标出图片中目标物体的位置和类别。这通常通过使用专门的标注工具来完成。在本例中,我们使用labelImg_exe作为标注工具。标注完成后,每个图片都会生成一个对应的标签文件(以.xml为后缀),其中包含目标物体的边界框坐标、类别等信息。标注图如下:
3.标签文件存储
完成标注后,我们需要将生成的标签文件存储在合适的位置,以便后续的训练过程能够读取到这些文件。在本例中,我们将所有.xml标签文件放在VOCdevkit文件夹下的VOC2007文件夹中的Annotation子文件夹中。
4.数据处理
完成以上准备后,
我们需要使用voc_annotation.py脚本来生成训练所需的2007_train.txt和2007_val.txt文件。这两个文件包含了训练集和验证集中图片的路径以及对应的标注信息。
在修改voc_annotation.py时,主要关注的是classes_path参数。这个参数用于指定包含检测类别名称的文本文件路径。如果你是第一次训练模型,只需要修改这个参数即可。
对于自定义的数据集,你可以创建一个名为cls_classes.txt的文件,并在其中列出你所要检测的类别。每个类别占一行,确保类别的命名准确且一致。
下面是我自己建立的cls_classes.txt:

————————————————
5.模型训练
模型训练时,请确保train.py中的classes_path指向正确的类别文本文件。对于自定义数据集,务必修改此参数以匹配你的类别列表。训练启动后,权重文件将保存在logs文件夹中。
注意事项:
训练前,请仔细检查model_path和classes_path是否对应,确保num_classes与classes_path中的类别数量一致,避免训练出错。
7.训练结果预测
1.主要文件
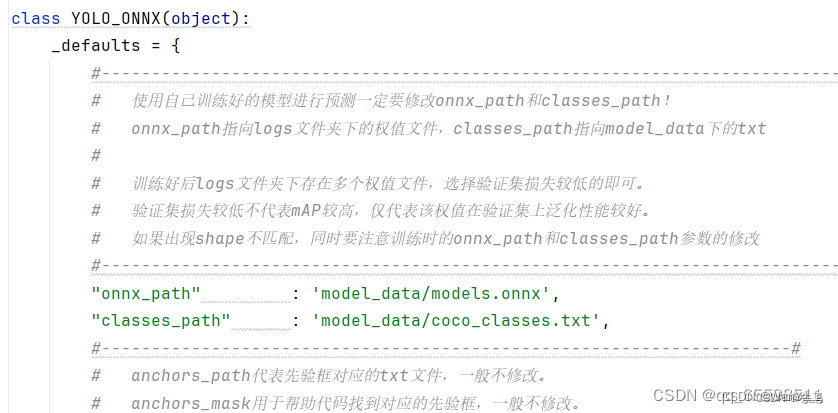
预测时,主要使用yolo.py和predict.py。在yolo.py中,需修改model_path和classes_path指向正确的模型权重和类别文件。
model_path指向训练好的权重文件
classes_path指向类别文本文件(.txt)
2.训练权重
3.输入预测图片
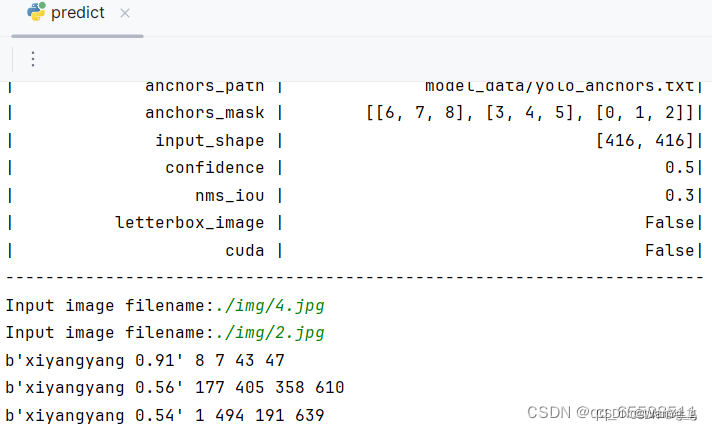
输出的图片如下所示:

五.总结
通过参与本次YOLO目标检测项目的学习,我深入了解了模型训练与预测的整体流程。在这个过程中,我意识到数据集的规模、标签格式的准确性以及网络的收敛速度对于预测结果的影响是至关重要的。尽管在初期阶段,我遇到了准确率不高的困扰,但通过积极地反思和调整,逐步提高了模型的准确性。
在实践过程中,我不仅学到了如何处理数据、训练模型,还学习到了如何调整超参数以提升模型性能。通过不断地尝试和探索,我逐渐掌握了如何解决模型训练过程中可能出现的问题,提高了我的问题解决能力和实践技能。
此次学习让我对目标检测技术有了更深刻的理解,让我认识到了其中的挑战和技术难点。同时,我也意识到了实践的重要性,只有通过不断地实践和尝试,才能真正掌握并提升自己在这一领域的能力。
特别提示:该博客为作业,仅供参考。
————————————————















 5164
5164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









