







前言
人生如逆旅,我亦是行人。————苏轼《临江仙·送钱穆父》
广度优先搜索介绍
广度优先搜索算法(又称宽度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。
Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。
核心思想:
从初始节点开始,应用算符生成第一层节点,检查目标节点是否在这些后继节点中,若没有,再用产生式规则将所有第一层的节点逐一扩展,得到第二层节点,并逐一检查第二层节点中是否包含目标节点。若没有,再用算符逐一扩展第二层的所有节点……,如此依次扩展,检查下去,直到发现目标节点为止。

代码算法描述:
/**
* 广度优先搜索算法描述
**/
int Bfs()
{
//初始化,初始状态存入队列
//队列首指针 head = 0,尾指针 tail = 1
do
{
//指针head后移一位,指向待扩展结点
for(int i=1; i<=max; i++) //max为产生子结点的规则数
{
if(子结点符合条件)
{
tail尾指针加一,把新结点存入队尾
if(新结点与原已产生的结点重复)
删去该结点(取消入队,尾指针tail减1)
else if(新结点是目标结点)
//TODO
//输出并退出
}
}
}while(head < tail); //不满足此条件说明队列为空
}
代码算法描述:
- 每生成一个子结点,就要提供指向它们父结点的指针。当解出现时候,通过逆向跟踪,找到从根结点到目标结点的一条路径。当然如果不要求输出路径,就没必要记父结点。
- 生成的结点要与前面所有已经产生结点比较,以免出现重复结点,浪费时间和空间,还有可能陷入死循环。
- 如果目标结点的深度与路径长度成正比,那么,找到的第一个解就是最优解,此时的搜索速度要比深度搜索更快,再求最优解的时候往往采用广度优先搜索;如果目标结点的路径不与深度成正比,第一次找到的解就不一定是最优解。
- 广度优先搜索的效率还有赖于目标结点所在位置情况,如果目标结点深度处于较深层时,需搜索的结点数基本上以指数增长。此时使用深度搜索就相对更为便利一点。(具体问题还是要具体分析)
题目
【例1】
图中表示了一个从A到H的图,现在要找出一条从A到H且经过城市最少的一条路线。

使用队列的思想,数组 arr 用来存储扩展结点,作为一个队列,arr[i] 记录经过的结点,数组 b[i] 记录前趋结点,通过倒推得出最短的路线,具体过程如下:
- 将
A入队,队头为0,队尾为1; - 将队头所有可以直接指向的结点入队(如果该结点在队列中出现过就不入队,可用一布尔数组
s[i]来记录判断),将入队结点的前趋结点保存在b[i]中。然后将队头加 1,得到新的队头结点。 - 重复以上步骤,直到搜到结点
H时,则搜索结束。利用b[i]可倒推出经过最少结点的路线。
代码书写:
#include<iostream>
#include<cstring>
using namespace std;
/*
* 9*9的矩阵 : A/B/C/D/E/F/G/H
* 数组 `arr` 用来存储扩展结点,作为一个队列,`arr[i]` 记录经过的结点,数组 `b[i]` 记录前趋结点,通过倒推得出最短的路线
*/
//定义一个数组表示矩阵
int matrix[9][9] = {{0,0,0,0,0,0,0,0,0},
{0,1,0,0,0,1,0,1,1},
{0,0,1,1,1,1,0,1,1},
{0,0,1,1,0,0,1,1,1},
{0,0,1,0,1,1,1,0,1},
{0,1,1,0,1,1,1,0,0},
{0,0,0,1,1,1,1,1,0},
{0,1,1,1,0,0,1,1,0},
{0,1,1,1,1,0,0,0,1}};
int arr[101],b[101];
bool s[9]; //布尔数组:记录判断经过的结点的历史,最多经过9个结点且不出现重复
//输出过程
int out(int d)
{
cout << char(arr[d] + 64);
while(b[d]) //前趋结点不为空结点
{
d = b[d];
cout << "--" << char(arr[d] + 64);
}
cout << endl;
}
void doit(void)
{
int head, tail, i;
//队头为0,队尾为1
head=0;
tail=1;
arr[1] = 1; //记录经过的结点
b[1] = 0; //记录前趋结点
s[1] = 1; //表示该结点已经到过了
do{
head++; //队头加一,出队
for(i=1; i<=8; i++) //搜索可直接到达的结点
{
//TODO
if((matrix[arr[head]][i] == 0) && (s[i] == 0)) //判断城市是否走过
{
tail++; //队尾加一,入队
arr[tail] = i;
b[tail] = head;
s[i]=1;
if(i == 8)
{
//TODO:第一次搜索到H结点时路线最短
out(tail);
head = tail;
break;
}
}
}
}while(head < tail);
}
//主函数
int main()
{
memset(s,false,sizeof(s));
doit(); //进行广度优先搜索操作(Bfs)
return 0;
}
实验结果:

memset()函数
-
重要:定义变量时一定要进行初始化,尤其是数组和结构体这种占用内存大的数据结构。
在使用数组的时候经常因为没有初始化而产生“烫烫烫烫烫烫”这样的野值,俗称“乱码”。
每种类型的变量都有各自的初始化方法,memset()函数可以说是初始化内存的“万能函数”,通常为新申请的内存进行初始化工作。它是直接操作内存空间,mem即“内存”(memory)的意思。该函数的原型为:# include <string.h> //#include<cstring>:c++ void *memset(void *s, int c, unsigned long n);- 函数功能: 将指针变量
s所指向的前n个字节的内存单元用一个 “整数” c 替换(也可以是其他类型),(注:c是int型,s是void *型的指针变量,所以它可以为任何类型的数据进行初始化。) memset()的作用是在一段内存块中填充某个给定的值。因为它只能填充一个值,所以该函数的初始化为原始初始化,无法将变量初始化为程序中需要的数据。用memset初始化完后,后面程序中再向该内存空间中存放需要的数据。memset一般使用“0”初始化内存单元,而且通常是给数组或结构体进行初始化。一般的变量如char、int、float、double等类型的变量直接初始化即可,没有必要用memset。如果用memset的话反而显得麻烦。- 当然,数组也可以直接进行初始化,但
memset是对较大的数组或结构体进行清零初始化的最快方法,因为它是直接对内存进行操作的。
字符串数组最好用
"\0"进行初始化。- 使用
memset()对字符串数组进行初始化:虽然参数 c 要求是一个整数,但是整型和字符型是互通的。但是赋值为 ‘\0’ 和 0 是等价的,因为字符 ‘\0’ 在内存中就是 0。所以在memset中初始化为 0 也具有结束标志符 ‘\0’ 的作用,所以通常我们就写“0”。 memset函数的第三个参数 n 的值一般用sizeof()获取。- 注意: 如果是对指针变量所指向的内存单元进行清零初始化,那么一定要先对这个指针变量进行初始化,即要让该指针事先指向一个有效的地址。而且如果使用
memset函数,对指针p所指向的内存单元进行初始化时,n 千万别写成sizeof(p),这是新手经常会犯的错误。因为p是指针变量,不管p指向什么类型的变量,sizeof ( p)的值都是4。
C语言中的指针和数组名不完全等价,不能将它们混为一谈。
- 函数功能: 将指针变量
编写一个程序:
# include <stdio.h>
# include <string.h>
int main(void)
{
int i; //循环变量
char str[10];
char *p = str;
memset(str, 0, sizeof(str)); //只能写sizeof(str), 不能写sizeof(p)
for (i=0; i<10; ++i)
{
printf("%d\x20", str[i]);
}
printf("\n");
return 0;
}
结果:
根据memset函数的不同,输出结果也不同,分为以下几种情况:
memset(p, 0, sizeof(p)); //地址的大小都是4字节
0 0 0 0 -52 -52 -52 -52 -52 -52memset(p, 0, sizeof(*p)); //*p表示的是一个字符变量, 只有一字节
0 -52 -52 -52 -52 -52 -52 -52 -52 -52memset(p, 0, sizeof(str));
0 0 0 0 0 0 0 0 0 0memset(str, 0, sizeof(str));
0 0 0 0 0 0 0 0 0 0memset(p, 0, 10); //直接写10也行, 但不专业
0 0 0 0 0 0 0 0 0 0

【例2】
一矩形阵列由数字0到9组成,数字0到9代表细胞,细胞的定义为沿细胞数字上下左右还是细胞数字则为同一细胞,求给定矩形阵列的细胞个数。如:

分析:
- 从文件中读入
m*n矩阵阵列,将其转换为boolean矩阵存入bz数组中; - 沿
bz数组矩阵从上到下,从左到右,找到遇到的第一个细胞; - 将细胞的位置入队
h,并沿其上、下、左、右四个方向上的细胞位置入队,入队后的位置bz数组置为flase; - 将
h队的队头出队,沿其上、下、左、右四个方向上的细胞位置入队,入队后的位置bz数组置为flase; - 重复4,直至
h队空为止,则此时找出了一个细胞; - 重复2,直至矩阵找不到细胞;
- 输出找到的细胞数。
代码:
#include<cstdio>
using namespace std;
//表示上、下、左、右四个方向:{ x, y,-x,-y};
int dx[4] = {-1, 0, 1, 0},
dy[4] = { 0, 1, 0,-1};
int bz[100][100], num=0, n, m;
void doit(int p, int q)
{
int x,y,t,w,i;
int h[1000][10];
num++;bz[p][q]=0;
t=0;w=1;h[1][1]=p;h[1][2]=q; //遇到的第一个细胞入队
do
{
t++; //队头指针加1
for (i=0;i<=3;i++) //沿细胞的上下左右四个方向搜索细胞
{
x=h[t][1]+dx[i];y=h[t][2]+dy[i];
if ((x>=0)&&(x<m)&&(y>=0)&&(y<n)&&(bz[x][y])) //判断该点是否可以入队
{
w++;
h[w][1]=x;
h[w][2]=y;
bz[x][y]=0;
} //本方向搜索到细胞就入队
}
}while (t<w); //直至队空为止
}
//主函数
int main()
{
int i,j;
char s[100],ch;
scanf("%d%d\n",&m,&n);
for (i=0; i<=m-1;i++ )
for (j=0;j<=n-1;j++ )
bz[i][j]=1; //初始化
for (i=0;i<=m-1;i++)
{
gets(s);
for (j=0;j<=n-1;j++)
if (s[j]=='0') bz[i][j]=0;
}
for (i=0;i<=m-1;i++)
for (j=0;j<=n-1;j++)
if (bz[i][j])
doit(i,j); //在矩阵中寻找细胞
printf("NUMBER of cells=%d",num);
return 0;
}
结果:

【例3】迷宫问题
如下图所示,给出一个N*M的迷宫图和一个入口、一个出口。
编一个程序,打印一条从迷宫入口到出口的路径。这里黑色方块的单元表示走不通(用 -1 表示),白色方块的单元表示可以走(用 0 表示)。只能往上、下、左、右四个方向走。如果无路则输出 “no way.”。
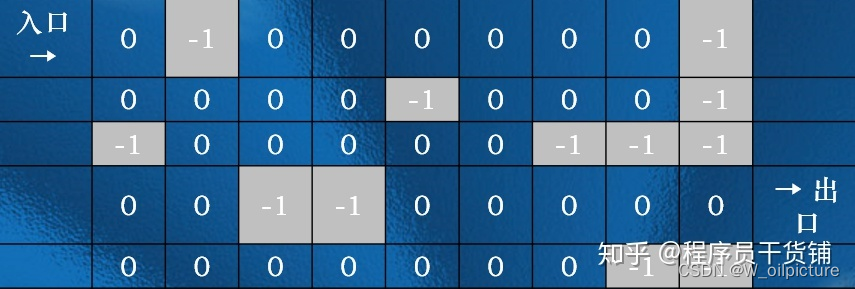
分析:
- 只要输出一条路径即可,所以这是一个经典的回溯算法问题,
1. 回溯算法的 深度优先搜索 的程序代码:
#include<iostream>
using namespace std;
int n, m, desx, desy, soux, souy, totstep, a[51], b[51], map[51][51];
bool f;
int move(int x, int y, int step)
{
map[x][y] = step; //走一步,做标记,把步数记下来
a[step] = x;
b[step] = y; //记路径
if((x==desx)&&(y==desy))
{
f=1;
totstep = step;
}
else
{
if ((y!=m)&&(map[x][y+1]==0)) move(x,y+1,step+1); //向右
if ((!f)&&(x!=n)&&(map[x+1][y]==0)) move(x+1,y,step+1); //往下
if ((!f)&&(y!=1)&&(map[x][y-1]==0)) move(x,y-1,step+1); //往左
if ((!f)&&(x!=1)&&(map[x-1][y]==0)) move(x-1,y,step+1); //往上
}
}
int main()
{
int i, j;
cin >> n >> m;
for(i=1; i<=n; i++) //读入迷宫,0表示通,-1表示不通
{
for(j=1; j<=m; j++)
{
cin >> map[i][j];
}
}
cout << "input the enter:";
cin >> soux >> souy; //入口
cout << "input the exit:";
cin >> desx >> desy; //出口
f=0; //f=0表示无解,f=1表示找到了一个解
move(soux, souy, 1);
if(f)
{
//TODO
for(i=1; i<=totstep; i++)
{
//TODO
cout << a[i] << "," << endl;
}
}
else cout << "no way" << endl;
return 0;
}
2. 回溯算法的 广度优先搜索 的程序代码:
#include <iostream>
using namespace std;
int u[5]={0,0,1,0,-1},
w[5]={0,1,0,-1,0};
int n,m,i,j,desx,desy,soux,souy,head,tail,x,y,a[51],b[51],pre[51],map[51][51];
bool f;
int print(int d)
{
if (pre[d]!=0) print (pre[d]); //递归输出路径
cout<<a[d]<<","<<b[d]<<endl;
}
int main()
{
int i,j;
cin>>n>>m; //n行m列的迷宫
for (i=1;i<=n;i++) //读入迷宫,0表示通,-1表示不通
for (j=1;j<=m;j++)
cin>>map[i][j];
cout<<"input the enter:";
cin>>soux>>souy; //入口
cout<<"input the exit:";
cin>>desx>>desy; //出口
head=0;
tail=1;
f=0;
map[soux][souy]=-1;
a[tail]=soux; b[tail]=souy; pre[tail]=0;
while (head!=tail) //队列不为空
{
head++;
for (i=1;i<=4;i++) //4个方向
{
x=a[head]+u[i]; y=b[head]+w[i];
if ((x>0)&&(x<=n)&&(y>0)&&(y<=m)&&(map[x][y]==0))
{ //本方向上可以走
tail++;
a[tail]=x; b[tail]=y; pre[tail]=head;
map[x][y]=-1;
if ((x==desx)&&(y==desy)) //扩展出的结点为目标结点
{
f=1;
print(tail);
break;
}
}
}
if (f) break;
}
if (!f) cout<<"no way."<<endl;
return 0;
}
















 6654
6654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











