







在本文中,我们使用SPEI作为干旱指数来分析吐哈盆地的干旱情况。SPEI是一种国际上通用的干旱指数,它融合了PDSI对蒸散发的响应和SPI的空间一致性及多时间尺度的优点。该指数目前已被广泛应用于气象、水文、农业和社会经济领域的干旱监测和预报研究。因此,本文基于彭守璋团队发布的1km逐月降水量数据和前文计算得到的ET0-PM数据,参考https://gma.luosgeo.com/UserGuide/climet/Index/SPEI.html,利用gma 2.0.2.1库计算1990-2022年吐哈盆地月尺度、季尺度、半年尺度和年尺度的SPEI。在计算四季的干旱情况时,我们参考前文中的季节划分标准,并分别使用5月、8月、11月和次年2月的SPEI-3来表征各个季节的干旱情况。而年尺度的干旱情况则使用每年12月的SPEI-12来表示。由于吐哈盆地的数据量较大,计算过程超出内存限制。因此,在本文中我们采取批量将PRE和ET0-PM的多波段数据按县进行掩膜,并将裁剪后的结果保存为对应县的数据。最后,为了将6个县(区)的SPEI计算结果汇总并进行分析,本文使用gdal.Warp()函数将各县的SPEI数据进行镶嵌,以便进行后续整体的干旱分析。
1. 单波段合成多波段
批量将1990-2022年吐哈盆地逐月降水量和潜在蒸散发的单波段.tif数据合成多波段.tif

# 批量将一个文件夹内的所有单波段栅格数据.tif合成一个多波段的.tif文件
# 导入需要的库
from osgeo import gdal # 处理地理数据
import os # 文件操作
# 根据自己的情况设置输入文件夹路径和输出文件路径
tifDir = r"D:\dissertation\SPEI\PRE"
outtif = r"D:\dissertation\SPEI\PRE_199001-202212.tif"
# tifDir = r"D:\dissertation\SPEI\PET"
# outtif = r"D:\dissertation\SPEI\PET_199001-202212.tif"
# 定义数据类型转换字典
NP2GDAL_CONVERSION = {
"uint8": 1,
"int8": 1,
"uint16": 2,
"int16": 3,
"uint32": 4,
"int32": 5,
"float32": 6,
"float64": 7,
"complex64": 10,
"complex128": 11,
}
# 使用列表推导式获取输入文件夹中以.tif结尾的文件列表
tifs = [i for i in os.listdir(tifDir) if i.endswith(".tif")]
# 获取第一个.tif文件的投影、地理变换、列数、行数、数据类型等信息
bandsNum = len(tifs) # 获取波段数,即.tif文件的数量
dataset = gdal.Open(os.path.join(tifDir,tifs[0])) # 打开第一个.tif文件
projinfo = dataset.GetProjection() # 获取投影信息
geotransform = dataset.GetGeoTransform() # 获取地理变换信息
cols,rows=dataset.RasterXSize,dataset.RasterYSize # 获取列数和行数
datatype=dataset.GetRasterBand(1).ReadAsArray(0,0,1,1).dtype.name # 获取数据类型
gdaltype=NP2GDAL_CONVERSION[datatype] # 将数据类型转换为GDAL数据类型
dataset=None # 关闭第一个.tif文件
# 使用GDAL创建输出文件,并设置地理变换和投影信息
format = "GTiff" # 设置输出文件格式为.tif
driver = gdal.GetDriverByName(format) # 获取对应格式的驱动程序
dst_ds = driver.Create(outtif,cols, rows,bandsNum, gdaltype,options=['COMPRESS=LZW']) # 创建输出文件,设置列数、行数、波段数和数据类型,并添加压缩选项
dst_ds.SetGeoTransform(geotransform) # 设置输出文件的地理变换信息
dst_ds.SetProjection(projinfo) # 设置输出文件的投影信息
# 循环遍历每个.tif文件,将其数据写入到输出文件中对应的波段中
info = set() # 创建一个集合,用于存储每个.tif文件的列数和行数
for k in range(bandsNum): # 遍历每个.tif文件
ds = gdal.Open(os.path.join(tifDir,tifs[k])) # 打开当前.tif文件
X,Y = ds.RasterXSize,ds.RasterYSize # 获取当前.tif文件的列数和行数
info.add("%s,%s"%(X,Y)) # 将列数和行数添加到集合中
if(len(info) != 1): # 如果集合中的元素不唯一(即有.tif文件的列数或行数与其他文件不同)
dst_ds = None # 关闭输出文件
ds = None # 关闭当前.tif文件
print("%s 列数行数不一样:%s,%s"%(tifs[k],X,Y)) # 打印出列数和行数不一致的.tif文件名和对应的列数和行数
raise Exception("有影像行列数不一致") # 抛出异常,终止程序运行
data = ds.GetRasterBand(1).ReadAsArray() # 读取当前.tif文件的第一个波段的数据
ds = None # 关闭当前.tif文件
dst_ds.GetRasterBand(k+1).WriteArray(data) # 将数据写入到输出文件的对应波段中
dst_ds.GetRasterBand(k+1).SetDescription("hahha_%s"%k) # 设置输出文件的波段描述
print("波段 %s ==> 文件 %s"%(k+1,tifs[k])) # 打印输出当前波段和对应的.tif文件名
# 关闭输出文件
dst_ds = None2. 按县分割合成的多波段数据
1)利用ArcMap 10.8.2里“分割”工具批量生成吐哈各县(区)矢量数据
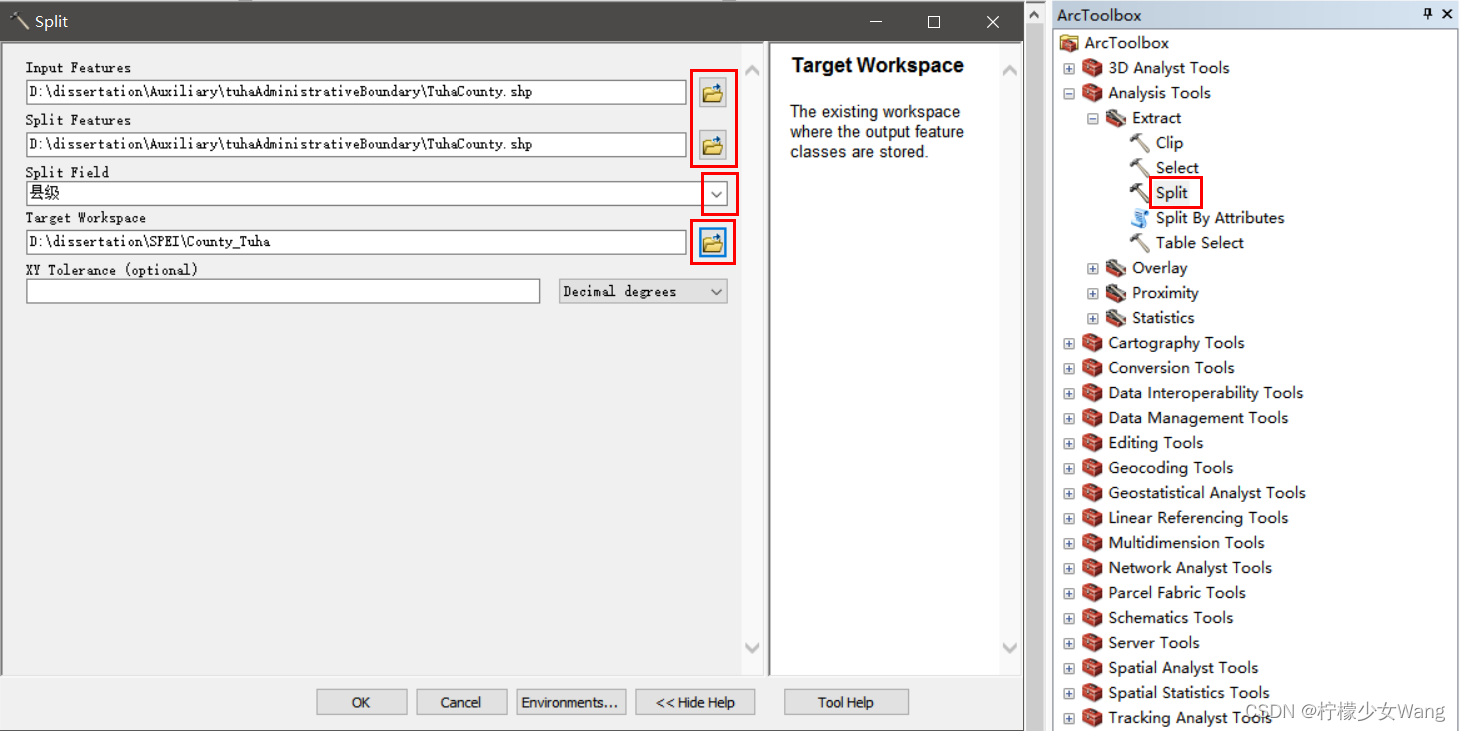
2)按县掩膜前面合成的多波段栅格数据
# 按县掩膜合成的多波段栅格数据
# 导入需要的库
import os # 操作文件和文件夹
import rasterio # 处理栅格数据
import fiona # 处理矢量数据
from rasterio.mask import mask # 裁剪栅格数据
# 吐哈各县(区)矢量文件存放文件夹
vector_folder = "D:/dissertation/SPEI/County_Tuha"
# 多波段栅格文件路径
raster_file = "D:/dissertation/SPEI/PET_199001-202212.tif"
# raster_file = "D:/dissertation/SPEI/PRE_199001-202212.tif"
# 裁剪后的结果保存路径
output_folder = "D:/dissertation/SPEI/Mask_ComositeBands_PRE-PET"
# 遍历矢量文件夹中的所有矢量文件
for filename in os.listdir(vector_folder):
if filename.endswith(".shp"): # 如果文件以.shp结尾(即矢量文件)
vector_file = os.path.join(vector_folder, filename) # 构建矢量文件路径
with rasterio.open(raster_file) as src: # 使用rasterio打开栅格文件
with fiona.open(vector_file, "r") as shapefile: # 使用fiona打开矢量文件
shapes = [feature["geometry"] for feature in shapefile] # 获取矢量文件的几何形状
out_image, out_transform = mask(src, shapes, crop=True) # 使用mask函数裁剪栅格数据
out_meta = src.meta.copy() # 复制栅格数据的元数据
# 更新元数据的变换参数
out_meta.update({"driver": "GTiff",
"height": out_image.shape[1],
"width": out_image.shape[2],
"transform": out_transform})
# 构建结果保存文件路径
output_file = os.path.join(output_folder, f"PET_199001-202212_{filename}.tif")
# output_file = os.path.join(output_folder, f"PRE_199001-202212_{filename}.tif")
# 保存裁剪后的栅格数据
with rasterio.open(output_file, "w", **out_meta) as dest: # 使用rasterio创建并打开输出文件
dest.write(out_image) # 将裁剪后的栅格数据写入输出文件
3. 利用gma库计算SPEI
1)分县计算SPEI
# 使用gma库计算1990-2022年吐哈盆地标准化降水蒸散指数SPEI
# 参考:https://gma.luosgeo.com/UserGuide/climet/Index/SPEI.html
# 说明:整个吐哈盆地一起计算会超内存,所以分县计算
# 导入需要的库和模块
import numpy as np
import gma
from gma import io
# 读取月降水量和潜在蒸散量数据
PRESet = io.Open("D:/dissertation/SPEI/Mask_ComositeBands_PRE-PET/PRE_199001-202212_伊州区.shp.tif")
PETSet = io.Open("D:/dissertation/SPEI/Mask_ComositeBands_PRE-PET/PET_199001-202212_伊州区.shp.tif")
# 读取数据到数组
PRE = PRESet.ToArray()
PET = PETSet.ToArray()
# 读取的数据为三维数据(波段,行,列),第一维为时间序列(月数据),因此按照轴 0 来计算
# 时间尺度为SPEI-1、SPEI-3、SPEI-6、SPEI-12,分别对应月尺度、季尺度、半年和年尺度
SPEI1 = gma.climet.Index.SPEI(PRE, PET, Axis = 0)
SPEI3 = gma.climet.Index.SPEI(PRE, PET, Axis = 0, Scale = 3)
SPEI6 = gma.climet.Index.SPEI(PRE, PET, Axis = 0, Scale = 6)
SPEI12 = gma.climet.Index.SPEI(PRE, PET, Axis = 0, Scale = 12)
# 存储计算结果
S = [1,3,6,12]
for i in S:
# 保存所有结果中的非全 nan 波段。即:去除时间尺度累积时序列前无效的波段。
io.SaveArrayAsRaster(eval(f'SPEI{i}')[i-1:],
fr'D:\dissertation\SPEI\result\SPEI-{i}_1990-2022_伊州区.tif',
Projection = PRESet.Projection,
Transform = PRESet.GeoTransform,
DataType = 'Float32',
NoData = np.nan) 
2)镶嵌合并为一个栅格
# 将各县计算的SPEI拼接为整个吐哈
# 导入所需的库
import os
from osgeo import gdal
# 设置输入文件夹和输出文件路径
input_folder = r'D:\dissertation\SPEI\result\SPEI-1'
output_file = r'D:\dissertation\SPEI\result\SPEI-1.tif'
# input_folder = r'D:\dissertation\SPEI\result\SPEI-3'
# output_file = r'D:\dissertation\SPEI\result\SPEI-3.tif'
# input_folder = r'D:\dissertation\SPEI\result\SPEI-6'
# output_file = r'D:\dissertation\SPEI\result\SPEI-6.tif'
# input_folder = r'D:\dissertation\SPEI\result\SPEI-12'
# output_file = r'D:\dissertation\SPEI\result\SPEI-12.tif'
# 获取输入文件夹中的所有.tif文件
input_files = [os.path.join(input_folder, f) for f in os.listdir(input_folder) if f.endswith('.tif')]
# 设置输出文件的空间参考和分辨率
output_projection = 'EPSG:4326' # 设置输出文件的空间参考,这里使用WGS84经纬度坐标系
output_resolution = 0.0083333333 # 设置输出文件的分辨率,单位为度
# 使用gdal.Warp()函数进行镶嵌
gdal.Warp(output_file, input_files, format='GTiff', outputBounds=None, xRes=output_resolution, yRes=output_resolution, dstSRS=output_projection)
print("镶嵌完成!")
4. 将计算的SPEI分离成单波段
# 将SPEI多波段.tif文件分离成单波段数据,并保存为.tif格式的文件
# 导入需要的库
import numpy as np # 处理数组和矩阵
import os # 操作文件和目录
import random # 生成随机数
from osgeo import gdal # 取和写入地理空间数据
import tifffile as tif # 读取和写入.tif格式文件
from skimage import data,exposure # 图像处理
from sklearn import preprocessing # 数据预处理
# 定义读取图像像素矩阵函数,其中fileName为图像文件名
def readTif(fileName):
dataset = gdal.Open(fileName) # 使用gdal库打开图像文件
# width = dataset.RasterXSize
# height = dataset.RasterYSize
# GdalImg_data = dataset.ReadAsArray(0, 0, width, height)
# return GdalImg_data
return dataset # 返回数据集对象
# 定义保存tif文件函数
def writeTiff(im_data,im_geotrans,im_proj,path):
if 'int8' in im_data.dtype.name: # 判断数据类型是否为int8
datatype=gdal.GDT_Byte # 设置数据类型为Byte
elif 'int16' in im_data.dtype.name: # 判断数据类型是否为int16
datatype=gdal.GDT_UInt16 # 设置数据类型为UInt16
else:
datatype=gdal.GDT_Float32 # 设置数据类型为Float32
if len(im_data.shape)==3: # 判断数据维度是否为3
im_bands,im_height,im_width=im_data.shape # 获取波段数、高度和宽度
elif len(im_data.shape)==2: # 判断数据维度是否为2
im_data=np.array([im_data]) # 将数据转换为3维数组
im_bands,im_height,im_width=im_data.shape # 获取波段数、高度和宽度
driver=gdal.GetDriverByName("GTiff") # 获取GTiff驱动
dataset=driver.Create(path,int(im_width),int(im_height),int(im_bands),datatype) # 创建.tif文件
if(dataset!=None):
dataset.SetGeoTransform(im_geotrans) # 写入仿射变换参数
dataset.SetProjection(im_proj) # 写入投影
for i in range(im_bands): # 遍历波段
dataset.GetRasterBand(i+1).WriteArray(im_data[i]) # 将波段数据写入.tif文件
del dataset # 删除数据集对象
# 定义波段分离函数
def bandsclip(path1,path2):
dataset_img=readTif(path1) # 读取图像数据集
width=dataset_img.RasterXSize # 获取图像宽度
height=dataset_img.RasterYSize # 获取图像高度
proj=dataset_img.GetProjection() # 获取图像投影
geotrans=dataset_img.GetGeoTransform() # 获取图像仿射变换参数
img=dataset_img.ReadAsArray(0,0,width,height) # 读取图像数据
img_out=[] # 定义空列表
for i in range(img.shape[0]): # 遍历波段
img_out=np.array(img[i,::]) # 获取当前波段数据
writeTiff(img_out,geotrans,proj,path2+str(i)+'.tif') # 将波段数据保存为.tif文件,文件名根据波段索引命名,出波段的名称命名格式可以修改,结合传递的path2参数
# 切换当前工作目录
os.chdir(r'D:/dissertation/SPEI/result')
path1=r'SPEI-1.tif' # 要分离波段的原始图像数据名称
path2=r'./SPEI-1/SPEI-1_' # 分离的各波段结果图像部分名称
bandsclip(path1,path2) # 调用波段分离函数
print('Bandsclip END!') # 打印输出DIR *.* /B >LIST.csv
后面就可以继续进行时空变化等的分析














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









