






常见面试题学习,包括python、测试基础和持续集成
1.谈谈HTTP和HTTPS的区别,GET和POST的区别,cookie、session和token的区别
一、HTTP 与 HTTPS 的区别
1. 协议本质
- HTTP(超文本传输协议)
- 基于 TCP/IP 的明文传输协议,用于客户端(浏览器)与服务端之间的数据交互。
- 端口默认 80。
- 不安全:数据在传输过程中可能被窃取、篡改或伪造。
- HTTPS(安全超文本传输协议)
- 在 HTTP 基础上叠加 SSL/TLS 加密层,实现加密传输、身份验证和数据完整性保护。
- 端口默认 443。
- 安全:通过数字证书(CA 认证)、对称加密(AES)和非对称加密(RSA)确保数据安全。
2. 核心差异
| 维度 | HTTP | HTTPS |
|---|---|---|
| 安全性 | 明文传输,易被窃听、篡改 | 加密传输(SSL/TLS),防止中间人攻击 |
| 连接建立 | 直接建立 TCP 连接 | 需额外完成 TLS 握手(耗时约 200-500ms) |
| 资源消耗 | 低(无需加密计算) | 高(加密 / 解密消耗 CPU 和内存) |
| 搜索引擎优化 | 部分搜索引擎(如 Google)可能降低权重 | 优先索引(Google 已将 HTTPS 作为排名因素) |
| 证书要求 | 无需证书 | 需要 CA 颁发的数字证书(付费或免费,如 Let's Encrypt) |
| 适用场景 | 非敏感数据(如公开新闻网站) | 敏感数据(如支付、登录、个人信息) |
3. HTTPS 的优势
- 加密传输:防止用户密码、信用卡信息等敏感数据泄露。
- 身份验证:确保访问的是真实服务端(而非伪造的钓鱼网站)。
- 数据完整性:通过哈希算法(如 SHA-256)验证数据未被篡改。
二、GET 与 POST 的区别
1. 设计初衷
- GET
- 幂等性操作:用于获取资源(如查询数据),理论上不会对服务端产生副作用。
- 请求参数通过 URL 明文传递,直接可见。
- POST
- 非幂等性操作:用于提交数据(如创建资源、修改状态),可能改变服务端状态。
- 请求参数通过 请求体(Body)传递,URL 中不直接显示。
2. 核心差异
| 维度 | GET | POST |
|---|---|---|
| 参数位置 | URL(如 ?key=value&name=test) | 请求体(Body,需设置 Content-Type) |
| 参数长度限制 | 受限于浏览器 / 服务器(通常 ≤ 2KB) | 无固定限制(取决于服务器配置) |
| 安全性 | 低(参数明文暴露在 URL 中) | 较高(参数不暴露在 URL 中,但需配合加密传输) |
| 幂等性 | 幂等(多次请求结果相同) | 非幂等(多次提交可能创建多个资源) |
| 缓存支持 | 支持(浏览器可缓存 GET 响应) | 不支持(POST 通常用于动态操作) |
| 适用场景 | 查询、搜索、获取静态资源 | 提交表单、上传文件、修改数据 |
3. 注意事项
- 安全性误区:
GET 和 POST 本身不保证数据安全,敏感操作必须配合 HTTPS。例如,POST 的参数虽不在 URL 中,但在 HTTP 协议下仍为明文传输。 - 语义化使用:
遵循 RESTful 规范,GET 用于查询(/users?id=1),POST 用于创建(/users),PUT 用于更新,DELETE 用于删除。
三、Cookie、Session 与 Token 的区别
1. 基本概念
- Cookie
- 由服务端生成,存储在客户端(浏览器)的键值对数据,随每次 HTTP 请求自动发送到服务端。
- 常见用途:会话保持(如登录状态)、存储用户偏好(如主题设置)。
- Session
- 服务端用于存储用户会话状态的机制,通过 Cookie 中的 Session ID 关联客户端请求。
- 数据存储在服务端(内存、数据库或缓存),客户端仅存储 Session ID。
- Token
- 服务端生成的加密字符串,用于客户端请求时的身份验证,通常通过 HTTP 头部(如
Authorization: Bearer <token>)传递。 - 常见方案:JWT(JSON Web Token)、OAuth 2.0 令牌。
- 服务端生成的加密字符串,用于客户端请求时的身份验证,通常通过 HTTP 头部(如
2. 核心差异
| 维度 | Cookie | Session | Token |
|---|---|---|---|
| 存储位置 | 客户端(浏览器) | 服务端(内存 / 数据库 / 缓存) | 客户端(通常存于内存或 LocalStorage) |
| 数据安全性 | 低(明文存储,可通过 HttpOnly 增强) | 高(敏感数据存于服务端) | 高(加密传输,无状态设计) |
| 跨域支持 | 受同源策略限制 | 受同源策略限制 | 支持跨域(通过 CORS 或自定义头部) |
| 服务端状态 | 无状态(客户端携带所有信息) | 有状态(服务端需维护会话数据) | 无状态(服务端无需存储用户信息) |
| 扩展性 | 较差(大小限制通常 ≤ 4KB) | 较差(分布式架构需共享会话存储) | 优秀(适用于微服务、前后端分离) |
| 典型场景 | 登录状态保持、用户偏好设置 | 传统 Web 应用的会话管理 | 现代 API 认证(如移动端、单页应用) |
3. 深入对比
- Cookie 的局限性
- 大小受限(通常每个域名下 Cookie 不超过 4KB),且会增加每次请求的头部开销。
- 跨域时需配合
SameSite属性(如Strict/Lax)防止 CSRF 攻击。
- Session 的痛点
- 分布式架构中需解决 Session 共享问题(如通过 Redis 缓存 Session ID)。
- 服务端存储压力大,不适合高并发场景。
- Token 的优势
- 无状态设计:服务端无需存储用户会话,可轻松扩展至分布式 / 微服务架构。
- 跨平台兼容:适用于浏览器、移动端、小程序等多端场景。
- 细粒度控制:可通过设置过期时间(如 JWT 的
exp字段)、权限范围(如scope)实现灵活的权限管理。
四、实际应用建议
- 协议选择
- 所有涉及用户隐私或交易的场景必须使用 HTTPS,普通静态页面可按需选择 HTTP(需权衡 SEO 和安全性)。
- 请求方法选择
- 查询操作优先用 GET,提交 / 修改操作优先用 POST/PUT/DELETE,遵循 RESTful 规范。
- 身份认证方案
- 传统 Web 应用:Cookie + Session(配合 HttpOnly/Secure 属性增强安全性)。
- 前后端分离应用 / API:Token(如 JWT),存储于
LocalStorage或内存,通过请求头传递。 - 跨域场景:Token 方案更优(避免 Cookie 的同源策略限制)。
2.如何估算测试的工作量
估算测试工作量是软件项目管理中的关键环节,需要结合项目需求、团队能力、技术复杂度等多维度因素。以下是一套系统化的估算方法,涵盖核心步骤、常用方法、影响因素和工具建议,帮助提升估算准确性:
一、明确测试范围与目标
1. 界定测试边界
- 功能范围:需测试的功能模块(如用户登录、支付流程、API 接口)、业务场景(正向 / 逆向流程)。
- 测试类型:单元测试、集成测试、系统测试、性能测试、安全测试、兼容性测试等。
- 非功能需求:性能指标(如响应时间、并发量)、兼容性要求(浏览器 / 设备版本)、合规性(如 GDPR)。
示例:
若项目为 “电商平台订单系统”,测试范围可能包括:
- 功能测试:下单、取消订单、支付、退款等流程;
- 性能测试:峰值并发下的订单处理速度;
- 兼容性测试:不同浏览器(Chrome/Safari)和移动端(iOS/Android)的适配。
2. 输出物定义
明确测试过程中需产出的文档和成果,例如:
- 测试计划、用例设计、缺陷报告、测试报告;
- 自动化脚本、性能测试报告、安全扫描报告。
二、分解测试任务(WBS 工作分解)
将测试工作拆解为可量化、可跟踪的子任务,通常包括以下阶段:
1. 测试前期准备
- 需求分析与评审(理解业务逻辑、识别风险点);
- 测试方案设计(确定测试策略、工具选型);
- 测试环境搭建(服务器、数据库、第三方服务配置);
- 测试数据准备(模拟生产数据、敏感数据脱敏)。
2. 执行阶段
- 用例设计与评审(按功能模块编写测试用例);
- 手工测试执行(按用例逐步验证功能);
- 自动化测试开发与执行(编写脚本、持续集成);
- 专项测试(性能、安全、兼容性等)。
3. 后期收尾
- 缺陷跟踪与回归测试(验证修复结果);
- 测试报告编写与评审(总结覆盖率、遗留问题);
- 交付物验收与归档。
工具建议:使用 XMind/MindManager 绘制思维导图分解任务,或通过 Jira/Trello 创建任务列表并关联负责人。
三、选择估算方法
1. 专家判断法(类比法)
- 适用场景:有类似项目经验参考时。
- 操作步骤:
- 找到历史相似项目(如 “某电商平台支付模块测试”);
- 对比当前项目与历史项目的差异(功能复杂度、团队经验、技术栈等);
- 按差异调整工作量(如当前项目复杂度高 20%,则在历史数据基础上增加 20%)。
示例:
历史项目 “订单模块测试” 耗时 15 人天,当前项目新增 “跨境支付” 功能(复杂度 + 30%),估算为 15×1.3=19.5 人天。
2. 功能点分析法(FPA)
- 适用场景:需求明确、功能模块可量化的项目。
- 操作步骤:
- 将功能拆分为原子功能点(如 “用户注册” 为 1 个功能点,“支付” 含 3 个功能点:选支付方式、输入密码、确认);
- 为每个功能点分配复杂度权重(简单 / 中等 / 复杂,对应系数如 1/2/3);
- 按团队历史效率(如平均每个功能点耗时 2 人天)计算总工作量。
公式:
总工作量 = Σ(功能点数量 × 复杂度系数)× 单位耗时
示例:
- 功能点:用户登录(中等,系数 2)、商品搜索(简单,系数 1)、订单提交(复杂,系数 3);
- 数量:各 1 个功能点;
- 单位耗时:2 人天 / 系数单位;
- 总工作量 = (2+1+3)×2 = 12 人天。
3. 三点估算(PERT 法)
- 适用场景:需求不确定性高、需考虑风险时。
- 操作步骤:
- 对每个任务估算三种时间:
- 乐观时间(O):最短完成时间(如无风险时);
- 悲观时间(P):最长完成时间(如遇重大问题);
- 最可能时间(M):正常情况下的时间;
- 按公式计算期望时间(TE):
TE = (O + 4M + P) / 6
- 对每个任务估算三种时间:
示例:
测试环境搭建任务:
- O=2 天,M=3 天,P=5 天;
- TE=(2+4×3+5)/6 = 3.17 天(约 3.5 人天)。
4. 敏捷估算(故事点法)
- 适用场景:敏捷开发模式,需求分阶段迭代。
- 操作步骤:
- 将测试任务转化为用户故事(如 “作为用户,我需要在 iOS 上正常下单”);
- 团队通过计划扑克等方式为每个故事分配故事点(如 1、2、3、5、8 等斐波那契数列);
- 根据历史迭代速度(如团队平均每迭代完成 20 故事点)估算时间。
示例:
某迭代包含 30 故事点的测试任务,团队速度为 10 故事点 / 周,估算耗时 3 周。
四、考虑影响工作量的关键因素
1. 项目因素
- 需求变更频率:频繁变更会导致测试用例反复修改、回归测试工作量增加(建议预留 10%-20% 缓冲);
- 技术复杂度:新框架 / 技术栈可能增加学习成本(如从手工测试转向自动化测试);
- 集成度:多系统对接场景(如电商平台对接物流、支付系统)需更多接口测试和联调时间。
2. 团队因素
- 人员经验:初级测试人员效率约为资深人员的 50%-70%;
- 团队协作效率:跨部门协作(如与开发、产品团队沟通)可能增加沟通成本。
3. 环境因素
- 测试环境稳定性:环境频繁崩溃会导致测试中断(如每天因环境问题损失 1 小时,按 5 天 / 周计算,每周增加 5 人时);
- 数据准备难度:需模拟百万级数据时,数据生成和清理可能占用大量时间。
五、汇总与评审
1. 工作量汇总
将各阶段任务的估算结果累加,形成初步估算表。例如:
| 任务阶段 | 任务名称 | 估算(人天) | 备注 |
|---|---|---|---|
| 测试准备 | 需求评审 | 2 | 含与开发团队联调 |
| 环境搭建 | 3.5 | 三点估算结果 | |
| 执行阶段 | 功能测试用例设计 | 5 | 200 个用例 |
| 自动化脚本开发 | 8 | 含 50 个核心场景脚本 | |
| 专项测试 | 性能测试 | 6 | 含 3 轮压测 |
| 合计 | — | 27.5 | 未包含 20% 缓冲 |
2. 风险缓冲
- 为应对需求变更、环境问题等不确定性,建议在总估算基础上增加 10%-30% 缓冲。
示例:上述 27.5 人天 + 20% 缓冲 = 33 人天。
3. 评审与校准
- 组织跨职能评审会(开发、测试、产品经理参与),验证估算合理性;
- 参考行业基准数据(如 ISBSG 基准数据库:平均每功能点测试耗时约 3-5 人天)进行校准。
六、工具与最佳实践
1. 常用工具
- 估算工具:Microsoft Project(甘特图与工作量分配)、Toggl(时间追踪,用于历史数据积累);
- 测试管理工具:TestRail(用例管理与进度跟踪)、Zephyr(Jira 插件,支持敏捷估算)。
2. 最佳实践
- 分阶段估算:初期用类比法做粗粒度估算(误差 ±30%),需求明确后用功能点法细化(误差 ±10%);
- 持续跟踪与复盘:每次项目结束后记录实际耗时与估算差异,形成团队专属的估算知识库;
- 自动化提效:对重复执行的测试任务(如冒烟测试)开发自动化脚本,减少手工耗时(据统计,自动化可节省 30%-70% 执行时间)。
3.测试评估的目的和重点
测试评估的目的
测试评估是软件测试流程中的关键环节,其核心目的是通过系统性分析测试过程和结果,为项目决策提供依据,确保软件质量与项目目标的一致性。具体包括以下几点:
-
验证软件质量
- 评估软件是否满足需求规格说明书、设计文档及用户期望的功能、性能、安全性等质量指标。
- 识别潜在缺陷的严重程度和影响范围,判断是否达到上线或交付标准。
-
控制项目风险
- 分析测试中发现的问题(如进度延迟、资源不足、技术难点),评估对项目周期、成本和质量的风险。
- 为项目管理者提供数据支持,以便及时调整资源分配、优化计划或调整需求。
-
优化测试过程
- 评估测试方法、工具和流程的有效性,发现测试过程中的不足(如用例覆盖率低、自动化效率差)。
- 积累经验,为后续项目提供改进方向,提升团队整体测试能力。
-
促进沟通与决策
- 向开发团队、产品经理、管理层等 stakeholders 传递测试结果,对齐对软件质量的认知。
- 帮助决策者判断是否需要进一步测试、是否接受缺陷或是否延期发布。
测试评估的重点
测试评估需围绕质量、效率、风险三大维度展开,具体重点如下:
一、质量评估:软件是否 “合格”
-
缺陷分析
- 缺陷数量与趋势:统计不同阶段(如单元测试、集成测试、系统测试)的缺陷发现率、修复率,分析缺陷是否收敛(如后期缺陷数是否显著减少)。
- 缺陷严重程度:区分致命缺陷(如系统崩溃)、严重缺陷(如功能不可用)、一般缺陷(如界面错位)、建议性问题,评估对用户体验和业务的影响。
- 遗留缺陷风险:未修复的缺陷是否影响核心功能,是否需制定风险预案(如临时解决方案、版本迭代计划)。
-
覆盖率评估
- 用例覆盖率:已执行的测试用例占总用例的比例,是否覆盖所有功能点、业务流程和边界条件。
- 代码覆盖率(如适用):通过工具(如 JaCoCo、Coverage.py)统计代码行、分支、路径的覆盖情况,评估测试的充分性。
- 需求覆盖率:验证需求规格说明书中的每一条需求是否都被测试用例覆盖,避免遗漏。
-
非功能质量
- 性能指标:响应时间、吞吐量、资源利用率(CPU / 内存 / 磁盘)是否满足设计要求,是否存在性能瓶颈。
- 安全性:是否通过渗透测试、漏洞扫描(如 OWASP Top 10),敏感数据是否加密,权限控制是否合规。
- 兼容性与可靠性:在不同浏览器、设备、网络环境下的表现是否一致,系统是否稳定(如崩溃率、错误恢复能力)。
二、效率评估:测试过程是否 “高效”
-
进度与成本
- 计划 vs 实际:测试阶段的时间、人力投入是否与计划偏差,分析延期原因(如需求变更、环境搭建延迟)。
- 资源利用率:测试工具、硬件设备、人力是否被合理使用,是否存在等待或闲置情况。
-
测试方法与工具
- 自动化效果:自动化测试用例的执行率、故障率、节省的时间成本,是否提升回归测试效率。
- 手工测试必要性:是否存在过度依赖手工测试的场景,是否需要优化用例或引入更多自动化。
-
团队协作
- 开发与测试团队的沟通效率(如缺陷定位耗时、修复反馈速度)。
- 需求变更时,测试团队的响应速度和调整成本。
三、风险评估:未来可能出现的 “隐患”
-
技术风险
- 新技术、新框架的使用是否引入未知问题,如兼容性或性能风险。
- 第三方组件或依赖项的安全性(如开源库漏洞)。
-
业务风险
- 未覆盖的关键业务场景可能导致用户投诉或经济损失(如支付流程缺陷)。
- 合规性风险(如数据隐私法规不符合 GDPR、等保要求)。
-
发布风险
- 遗留缺陷在生产环境中的潜在影响,如高概率复现的低级缺陷可能引发用户流失。
- 上线后的监控与应急响应预案是否完备。
总结
测试评估需以数据为基础,结合定性与定量分析,平衡质量、效率和风险。其核心是通过客观的评估结果,帮助团队做出科学决策,确保软件在满足用户需求的同时,实现项目的可持续改进。
4.python中list添加元素有哪些方法、删除元素有哪些方法
一、添加元素的方法
1. append():在列表末尾添加单个元素
- 语法:
list.append(element) - 特点:
- 直接修改原列表,返回值为
None。 - 只能添加一个元素,参数可以是任意数据类型(包括列表、字典等)。
- 直接修改原列表,返回值为
示例:
fruits = ['apple', 'banana']
fruits.append('cherry')
print(fruits) # 输出: ['apple', 'banana', 'cherry']
# 添加列表作为元素(嵌套列表)
fruits.append(['grape', 'mango'])
print(fruits) # 输出: ['apple', 'banana', 'cherry', ['grape', 'mango']]
2. extend():在列表末尾添加多个元素(可迭代对象)
- 语法:
list.extend(iterable) - 特点:
- 将可迭代对象(如列表、元组、字符串)的元素逐个添加到原列表末尾。
- 修改原列表,返回值为
None。
示例:
fruits = ['apple', 'banana']
fruits.extend(['cherry', 'date']) # 添加列表元素
print(fruits) # 输出: ['apple', 'banana', 'cherry', 'date']
fruits.extend('egg') # 添加字符串元素(拆分为字符)
print(fruits) # 输出: ['apple', 'banana', 'cherry', 'date', 'e', 'g', 'g']
3. insert():在指定位置插入元素
- 语法:
list.insert(index, element) - 特点:
- 在
index位置前插入元素,原元素依次后移。 - 若
index为负数或超出列表长度,自动调整到合法位置(如index=-1插入倒数第二个位置)。
- 在
示例:
fruits = ['apple', 'banana']
fruits.insert(1, 'cherry') # 在索引1处插入
print(fruits) # 输出: ['apple', 'cherry', 'banana']
fruits.insert(100, 'date') # 索引超出范围,插入末尾
print(fruits) # 输出: ['apple', 'cherry', 'banana', 'date']
4. 运算符 + 和 +=
+:创建新列表,合并两个列表。+=:等价于extend(),直接修改原列表。
示例:
a = [1, 2]
b = [3, 4]
# 使用 + 创建新列表
c = a + b
print(c) # 输出: [1, 2, 3, 4]
# 使用 += 扩展原列表
a += b
print(a) # 输出: [1, 2, 3, 4]
二、删除元素的方法
1. remove():根据值删除第一个匹配项
- 语法:
list.remove(value) - 特点:
- 删除列表中第一个等于
value的元素。 - 若元素不存在,抛出
ValueError。 - 修改原列表,返回值为
None。
- 删除列表中第一个等于
示例:
fruits = ['apple', 'banana', 'cherry', 'banana']
fruits.remove('banana')
print(fruits) # 输出: ['apple', 'cherry', 'banana'](只删除第一个)
# fruits.remove('grape') # 报错:ValueError: list.remove(x): x not in list
2. pop():根据索引删除元素并返回
- 语法:
list.pop([index]) - 特点:
- 默认删除并返回最后一个元素(
index省略时)。 - 指定
index可删除任意位置元素,若索引越界,抛出IndexError。
- 默认删除并返回最后一个元素(
示例:
fruits = ['apple', 'banana', 'cherry']
last = fruits.pop() # 删除最后一个元素
print(last) # 输出: 'cherry'
print(fruits) # 输出: ['apple', 'banana']
second = fruits.pop(1) # 删除索引1的元素
print(second) # 输出: 'banana'
print(fruits) # 输出: ['apple']
3. del 语句:根据索引或切片删除元素
- 语法:
del list[index]或del list[start:stop:step] - 特点:
- 直接删除指定位置或范围内的元素,无返回值。
- 支持切片操作,可批量删除元素。
示例:
fruits = ['apple', 'banana', 'cherry', 'date', 'elderberry']
# 删除单个元素
del fruits[2]
print(fruits) # 输出: ['apple', 'banana', 'date', 'elderberry']
# 删除切片(批量删除)
del fruits[1:3]
print(fruits) # 输出: ['apple', 'elderberry']
4. clear():清空列表所有元素
- 语法:
list.clear() - 特点:
- 删除列表内所有元素,列表变为空列表
[]。 - 修改原列表,返回值为
None。
- 删除列表内所有元素,列表变为空列表
示例:
fruits = ['apple', 'banana']
fruits.clear()
print(fruits) # 输出: []
三、其他操作(非直接添加 / 删除)
1. 替换元素
通过索引直接赋值修改元素:
fruits = ['apple', 'banana']
fruits[0] = 'cherry' # 替换索引0的元素
print(fruits) # 输出: ['cherry', 'banana']
2. 列表推导式(间接删除)
通过条件过滤创建新列表:
fruits = ['apple', 'banana', 'cherry', 'date']
fruits = [x for x in fruits if len(x) > 5] # 保留长度>5的元素
print(fruits) # 输出: ['banana', 'cherry']
四、性能对比
| 操作 | 时间复杂度 | 适用场景 |
|---|---|---|
append() | O(1) | 尾部添加单个元素 |
extend() | O (k)(k 为元素个数) | 批量添加元素 |
insert() | O(n) | 中间插入元素(慎用,效率低) |
remove() | O(n) | 根据值删除(需遍历列表) |
pop()(默认) | O(1) | 删除尾部元素 |
pop(index) | O(n) | 删除中间元素(需移动后续元素) |
del list[index] | O(n) | 删除指定位置元素 |
5.有参装饰器和无参装饰器的区别
在 Python 中,装饰器是一种用于修改函数或类行为的语法糖。根据是否需要参数,装饰器可分为无参装饰器和有参装饰器,二者的实现机制和应用场景存在本质区别。
一、核心区别对比
| 维度 | 无参装饰器 | 有参装饰器 |
|---|---|---|
| 语法形式 | @decorator | @decorator(arg1, arg2) |
| 装饰器本质 | 接收被装饰函数作为唯一参数的函数 | 接收参数并返回一个无参装饰器的函数 |
| 调用逻辑 | 直接返回包装函数 | 先调用装饰器生成无参装饰器,再应用到被装饰函数 |
| 闭包结构 | 单层闭包(装饰器→包装函数) | 双层闭包(装饰器→无参装饰器→包装函数) |
| 典型场景 | 日志记录、性能统计、权限校验等固定行为 | 动态配置装饰器行为(如超时设置、重试次数) |
二、无参装饰器详解
1. 结构与实现
无参装饰器是一个接收函数并返回新函数的函数,通常使用单层闭包实现。
示例:统计函数执行时间
import time
def timer(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs) # 调用原函数
end_time = time.time()
print(f"{func.__name__} 执行耗时: {end_time - start_time} 秒")
return result
return wrapper
@timer
def add(a, b):
time.sleep(1)
return a + b
# 等价于 add = timer(add)
add(3, 5) # 输出: add 执行耗时: 1.001 秒
2. 关键点
- 参数:装饰器函数
timer直接接收被装饰函数add作为参数。 - 返回值:返回包装函数
wrapper,用于替换原函数。 - 调用链:
@timer直接将add传入timer,并执行timer(add)。
三、有参装饰器详解
1. 结构与实现
有参装饰器是一个返回无参装饰器的函数,需要通过双层闭包实现:
- 外层函数接收装饰器参数(如超时时间、重试次数);
- 内层函数(即生成的无参装饰器)接收被装饰函数;
- 最内层函数为包装函数,负责实现具体逻辑。
示例:带超时参数的重试装饰器
import time
def retry(max_retries=3, delay=1):
def decorator(func):
def wrapper(*args, **kwargs):
retries = 0
while retries < max_retries:
try:
return func(*args, **kwargs)
except Exception as e:
retries += 1
print(f"重试 {retries}/{max_retries}, 错误: {e}")
time.sleep(delay)
raise Exception(f"达到最大重试次数 {max_retries}")
return wrapper
return decorator
@retry(max_retries=2, delay=0.5) # 带参数的装饰器
def fetch_data():
import random
if random.random() < 0.7:
raise ValueError("模拟网络错误")
return "数据获取成功"
# 等价于 fetch_data = retry(max_retries=2, delay=0.5)(fetch_data)
fetch_data()
2. 关键点
- 参数传递:
retry(max_retries=2, delay=0.5)先被调用,返回无参装饰器decorator;decorator再接收fetch_data作为参数,返回包装函数wrapper。
- 闭包捕获:
外层函数的参数(如max_retries、delay)被内层wrapper捕获,形成闭包。 - 调用链:
@retry(...) → 执行 retry(...) → 返回 decorator → 执行 decorator(fetch_data) → 返回 wrapper
四、应用场景对比
1. 无参装饰器典型场景
- 固定行为封装:如日志记录、权限校验、缓存等。
def log(func): def wrapper(*args, **kwargs): print(f"调用 {func.__name__},参数: {args}, {kwargs}") return func(*args, **kwargs) return wrapper
2. 有参装饰器典型场景
- 动态配置装饰器行为:
# 示例1:设置函数执行超时时间 @timeout(seconds=5) def long_running_task(): ... # 示例2:根据环境决定是否启用缓存 @cache(enabled=os.environ.get("USE_CACHE") == "true") def get_data(): ...
五、常见误区与注意事项
-
混淆装饰器参数与函数参数
- 有参装饰器的参数在定义时传入(如
@retry(3)),而函数参数在调用时传入(如fetch_data(1, 2))。
- 有参装饰器的参数在定义时传入(如
-
保持元信息
使用functools.wraps保留被装饰函数的元信息(如__name__、__doc__):import functools def timer(func): @functools.wraps(func) # 保留原函数元信息 def wrapper(*args, **kwargs): ... return wrapper -
类实现装饰器
装饰器也可用类实现,无参装饰器需实现__call__方法,有参装饰器需在__init__接收参数并返回__call__:class Retry: def __init__(self, max_retries=3): self.max_retries = max_retries def __call__(self, func): def wrapper(*args, **kwargs): ... return wrapper
六、总结
| 场景 | 选择无参装饰器 | 选择有参装饰器 |
|---|---|---|
| 行为固定,无需外部配置 | ✅ | ❌ |
| 需要动态参数调整装饰器逻辑 | ❌ | ✅ |
| 语法复杂度 | 单层闭包,简单直接 | 双层闭包,结构较复杂 |
理解装饰器的参数传递机制是掌握其高级应用的关键。无参装饰器适用于通用场景,而有参装饰器通过参数化设计提供了更高的灵活性,可根据运行时条件动态调整装饰器行为。
6.python中装饰器和闭包的区别
在 Python 中,** 闭包(Closure)和装饰器(Decorator)** 是两个紧密相关但本质不同的概念。闭包是一种函数式编程的基础结构,而装饰器是闭包的一种高级应用场景。以下从定义、结构、作用和应用场景等方面详细解析两者的区别与联系。
一、核心定义
1. 闭包(Closure)
- 定义:
闭包是指内层函数引用了外层函数的自由变量(非全局变量),且外层函数返回内层函数的引用,使得外层函数结束后,自由变量的作用域仍被内层函数保留的现象。 - 构成条件:
- 嵌套函数(内层函数在外层函数内部定义);
- 内层函数引用外层函数的自由变量;
- 外层函数返回内层函数的引用。
示例:闭包实现计数器
def counter():
count = 0 # 自由变量(属于外层函数的局部变量)
def increment():
nonlocal count # 声明为非局部变量(Python 3+)
count += 1
return count
return increment # 返回内层函数引用
c = counter()
print(c()) # 输出: 1(闭包保留了count的状态)
print(c()) # 输出: 2
2. 装饰器(Decorator)
- 定义:
装饰器是一种用于修改函数或类行为的特殊闭包,它通过包装函数(Wrapper Function)在不修改原函数代码的前提下,为其添加新功能(如日志记录、权限校验、性能统计等)。 - 本质:
装饰器是一个接收函数作为参数,并返回新函数的可调用对象(通常是闭包)。
示例:装饰器实现日志记录
def logger(func):
def wrapper(*args, **kwargs):
print(f"调用函数: {func.__name__},参数: {args}, {kwargs}")
return func(*args, **kwargs) # 调用原函数
return wrapper # 返回包装函数(闭包)
@logger # 等价于 greet = logger(greet)
def greet(name):
return f"Hello, {name}"
greet("Alice") # 输出: 调用函数: greet,参数: ('Alice',), {}
二、结构对比
1. 闭包的结构
def outer_func():
free_var = "闭包变量"
def inner_func():
print(free_var) # 引用外层函数的自由变量
return inner_func # 返回内层函数
- 关键特征:
- 外层函数返回内层函数的引用;
- 内层函数通过闭包机制保留外层函数的自由变量。
2. 装饰器的结构
python
运行
def decorator(func): # 装饰器本身是一个函数,接收被装饰函数作为参数
def wrapper(*args, **kwargs): # 包装函数,闭包的内层函数
# 前置逻辑(如日志、校验)
result = func(*args, **kwargs) # 调用原函数
# 后置逻辑(如结果处理)
return result
return wrapper # 返回包装函数(闭包)
- 关键特征:
- 装饰器是闭包的一种特例,其外层函数的参数是被装饰的函数;
- 包装函数(闭包的内层函数)负责在原函数前后添加额外逻辑。
三、核心区别
| 维度 | 闭包 | 装饰器 |
|---|---|---|
| 本质 | 一种函数作用域机制(保留自由变量) | 闭包的应用模式(修改函数行为) |
| 目的 | 封装变量并保持状态(如计数器) | 无侵入式增强函数功能(如日志、缓存) |
| 参数 | 外层函数可接收任意参数 | 外层函数固定接收被装饰函数作为参数 |
| 语法糖 | 无 | 有(@decorator 语法) |
| 返回值 | 内层函数的引用 | 包装后的新函数 |
| 独立性 | 可独立存在(不一定用于装饰函数) | 依赖于闭包,必须作用于函数或类 |
四、联系:装饰器是闭包的典型应用
装饰器的实现必须依赖闭包机制,原因如下:
- 保留原函数参数:
包装函数通过闭包捕获被装饰函数func,并在调用时传递其参数(*args, **kwargs)。 - 状态保持:
若装饰器需要配置参数(如有参装饰器),这些参数通过闭包的外层函数传递并保留状态。
有参装饰器中的双层闭包示例:
def repeat(num_times=3): # 外层函数:接收装饰器参数(闭包第一层)
def decorator(func): # 中层函数:接收被装饰函数(闭包第二层)
def wrapper(*args, **kwargs): # 内层函数:包装逻辑(闭包第三层)
for _ in range(num_times):
func(*args, **kwargs)
return wrapper
return decorator # 返回中层函数(无参装饰器)
@repeat(num_times=2) # 等价于 greet = repeat(2)(greet)
def greet(name):
print(f"Hello, {name}")
greet("Bob") # 输出: Hello, Bob 两次(num_times通过闭包传递)
- 这里
repeat是外层闭包,捕获参数num_times; decorator是中层闭包,捕获被装饰函数func;wrapper是内层闭包,实现重复调用逻辑。
五、常见误区
-
认为闭包只能用于装饰器
闭包的应用场景更广泛,例如:- 实现状态机(如计数器、缓存);
- 封装私有变量(模拟面向对象的私有属性):
def make_counter(): count = 0 def increment(): nonlocal count count += 1 return count def get_count(): return count return increment, get_count # 返回多个闭包函数
-
混淆装饰器与闭包的语法
- 闭包是函数嵌套和变量作用域的自然结果,无需特殊语法;
- 装饰器必须使用
@语法或函数调用形式(如func = decorator(func))。
六、总结
| 对比项 | 闭包 | 装饰器 |
|---|---|---|
| 是什么 | 函数式编程的基础机制(变量作用域保留) | 闭包的高级应用(函数增强模式) |
| 核心价值 | 封装状态,避免全局变量污染 | 无侵入式扩展函数功能,符合开闭原则 |
| 必要条件 | 嵌套函数 + 引用自由变量 + 返回内层函数 | 必须是闭包,且接收函数作为参数 |
| 典型代码 | def outer(): ... return inner | @decorator def func(): ... |
闭包是装饰器的技术基础,而装饰器是闭包在代码复用和设计模式中的具体实践。理解闭包的原理有助于深入掌握装饰器的工作机制,同时也能在更广泛的场景中发挥函数式编程的优势。
7.return和yield的区别,迭代器和生成器的区别
return 和 yield 的区别
| 特性 | return | yield |
|---|---|---|
| 作用 | 终止函数并返回一个值 | 暂停函数并返回一个值,保留执行状态 |
| 函数类型 | 普通函数 | 生成器函数(返回生成器对象) |
| 执行状态 | 函数状态被销毁 | 函数状态被冻结(局部变量保留) |
| 返回值次数 | 仅返回一次 | 可多次返回值(通过多次 yield) |
| 后续调用 | 函数重新从头执行 | 从上次暂停的位置继续执行 |
| 内存占用 | 一次性返回所有结果 | 惰性计算,节省内存 |
示例对比:
# return 示例
def func_return():
return 1
return 2 # 永远不会执行
print(func_return()) # 输出: 1
# yield 示例
def func_yield():
yield 1
yield 2
gen = func_yield()
print(next(gen)) # 输出: 1
print(next(gen)) # 输出: 2迭代器(Iterator)和生成器(Generator)的区别
| 特性 | 迭代器 (Iterator) | 生成器 (Generator) |
|---|---|---|
| 本质 | 实现了 __iter__ 和 __next__ 方法的对象 | 一种特殊的迭代器(由函数包含 yield 创建) |
| 创建方式 | 手动实现类 或 使用 iter() 转换 | 使用 yield 的函数 或 生成器表达式 (x for x in ...) |
| 复杂度 | 需手动实现协议(代码较冗长) | 自动实现协议(简洁高效) |
| 内存效率 | 可自定义为惰性计算 | 天生惰性计算,一次只产生一个值 |
| 数据来源 | 可遍历任意序列(列表、文件等) | 动态生成数据(无需预存储完整序列) |
| 状态保存 | 需自行管理状态(如索引) | 自动保存执行状态(局部变量、指针位置) |
| 适用场景 | 自定义复杂迭代逻辑 | 快速创建惰性序列、处理大数据流 |
关键关系:
-
生成器是迭代器的子集:所有生成器都是迭代器,但并非所有迭代器都是生成器。
-
生成器简化了迭代器的创建:使用
yield可自动生成__iter__和__next__方法。
示例对比:
# 迭代器示例(手动实现)
class CountDown:
def __init__(self, n):
self.n = n
def __iter__(self):
return self
def __next__(self):
if self.n <= 0:
raise StopIteration
self.n -= 1
return self.n + 1
# 使用迭代器
for num in CountDown(3):
print(num) # 输出: 3, 2, 1
# 生成器示例(更简洁)
def count_down(n):
while n > 0:
yield n
n -= 1
# 使用生成器
for num in count_down(3):
print(num) # 输出: 3, 2, 1
# 生成器表达式
gen = (x for x in range(3, 0, -1))
print(list(gen)) # 输出: [3, 2, 1]核心总结:
-
yieldvsreturn-
yield用于生成器,支持多次返回并保留状态;return一次性结束函数。
-
-
生成器 vs 迭代器
-
生成器是语法糖,简化了迭代器的实现,专注于惰性数据流处理。
-
迭代器是基础协议,适用于需要完全控制迭代逻辑的场景。
-
在 Python 中,99% 的场景优先使用生成器(简洁高效),仅在需要特殊迭代逻辑时才手动实现迭代器。
8.python中的多线程怎样使用
在 Python 中,多线程是实现并发编程的一种方式,适用于 I/O 密集型任务(如网络请求、文件读写)。以下是关于 Python 多线程的详细介绍和使用方法:
一、基础概念
1. 线程 vs 进程
- 进程:程序在操作系统中的一次执行实例,拥有独立的内存空间和系统资源。
- 线程:进程中的一个执行单元,共享进程的内存空间,轻量级且创建 / 销毁成本低。
- Python 多线程限制:受全局解释器锁(GIL)影响,同一时刻只能有一个线程执行 Python 字节码,因此不适用于 CPU 密集型任务(如科学计算)。
2. 适用场景
- I/O 密集型任务:网络爬虫、文件读写、数据库操作等。
- 需要异步执行的任务:如 GUI 程序中的后台任务。
二、线程模块选择
Python 提供了多个线程相关模块:
threading:高级模块,推荐使用,支持线程同步(如锁、信号量)。thread(Python 2)/_thread(Python 3):低级模块,功能有限,不推荐直接使用。concurrent.futures.ThreadPoolExecutor:线程池,适用于批量任务。
三、threading 模块的基本用法
1. 创建线程的两种方式
方式一:直接传入函数
import threading
def print_numbers():
for i in range(5):
print(f"线程1: {i}")
def print_letters():
for letter in ['a', 'b', 'c', 'd', 'e']:
print(f"线程2: {letter}")
# 创建线程对象
t1 = threading.Thread(target=print_numbers)
t2 = threading.Thread(target=print_letters)
# 启动线程
t1.start()
t2.start()
# 等待线程执行完毕
t1.join()
t2.join()
print("主线程结束")
方式二:继承 Thread 类并重写 run 方法
import threading
class PrintNumbers(threading.Thread):
def run(self):
for i in range(5):
print(f"线程1: {i}")
class PrintLetters(threading.Thread):
def run(self):
for letter in ['a', 'b', 'c', 'd', 'e']:
print(f"线程2: {letter}")
# 创建并启动线程
t1 = PrintNumbers()
t2 = PrintLetters()
t1.start()
t2.start()
t1.join()
t2.join()
print("主线程结束")
2. 线程同步机制
当多个线程共享资源时,需使用同步机制避免数据竞争(Race Condition)。
示例:使用 Lock 保护共享资源
import threading
counter = 0
lock = threading.Lock()
def increment():
global counter
for _ in range(100000):
lock.acquire() # 获取锁
try:
counter += 1
finally:
lock.release() # 释放锁(确保异常时也能释放)
# 等价写法(更简洁):
# def increment():
# global counter
# for _ in range(100000):
# with lock: # 自动获取和释放锁
# counter += 1
# 创建并启动多个线程
threads = [threading.Thread(target=increment) for _ in range(3)]
for t in threads:
t.start()
for t in threads:
t.join()
print(f"最终计数: {counter}") # 输出: 300000(若无锁,结果可能错误)
其他同步原语:
RLock:可重入锁,允许同一线程多次获取。Semaphore:信号量,控制同时访问资源的线程数量。Event:事件对象,用于线程间通信(wait()/set())。Condition:条件变量,结合锁和事件,用于复杂同步场景。
四、线程池(ThreadPoolExecutor)
适用于批量任务,避免手动创建和管理大量线程。
示例:使用线程池执行多个任务
import concurrent.futures
def fetch_url(url):
import requests
response = requests.get(url)
return f"{url}: {response.status_code}"
urls = [
"https://www.baidu.com",
"https://www.github.com",
"https://www.python.org"
]
# 创建线程池(最多3个工作线程)
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
# 提交任务并获取结果(方式一:逐个提交)
future_to_url = {executor.submit(fetch_url, url): url for url in urls}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result() # 获取任务结果(可能抛出异常)
except Exception as e:
print(f"{url} 异常: {e}")
else:
print(f"{url} 返回: {data}")
# 等价写法(方式二:使用 map 批量提交)
# results = executor.map(fetch_url, urls)
# for result in results:
# print(result)
五、线程间通信
当需要在线程间传递数据时,可使用 queue.Queue(线程安全的队列)。
示例:生产者 - 消费者模型
import threading
import queue
import time
def producer(q):
for i in range(5):
time.sleep(0.5) # 模拟生产耗时
q.put(i)
print(f"生产者: 放入 {i}")
def consumer(q):
while True:
item = q.get()
if item is None: # 终止信号
break
time.sleep(0.8) # 模拟消费耗时
print(f"消费者: 取出 {item}")
q.task_done() # 通知队列任务完成
# 创建队列
q = queue.Queue()
# 创建并启动线程
t1 = threading.Thread(target=producer, args=(q,))
t2 = threading.Thread(target=consumer, args=(q,))
t1.start()
t2.start()
# 等待生产者完成
t1.join()
# 发送终止信号给消费者
q.put(None)
t2.join()
print("主线程结束")
六、注意事项
-
GIL 限制:
Python 多线程受 GIL 限制,无法真正并行执行 CPU 密集型任务。若需并行计算,建议使用多进程(multiprocessing模块)。 -
线程安全:
避免多个线程直接修改共享可变对象(如列表、字典),必须使用同步机制(如锁)。 -
异常处理:
线程中的异常不会自动传播到主线程,需在任务函数内部捕获并处理异常。 -
线程生命周期:
使用join()确保主线程等待子线程完成,避免资源泄漏。
七、性能对比:多线程 vs 单线程
以下是一个简单的 I/O 密集型任务(模拟网络请求)的性能对比:
import threading
import time
import requests
# 单线程版本
def single_thread():
start = time.time()
for _ in range(10):
requests.get("https://www.baidu.com")
print(f"单线程耗时: {time.time() - start:.2f} 秒")
# 多线程版本
def multi_thread():
start = time.time()
threads = []
for _ in range(10):
t = threading.Thread(target=lambda: requests.get("https://www.baidu.com"))
threads.append(t)
t.start()
for t in threads:
t.join()
print(f"多线程耗时: {time.time() - start:.2f} 秒")
single_thread() # 输出: 单线程耗时: ~5秒(取决于网络)
multi_thread() # 输出: 多线程耗时: ~1秒(并行执行I/O操作)
八、总结
- 何时使用多线程:
I/O 密集型任务,需提高并发处理能力(如爬虫、Web 服务器)。 - 何时避免使用多线程:
CPU 密集型任务(如大数据计算),建议使用多进程。
合理使用多线程能显著提升程序效率,但需注意线程安全和资源管理。对于复杂场景,推荐使用线程池和队列进行任务调度和通信。
9.python中的深浅拷贝在堆栈中的原理
在 Python 中,深浅拷贝是处理对象复制时的重要概念,其实现机制与 Python 的内存管理(堆和栈)密切相关。以下从底层原理、内存模型和实际应用三个维度详细解析:
一、Python 内存基础:栈(Stack)与堆(Heap)
1. 栈内存(Stack)
- 存储内容:
- 局部变量(函数内定义的变量);
- 函数调用帧(记录函数参数、返回地址等)。
- 特点:
- 由操作系统自动分配和释放,速度快;
- 存储的数据大小固定(如整数、引用地址)。
2. 堆内存(Heap)
- 存储内容:
- 所有对象(如列表、字典、自定义类实例);
- 特点:
- 动态分配,需手动管理(通过垃圾回收机制);
- 存储的数据大小可变,结构复杂。
3. 变量与对象的关系
- 变量:存储在栈中,本质是对象的引用(内存地址);
- 对象:存储在堆中,包含实际数据和类型信息。
示例:
a = [1, 2, 3] # 创建列表对象 [1, 2, 3](堆内存),a 指向该对象(栈内存)
b = a # b 复制 a 的引用(栈内存),二者指向同一对象
二、浅拷贝(Shallow Copy)的原理
1. 定义与实现
浅拷贝创建一个新对象,但仅复制对象的一层结构,即:
- 新对象本身是独立的(存储在堆的新地址);
- 但对象的内部元素(如列表的元素、字典的键值对)仍引用原对象的元素。
实现方式:
- 内置函数:
list.copy()、dict.copy()、set.copy(); - 模块函数:
copy.copy(); - 切片操作:
lst[:]。
2. 内存原理
- 栈内存:创建新变量,指向堆中新对象的地址;
- 堆内存:新对象的元素指向原对象元素的地址(共享内部对象)。
示例:
import copy
original = [1, [2, 3]] # 原列表(堆内存)
shallow = copy.copy(original) # 浅拷贝(堆内存创建新列表)
# 修改不可变元素(整数)
shallow[0] = 100 # 仅修改 shallow 的引用,original 不受影响
# 修改可变元素(列表)
shallow[1][0] = 200 # 共享内部列表,original[1][0] 也变为 200
内存示意图:
plaintext
栈内存 堆内存
+--------+ +------------------+
| original|---------> | [1, [2, 3]] |
+--------+ | ↑ ↑ |
| | +---------+
| | |
+--------+ | | |
| shallow|---------> | [100, [200, 3]] |
+--------+ +------------------+
三、深拷贝(Deep Copy)的原理
1. 定义与实现
深拷贝创建一个新对象,并递归复制对象的所有层级结构,即:
- 新对象及其所有嵌套对象均独立分配内存;
- 修改新对象不会影响原对象,反之亦然。
实现方式:
- 模块函数:
copy.deepcopy()。
2. 内存原理
- 栈内存:创建新变量,指向堆中新对象的地址;
- 堆内存:递归复制所有嵌套对象,每个对象均有独立内存。
示例:
import copy
original = [1, [2, 3]] # 原列表(堆内存)
deep = copy.deepcopy(original) # 深拷贝(递归复制所有层级)
# 修改可变元素(列表)
deep[1][0] = 200 # 仅修改 deep 的内部列表,original 不受影响
内存示意图:
栈内存 堆内存
+--------+ +------------------+
| original|---------> | [1, [2, 3]] |
+--------+ +------------------+
| |
+--------+ | |
| deep |---------> | [1, [200, 3]] |
+--------+ +------------------+
四、不可变对象的特殊处理
对于不可变对象(如整数、字符串、元组),深浅拷贝均不创建新对象,而是直接复用原对象的引用。这是因为不可变对象无法修改,复用不会导致数据风险。
示例:
a = (1, 2, [3, 4]) # 元组(不可变)包含列表(可变)
b = copy.copy(a) # 浅拷贝
c = copy.deepcopy(a) # 深拷贝
# 修改元组内的列表
a[2][0] = 300 # 同时影响 a、b、c(元组本身不可变,但内部列表可变)
print(a) # 输出: (1, 2, [300, 4])
print(b) # 输出: (1, 2, [300, 4])(浅拷贝共享内部列表)
print(c) # 输出: (1, 2, [3, 4])(深拷贝递归复制列表)
五、自定义类的深浅拷贝
对于自定义类,可通过实现 __copy__() 和 __deepcopy__() 方法控制拷贝行为。
示例:
import copy
class MyClass:
def __init__(self, value):
self.value = value
def __copy__(self):
# 自定义浅拷贝逻辑
new_obj = self.__class__(self.value) # 创建新实例
return new_obj
def __deepcopy__(self, memo):
# 自定义深拷贝逻辑
# memo 是深拷贝过程中用于避免循环引用的缓存
new_value = copy.deepcopy(self.value, memo)
new_obj = self.__class__(new_value)
memo[id(self)] = new_obj # 记录已复制的对象
return new_obj
六、常见应用场景
-
避免意外修改:
当需要保留原数据时,使用深拷贝创建完全独立的副本。original = [1, [2, 3]] safe_copy = copy.deepcopy(original) -
性能优化:
浅拷贝开销小(仅复制引用),适用于仅需顶层隔离的场景。data = [{'id': 1}, {'id': 2}] shallow = data.copy() # 避免创建新的字典对象 -
循环引用处理:
copy.deepcopy()自动处理循环引用,避免无限递归。a = [] a.append(a) # 循环引用 b = copy.deepcopy(a) # 安全复制,不会无限递归
七、总结对比表
| 维度 | 直接赋值 | 浅拷贝(shallow copy) | 深拷贝(deep copy) |
|---|---|---|---|
| 新对象创建 | 否(仅复制引用) | 是(顶层对象) | 是(所有层级对象) |
| 内部元素引用 | 完全共享 | 共享可变元素,隔离不可变元素 | 完全隔离 |
| 内存占用 | 最低(仅栈内存复制) | 中等(顶层堆内存) | 最高(递归堆内存) |
| 性能开销 | 最小(O (1)) | 较小(O (n),n 为顶层元素数) | 较大(O (m),m 为所有元素数) |
| 适用场景 | 无需隔离数据 | 仅需顶层隔离 | 需要完全隔离数据 |
理解深浅拷贝的内存原理,有助于在实际开发中避免数据意外修改,同时合理优化内存使用。
10.python中内存怎样释放、垃圾回收机制
在 Python 中,内存释放和垃圾回收主要依靠自动的垃圾回收机制(Garbage Collection, GC),但你也可以通过一些方法来手动干预。下面是详细介绍:
一、自动垃圾回收机制
Python 的垃圾回收主要基于以下两种机制:
-
引用计数(Reference Counting)
- 每个对象维护一个引用计数器,记录有多少个变量引用该对象。
- 当引用计数为 0 时,对象立即被回收,内存释放。
- 优点:实时性高,对象一旦不再被引用就会被回收。
- 缺点:无法处理循环引用(两个对象互相引用,导致引用计数永远不为 0)。
-
分代回收(Generational Garbage Collection)
- 针对引用计数无法处理的循环引用问题,Python 引入了分代回收机制。
- 该机制将对象按存活时间分为三代(0、1、2 代),存活时间越长的对象越不可能被回收。
- 当某个代的对象数量达到阈值时,触发垃圾回收,检测并回收循环引用的对象。
二、手动释放内存的方法
虽然 Python 的 GC 会自动回收内存,但在某些情况下(如处理大文件、大数据集时),你可能需要手动释放内存:
-
del 语句
- 删除变量对对象的引用,使对象的引用计数减 1。
- 如果引用计数变为 0,对象会被立即回收。
a = [1, 2, 3] # 创建一个列表对象 del a # 删除变量a,列表对象的引用计数减1 -
gc 模块
- 提供了对垃圾回收机制的高级控制。
- 常用方法:
gc.collect():强制触发一次完整的垃圾回收。gc.disable():禁用自动垃圾回收(不推荐长期使用)。gc.enable():启用自动垃圾回收。
import gc # 创建可能产生循环引用的对象 a = [] b = [] a.append(b) b.append(a) # 删除变量引用 del a, b # 强制触发垃圾回收 gc.collect() -
清空容器对象
- 对于列表、字典等可变容器,使用
clear()方法清空内容,但对象本身仍然存在。
my_list = [1, 2, 3, 4, 5] my_list.clear() # 清空列表,释放列表中的元素占用的内存 - 对于列表、字典等可变容器,使用
三、内存管理的最佳实践
-
避免循环引用
- 尽量避免创建互相引用的对象,或在不再需要时手动断开引用。
-
及时释放大型对象
- 处理完大型数据结构(如大型列表、字典、DataFrame 等)后,及时使用
del删除引用,并调用gc.collect()强制回收。
- 处理完大型数据结构(如大型列表、字典、DataFrame 等)后,及时使用
-
使用生成器(Generator)
- 对于大型数据集,使用生成器代替列表,可以逐个产生值而不是一次性生成所有值,减少内存占用。
# 使用生成器表达式代替列表推导式 gen = (x for x in range(1000000)) # 生成器,占用内存极少 # lst = [x for x in range(1000000)] # 列表,占用大量内存 -
使用上下文管理器
- 对于文件、数据库连接等资源,使用
with语句确保资源在使用后被正确释放。
with open('large_file.txt', 'r') as f: data = f.read() # 文件对象在with块结束后自动关闭,释放资源 - 对于文件、数据库连接等资源,使用
四、调试内存问题
如果你怀疑程序存在内存泄漏,可以使用以下工具进行调试:
memory_profiler:逐行分析函数的内存使用情况。objgraph:可视化对象引用关系,帮助检测循环引用。tracemalloc:跟踪内存分配,找出内存占用最大的对象。
import tracemalloc
tracemalloc.start()
# 执行可能有内存问题的代码
snapshot1 = tracemalloc.take_snapshot()
# 更多代码...
snapshot2 = tracemalloc.take_snapshot()
# 比较两次快照,找出内存增加最多的地方
top_stats = snapshot2.compare_to(snapshot1, 'lineno')
print("[ Top 10 differences ]")
for stat in top_stats[:10]:
print(stat)
通过理解 Python 的垃圾回收机制并遵循内存管理的最佳实践,你可以编写出更高效、更节省内存的 Python 程序。
11.python中怎样读取excel文件,怎样读取几行几列的值
一、安装依赖库
首先要安装pandas以及 Excel 文件解析引擎openpyxl(用于读取.xlsx 文件):
pip install pandas openpyxl
二、读取 Excel 文件
借助pandas.read_excel()函数能够读取整个 Excel 文件:
import pandas as pd
# 读取Excel文件
excel_file = pd.ExcelFile('example.xlsx')
# 获取指定工作表中的数据
df = excel_file.parse('Sheet1')
# 查看数据的基本信息
print('数据基本信息:')
df.info()
# 查看数据集行数和列数
rows, columns = df.shape
三、读取指定行和列的值
1. 按位置索引读取(基于 0 开始的整数索引)
- 读取单行数据:
# 读取第2行(index=1)的所有列 row_2 = df.iloc[1] print('第2行数据信息:') print(row_2) - 读取单列数据:
# 读取第3列(index=2)的所有行 col_3 = df.iloc[:, 2] print('第3列数据信息:') print(col_3) - 读取指定行列交叉处的值:
# 读取第2行第3列的数据 value = df.iloc[1, 2] print('第2行第3列的数据:', value)
2. 按标签索引读取(列名和行索引)
- 读取单行数据:
# 读取索引为'A'的行 row_a = df.loc['A'] print('索引为A的行数据信息:') print(row_a) - 读取单列数据:
# 读取列名为'Column3'的列 col_column3 = df['Column3'] print('列名为Column3的列数据信息:') print(col_column3) - 读取指定行列交叉处的值:
# 读取索引为'A'且列名为'Column3'的数据 value = df.loc['A', 'Column3'] print('索引为A且列名为Column3的数据:', value)
3. 读取多行多列数据
- 读取连续的多行多列:
# 读取第2行到第4行(index=1~3),第3列到第5列(index=2~4)的数据 subset = df.iloc[1:4, 2:5] print('第2行到第4行,第3列到第5列的数据信息:') print(subset) - 读取不连续的多行多列:
# 读取第2行和第5行(index=1和4),第3列和第6列(index=2和5)的数据 subset = df.iloc[[1, 4], [2, 5]] print('第2行和第5行,第3列和第6列的数据信息:') print(subset)
四、处理缺失值
在读取 Excel 数据时,可能会存在缺失值(NaN),可以进行如下处理:
# 检查缺失值
missing_values = df.isnull().sum()
print('缺失值统计:')
print(missing_values)
# 填充缺失值
df_filled = df.fillna(0) # 用0填充缺失值
# 删除包含缺失值的行
df_dropped = df.dropna()
五、完整示例代码
下面是一个完整的示例代码,展示了如何读取 Excel 文件并获取特定行和列的值:
import pandas as pd
# 读取Excel文件
excel_file = pd.ExcelFile('example.xlsx')
# 获取指定工作表中的数据
df = excel_file.parse('Sheet1')
# 查看数据的基本信息
print('数据基本信息:')
df.info()
# 查看数据集行数和列数
rows, columns = df.shape
# 读取第2行(index=1)的所有列
row_2 = df.iloc[1]
print('\n第2行数据信息:')
print(row_2)
# 读取第3列(index=2)的所有行
col_3 = df.iloc[:, 2]
print('\n第3列数据信息:')
print(col_3)
# 读取第2行第3列的数据
value = df.iloc[1, 2]
print('\n第2行第3列的数据:', value)
# 读取连续的多行多列
subset = df.iloc[1:4, 2:5]
print('\n第2行到第4行,第3列到第5列的数据信息:')
print(subset)
# 检查缺失值
missing_values = df.isnull().sum()
print('\n缺失值统计:')
print(missing_values)
六、其他注意事项
- 指定读取范围:若只需读取部分数据,可使用
skiprows和nrows参数:# 从第3行开始加载数据,加载10行数据 df = excel_file.parse('Sheet1', skiprows=2, nrows=10) - 处理表头:若 Excel 文件无表头,可设置
header=None:df = excel_file.parse('Sheet1', header=None) - 读取多个工作表:
# 获取所有表名 sheet_names = excel_file.sheet_names print('所有表名信息:', sheet_names) # 遍历读取所有工作表 for sheet_name in sheet_names: df = excel_file.parse(sheet_name) print(f'\n{sheet_name}表数据基本信息:') df.info()
12.python中集合和列表在查找元素时哪个更快,原因是什么
在 Python 中,集合(set)的查找效率远高于列表(list),尤其是在数据量较大的情况下。以下从底层原理、时间复杂度和实际测试三个维度详细解析:
一、核心结论
| 数据结构 | 查找操作 | 时间复杂度 | 底层实现 | 适用场景 |
|---|---|---|---|---|
| 列表 | x in lst | O(n) | 动态数组(顺序存储) | 有序、可重复、频繁增删改的场景 |
| 集合 | x in s | O (1)(平均) | 哈希表(散列存储) | 去重、快速查找、成员判断的场景 |
二、底层原理对比
1. 列表(list)的查找机制
- 实现方式:
列表是动态数组,元素在内存中按顺序连续存储。 - 查找过程:
当执行x in lst时,Python 会遍历列表中的每个元素,逐一比较是否等于x,直到找到或遍历结束。 - 时间复杂度:
最坏情况下需遍历所有元素,时间复杂度为 O(n)(n 为列表长度)。
示例:
lst = [3, 1, 4, 1, 5, 9]
print(5 in lst) # 需要遍历4个元素(3→1→4→1→5),效率随n增大而降低
2. 集合(set)的查找机制
- 实现方式:
集合是哈希表,元素通过哈希函数映射到数组的特定位置(桶,bucket)。 - 查找过程:
- 计算元素
x的哈希值(hash(x)); - 通过哈希值定位到对应的桶;
- 在桶内(可能是链表或红黑树)检查元素是否存在。
- 计算元素
- 时间复杂度:
理想情况下,哈希冲突极少,时间复杂度为 O(1);
最坏情况下(所有元素哈希冲突),退化为 O (n),但 Python 的哈希表设计会尽量避免这种情况。
示例:
s = {3, 1, 4, 5, 9}
print(5 in s) # 直接通过哈希值定位,无需遍历其他元素
三、关键差异:哈希表 vs 数组
1. 哈希表的优势
- 直接寻址:通过哈希值直接定位元素,无需遍历。
- 去重特性:集合不允许重复元素,插入时会自动去重(基于哈希值和
__eq__方法)。
2. 哈希冲突的处理
当不同元素的哈希值相同时,Python 采用 ** 开放寻址法(Open Addressing)或链表法(Chaining)** 解决冲突:
- 开放寻址法:冲突时寻找下一个空闲位置;
- 链表法:每个桶存储一个链表,冲突元素追加到链表中(Python 3.7+ 使用优化的链表 + 红黑树结构)。
示例:
# 假设两个元素哈希值冲突
s = {obj1, obj2} # 可能存储在同一桶的链表中,但查找时仍比列表快得多
四、性能对比测试
以下代码对比不同数据规模下,列表和集合的查找耗时:
import time
import matplotlib.pyplot as plt
# 测试数据规模
sizes = [10**3, 10**4, 10**5, 10**6]
list_times = []
set_times = []
for size in sizes:
# 生成测试数据
data = list(range(size))
target = size - 1 # 查找最后一个元素(最坏情况)
# 测试列表查找
start = time.time()
target in data
list_times.append(time.time() - start)
# 测试集合查找
s = set(data)
start = time.time()
target in s
set_times.append(time.time() - start)
# 绘制对比图
plt.plot(sizes, list_times, 'o-', label='List')
plt.plot(sizes, set_times, 's-', label='Set')
plt.xscale('log')
plt.yscale('log')
plt.xlabel('Data Size')
plt.ylabel('Lookup Time (seconds)')
plt.title('List vs Set Lookup Performance')
plt.legend()
plt.grid(True)
plt.show()
测试结果(示意图):
- 列表:查找时间随数据规模线性增长(O (n));
- 集合:查找时间几乎恒定(O (1)),即使数据量达到百万级别。
五、适用场景建议
-
优先使用集合:
- 需频繁进行成员判断(如
x in s); - 数据需去重;
- 无需维护元素顺序。
- 需频繁进行成员判断(如
-
使用列表:
- 需保留元素插入顺序;
- 需频繁通过索引访问元素(如
lst[0]); - 数据量较小,或查找操作不是主要瓶颈。
示例:
# 快速去重并查找
data = [1, 2, 2, 3, 3, 3]
unique = set(data) # 去重:{1, 2, 3}
print(2 in unique) # O(1)
# 有序场景
queue = [1, 2, 3]
queue.pop(0) # 列表支持按索引操作(集合不支持)
六、总结
集合的查找效率远高于列表,核心原因在于哈希表的 O (1) 时间复杂度。但列表在有序性和索引访问方面具有不可替代的优势。实际开发中,需根据具体场景权衡选择。
13.python中对列表去重的多种方法
在 Python 中,对列表去重是常见的操作需求。下面为你详细介绍多种列表去重的方法,每种方法都有其适用场景和优缺点。
一、使用 set ()(最简单高效的方法)
原理:利用集合(set)的元素唯一性,直接去除重复元素。
特点:
- 时间复杂度为 O (n),效率高。
- 会自动排序(按元素的哈希值),因此可能改变原列表的顺序。
- 只能处理可哈希的元素(如不可变对象:数字、字符串、元组)。
示例代码:
my_list = [3, 1, 2, 2, 4, 3]
unique_list = list(set(my_list))
print(unique_list) # 输出: [1, 2, 3, 4](顺序可能不同)
处理不可哈希元素(如列表、字典):
如果列表包含不可哈希元素,需先将其转换为可哈希类型(如元组):
python
运行
my_list = [[1, 2], [2, 3], [1, 2]]
unique_list = list(set(tuple(x) for x in my_list))
print(unique_list) # 输出: [(1, 2), (2, 3)]
二、使用循环和条件判断(保留原始顺序)
原理:遍历列表,用新列表存储首次出现的元素。
特点:
- 时间复杂度为 O (n²),效率较低(需逐个检查新列表)。
- 严格保留元素的原始顺序。
- 适用于所有元素类型(无论是否可哈希)。
示例代码:
python
运行
my_list = [3, 1, 2, 2, 4, 3]
unique_list = []
for item in my_list:
if item not in unique_list:
unique_list.append(item)
print(unique_list) # 输出: [3, 1, 2, 4](保留原始顺序)
三、使用字典的 fromkeys () 方法(保留原始顺序,Python 3.7+)
原理:字典的键具有唯一性,且 Python 3.7 + 的字典会保持插入顺序。
特点:
- 时间复杂度为 O (n),效率高。
- 保留元素的原始顺序(Python 3.7+)。
- 只能处理可哈希的元素。
示例代码:
python
运行
my_list = [3, 1, 2, 2, 4, 3]
unique_list = list(dict.fromkeys(my_list))
print(unique_list) # 输出: [3, 1, 2, 4](保留原始顺序)
四、使用列表推导式和条件判断(保留原始顺序)
原理:类似方法二,用列表推导式简化代码。
特点:
- 时间复杂度为 O (n²),效率较低。
- 保留元素的原始顺序。
示例代码:
python
运行
my_list = [3, 1, 2, 2, 4, 3]
unique_list = []
[unique_list.append(item) for item in my_list if item not in unique_list]
print(unique_list) # 输出: [3, 1, 2, 4]
五、使用 OrderedDict(保留原始顺序,Python 3.6-)
原理:collections.OrderedDict在 Python 3.6 - 中能保持插入顺序。
特点:
- 时间复杂度为 O (n),效率高。
- 保留元素的原始顺序(适用于 Python 3.6 及以下版本)。
- 只能处理可哈希的元素。
示例代码:
python
运行
from collections import OrderedDict
my_list = [3, 1, 2, 2, 4, 3]
unique_list = list(OrderedDict.fromkeys(my_list))
print(unique_list) # 输出: [3, 1, 2, 4]
六、自定义哈希函数处理不可哈希元素(高级方法)
原理:将不可哈希元素转换为可哈希的标识(如元组),再用集合去重。
特点:
- 适用于包含复杂对象(如列表、字典)的列表。
- 需自定义哈希函数,灵活性高。
示例代码:
python
运行
my_list = [[1, 2], [2, 3], [1, 2]]
def to_tuple(obj):
if isinstance(obj, list):
return tuple(to_tuple(x) for x in obj)
if isinstance(obj, dict):
return tuple(sorted((k, to_tuple(v)) for k, v in obj.items()))
return obj
unique_list = []
seen = set()
for item in my_list:
hashable = to_tuple(item)
if hashable not in seen:
seen.add(hashable)
unique_list.append(item)
print(unique_list) # 输出: [[1, 2], [2, 3]]
七、性能对比
| 方法 | 时间复杂度 | 保留顺序 | 支持不可哈希元素 |
|---|---|---|---|
| set() | O(n) | ❌ | ❌ |
| 循环 + 条件判断 | O(n²) | ✅ | ✅ |
| dict.fromkeys() | O(n) | ✅ | ❌ |
| OrderedDict | O(n) | ✅ | ❌ |
| 列表推导式 | O(n²) | ✅ | ✅ |
| 自定义哈希函数 | O(n) | ✅ | ✅ |
八、选择建议
- 优先使用 set ():若无需保留顺序,且元素均为可哈希类型。
- 使用 dict.fromkeys ():若需保留顺序,且 Python 版本≥3.7。
- 使用 OrderedDict:若需兼容 Python 3.6 及以下版本。
- 使用循环或自定义哈希函数:若列表包含不可哈希元素(如列表、字典)。
14.测试模块用re和os的示例,正则表达式各个字符的含义
在 Python 中,re(正则表达式)和 os(操作系统接口)是常用的工具模块。下面我将通过一个示例展示它们的用法,并详细解释正则表达式中各个字符的含义。
示例:使用 re 和 os 批量处理文件
假设我们有一个目录,里面包含多种类型的文件,我们需要:
- 找出所有
.txt文件 - 提取文件名中的数字部分
- 统计包含特定关键词的文件数量
import re
import os
# 指定目录路径
directory = "./test_files"
# 任务1: 找出所有 .txt 文件
txt_files = [f for f in os.listdir(directory) if f.endswith('.txt')]
print("找到的 txt 文件:", txt_files)
# 任务2: 提取文件名中的数字部分
for filename in txt_files:
# 使用正则表达式匹配文件名中的数字
match = re.search(r'\d+', filename)
if match:
print(f"{filename} 中的数字: {match.group()}")
else:
print(f"{filename} 中未找到数字")
# 任务3: 统计包含关键词 "error" 的文件数量
keyword = "error"
count = 0
for filename in txt_files:
file_path = os.path.join(directory, filename)
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 使用正则表达式检查是否包含关键词(忽略大小写)
if re.search(rf'\b{keyword}\b', content, re.IGNORECASE):
count += 1
print(f"{filename} 包含关键词 '{keyword}'")
except Exception as e:
print(f"读取文件 {filename} 时出错: {e}")
print(f"共有 {count} 个文件包含关键词 '{keyword}'")
正则表达式字符含义详解
正则表达式通过特殊字符组合定义匹配模式。以下是常用字符及其含义:
1. 普通字符
- 含义:匹配自身(如
a匹配字符a,1匹配数字1) - 示例:
re.search(r'cat', 'catalog')→ 匹配成功(找到cat)
2. 元字符(特殊字符)
| 字符 | 含义 | 示例 |
|---|---|---|
. | 匹配任意单个字符(除换行符 \n) | re.search(r'h.t', 'hat') → 匹配成功(h t 中间任意字符) |
^ | 匹配字符串开头 | re.search(r'^hello', 'hello world') → 匹配成功 |
$ | 匹配字符串结尾 | re.search(r'world$', 'hello world') → 匹配成功 |
* | 匹配前面的字符 0 次或多次 | re.search(r'ab*', 'a') → 匹配成功(b 出现 0 次) |
+ | 匹配前面的字符 1 次或多次 | re.search(r'ab+', 'abbb') → 匹配成功 |
? | 匹配前面的字符 0 次或 1 次 | re.search(r'ab?', 'a') → 匹配成功 |
{m} | 匹配前面的字符 m 次 | re.search(r'a{3}', 'aaab') → 匹配成功 |
{m,n} | 匹配前面的字符 m 到 n 次 | re.search(r'a{2,4}', 'aaa') → 匹配成功 |
[] | 匹配方括号内的任意一个字符 | re.search(r'[aeiou]', 'hello') → 匹配成功(找到 e) |
[^] | 匹配不在方括号内的任意一个字符 | re.search(r'[^0-9]', 'a123') → 匹配成功(找到 a) |
| | 匹配左右任意一个表达式 | re.search(r'cat|dog', 'I have a dog') → 匹配成功 |
() | 分组,将多个字符视为一个整体 | re.search(r'(ab)+', 'ababab') → 匹配成功 |
3. 预定义字符类
| 字符 | 等价于 | 含义 |
|---|---|---|
\d | [0-9] | 匹配数字 |
\D | [^0-9] | 匹配非数字 |
\w | [a-zA-Z0-9_] | 匹配字母、数字、下划线 |
\W | [^a-zA-Z0-9_] | 匹配非字母、数字、下划线 |
\s | [ \t\n\r\f\v] | 匹配空白字符(空格、制表符、换行符等) |
\S | [^ \t\n\r\f\v] | 匹配非空白字符 |
4. 贪婪匹配与非贪婪匹配
-
贪婪匹配:尽可能多的匹配(默认行为)
示例:re.search(r'a.*b', 'aabab')→ 匹配aabab(最长匹配) -
非贪婪匹配:尽可能少的匹配(在量词后加
?)
示例:re.search(r'a.*?b', 'aabab')→ 匹配aab(最短匹配)
5. 常用正则表达式标志
| 标志 | 含义 | 示例 |
|---|---|---|
re.IGNORECASE | 忽略大小写 | re.search(r'cat', 'CAT', re.IGNORECASE) → 匹配成功 |
re.DOTALL | 使 . 匹配包括换行符在内的所有字符 | re.search(r'a.b', 'a\nb', re.DOTALL) → 匹配成功 |
re.MULTILINE | 多行模式,^ 和 $ 匹配每行的开头和结尾 | re.findall(r'^hello', 'hello\nhello', re.MULTILINE) → 匹配 2 次 |
正则表达式实战技巧
-
转义特殊字符:
若需匹配元字符本身(如.、*),需用\转义
示例:re.search(r'\.', 'a.b')→ 匹配. -
分组提取信息:
使用()分组后,可通过match.group(n)提取分组内容
示例:match = re.search(r'(\d{4})-(\d{2})-(\d{2})', '2023-05-15') print(match.group(1)) # 输出: 2023 print(match.group(2)) # 输出: 05 -
边界匹配:
\b匹配单词边界(单词与非单词字符的交界处)
示例:re.search(r'\bcat\b', 'a cat')→ 匹配成功(完整单词)
总结
正则表达式是强大的文本处理工具,核心在于:
- 字符匹配:普通字符、元字符、预定义字符类
- 数量控制:
*、+、?、{m,n} - 位置匹配:
^、$、\b - 分组与标志:
()、re.IGNORECASE等
15.搭建测试环境的流程
搭建测试环境是软件开发过程中的关键环节,其目的是模拟生产环境,确保软件在发布前能稳定运行。下面为你详细介绍搭建测试环境的通用流程:
一、需求分析与规划
1. 明确测试目标
- 功能测试:验证软件是否实现了需求文档中的所有功能。
- 性能测试:测试软件在高并发、大数据量下的响应速度和稳定性。
- 兼容性测试:确保软件在不同浏览器、操作系统、设备上正常运行。
2. 确定环境配置
- 硬件资源:服务器 CPU、内存、磁盘空间等。
- 软件环境:操作系统版本、数据库类型及版本、中间件(如 Web 服务器)。
- 网络配置:网络带宽、防火墙规则、域名解析。
3. 制定环境清单
- 列出所有需要的软件、工具及其版本。
- 明确依赖关系(如数据库驱动、第三方库)。
二、环境搭建
1. 基础环境准备
- 物理机 / 虚拟机:根据需求选择硬件配置,安装操作系统。
- 云服务:使用 AWS、阿里云等云平台创建 EC2 实例或容器。
2. 软件安装与配置
- 操作系统:安装必要的补丁和更新。
- 数据库:安装并配置 MySQL、PostgreSQL 等,导入测试数据。
- 应用服务:部署 Web 服务器(如 Nginx、Apache)、应用程序。
- 中间件:消息队列(RabbitMQ)、缓存(Redis)等。
3. 环境隔离与安全
- 容器化:使用 Docker 创建独立的测试环境。
- 虚拟化:利用 VMware 或 KVM 创建虚拟测试机。
- 安全策略:配置防火墙、用户权限,确保数据安全。
三、测试数据准备
1. 数据设计
- 设计测试数据集,覆盖正常、异常、边界场景。
- 例如:用户注册测试需包含合法邮箱、重复邮箱、非法格式邮箱。
2. 数据生成
- 手动创建:小规模测试数据。
- 脚本生成:使用 Python 脚本批量生成测试数据。
- 数据导入:从生产环境脱敏后的数据中提取部分作为测试数据。
3. 数据管理
- 建立数据备份机制,防止测试过程中数据丢失。
- 使用版本控制工具管理测试数据脚本。
四、测试工具集成
1. 自动化测试工具
- UI 自动化:Selenium、Appium。
- 接口测试:Postman、JMeter、Apifox。
- 单元测试:JUnit(Java)、pytest(Python)。
2. 性能测试工具
- JMeter:压力测试、负载测试。
- Gatling:高并发场景下的性能测试。
3. 监控工具
- Prometheus + Grafana:监控服务器性能指标。
- ELK Stack(Elasticsearch + Logstash + Kibana):日志收集与分析。
五、环境验证与调试
1. 功能验证
- 执行冒烟测试,确保环境基本功能正常。
- 例如:Web 应用能否正常访问,数据库连接是否成功。
2. 性能验证
- 测试环境能否满足性能指标(如响应时间、吞吐量)。
- 若不满足,调整硬件配置或优化软件参数。
3. 问题排查
- 环境搭建常见问题:
- 依赖冲突:不同软件对同一库的版本要求不一致。
- 网络问题:防火墙阻止访问、端口未开放。
- 配置错误:数据库连接字符串错误、环境变量未设置。
六、环境维护与优化
1. 版本控制
- 使用 Git 管理测试环境的配置文件和脚本。
- 确保环境配置与代码版本一致。
2. 定期维护
- 清理测试数据,避免磁盘空间不足。
- 更新软件补丁,修复安全漏洞。
3. 持续集成 / 持续部署(CI/CD)
- 集成 Jenkins、GitLab CI 等工具,实现环境自动搭建和测试。
- 每次代码提交后自动触发测试流程。
七、文档记录
1. 环境配置文档
- 记录服务器 IP、账号密码、软件版本等信息。
- 示例:
plaintext
服务器IP:192.168.1.100 操作系统:CentOS 7.9 MySQL版本:8.0.26 配置文件路径:/etc/mysql/my.cnf
2. 测试数据说明
- 描述测试数据的结构和用途。
- 例如:
test_users.csv包含 1000 条用户数据,用于注册和登录测试。
3. 常见问题与解决方案
- 整理环境搭建和测试过程中遇到的问题及解决方法。
- 例如:Q:应用启动失败,提示 "数据库连接超时";A:检查防火墙是否开放 3306 端口。
八、示例:Python Web 应用测试环境搭建流程
搭建测试环境是软件开发过程中的关键环节,其目的是模拟生产环境,确保软件在发布前能稳定运行。下面为你详细介绍搭建测试环境的通用流程:
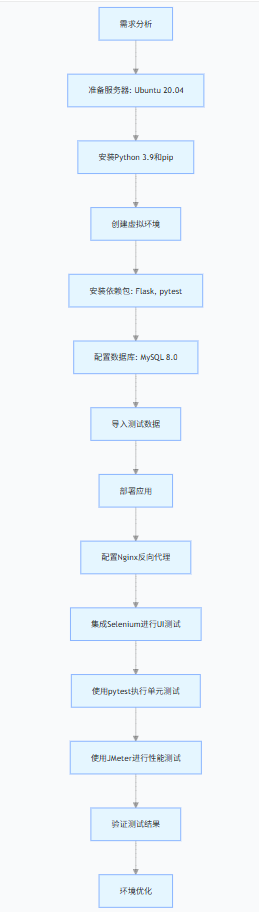
16.自动化测试中,怎样测试app/浏览器的兼容性
在自动化测试中,测试 App 或浏览器的兼容性是确保应用在不同环境下正常运行的关键环节。以下从测试策略、工具选择到执行流程的完整指南:
一、兼容性测试的核心目标
确保应用在以下环境中保持功能一致性和用户体验:
- 浏览器:Chrome、Firefox、Safari、Edge 等(不同版本)。
- 移动设备:iOS/Android 不同系统版本、屏幕分辨率、设备型号。
- 特殊环境:黑暗模式、高对比度、低带宽网络等。
二、兼容性测试策略
1. 确定测试范围
- 基于用户分布:根据实际用户量,优先测试占比高的设备 / 浏览器(如 Chrome 80%、Safari 15%)。
- 覆盖主流版本:测试最新 2-3 个稳定版本(如 iOS 16/17、Chrome 110/111)。
- 特殊场景:如大屏手机(iPhone 14 Plus)、折叠屏(Galaxy Z Fold)。
2. 分层测试方法
- 静态分析:检查代码中是否使用特定浏览器 / 系统的 API(如 WebKit 前缀)。
- 自动化功能测试:在主流环境中执行核心流程(登录、支付、数据提交)。
- 视觉验证:使用截图对比工具检测布局错乱、元素缺失。
- 性能测试:在低端设备或弱网环境下测试响应速度。
三、自动化测试工具链
1. 浏览器兼容性测试
-
Selenium WebDriver:
跨浏览器自动化测试,支持 Chrome、Firefox、Safari 等。from selenium import webdriver from selenium.webdriver.chrome.options import Options # 配置 Chrome 浏览器 chrome_options = Options() chrome_options.add_argument("--headless") # 无头模式 driver = webdriver.Chrome(options=chrome_options) # 配置 Firefox 浏览器 firefox_options = webdriver.FirefoxOptions() driver = webdriver.Firefox(options=firefox_options) -
BrowserStack/Sauce Labs:
云测试平台,提供真实浏览器环境(如 macOS Safari、Windows Edge)。# BrowserStack 示例配置 desired_caps = { 'browserName': 'Chrome', 'browserVersion': '110.0', 'os': 'Windows', 'os_version': '10', }
2. App 兼容性测试
-
Appium:
跨平台移动应用自动化,支持 iOS 和 Android。from appium import webdriver # iOS 应用配置 desired_caps = { 'platformName': 'iOS', 'platformVersion': '16.4', 'deviceName': 'iPhone 14', 'app': '/path/to/app.ipa', } driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps) -
Firebase Test Lab:
云平台,支持在真实设备上运行自动化测试(需上传 APK/IPA)。
3. 视觉验证工具
-
Percy:
自动对比页面截图,标记视觉差异(如按钮位置偏移)。# 安装 Percy CLI npm install -g @percy/cli # 运行视觉测试 percy exec -- cypress run -
BackstopJS:
基于 Puppeteer 的视觉回归测试工具,支持自定义容差范围。
4. 网络环境模拟
- Chrome DevTools Protocol:
在 Selenium 中模拟弱网环境(如 3G、高延迟)。# 模拟 3G 网络 driver.execute_cdp_cmd('Network.emulateNetworkConditions', { 'offline': False, 'downloadThroughput': 750 * 1024 / 8, # 750 kb/s 'uploadThroughput': 250 * 1024 / 8, # 250 kb/s 'latency': 100 # 100 ms })
四、测试执行流程
1. 环境准备
- 本地环境:在开发机安装主流浏览器 / 模拟器(如 Android Studio、Xcode)。
- 云端环境:配置 BrowserStack/Sauce Labs 账号,关联测试框架。
2. 测试用例设计
- 核心功能覆盖:登录、数据展示、表单提交、文件上传等。
- 特殊场景:
- 浏览器缩放(100%/150%/200%)。
- 设备旋转(横屏 / 竖屏)。
- 黑暗模式切换。
3. 执行与报告
- 并行执行:使用测试框架(如 pytest-xdist)在多环境同时测试。
- 结果聚合:收集各环境的测试报告,标记兼容性问题。
- 可视化展示:使用 Allure 或自定义仪表盘展示各浏览器 / 设备的通过率。
五、常见兼容性问题及解决方案
| 问题类型 | 示例 | 解决方案 |
|---|---|---|
| CSS 渲染差异 | 按钮位置偏移、字体大小不一致 | 使用 CSS Reset,避免硬编码尺寸,优先使用相对单位(rem/em)。 |
| JavaScript 兼容性 | fetch 在旧版浏览器报错 | 使用 Babel 转译 ES6+ 代码,添加 polyfill(如 core-js)。 |
| 浏览器特有 API | WebKit 前缀属性(如 -webkit-scrollbar) | 使用 Feature Detection 或跨浏览器兼容库(如 Modernizr)。 |
| 移动设备性能 | 低端 Android 设备加载缓慢 | 优化图片资源(使用 WebP),减少 DOM 操作,实现懒加载。 |
| 输入法问题 | 中文输入法导致输入框位置异常 | 在移动设备测试中加入真实输入场景,避免使用 sendKeys 直接填充值。 |
六、持续集成(CI)集成
将兼容性测试纳入 CI/CD 流程,确保每次代码变更都经过多环境验证:
yaml
# GitHub Actions 示例配置
jobs:
compatibility-test:
runs-on: ubuntu-latest
strategy:
matrix:
browser: [chrome, firefox, safari]
os: [windows-latest, macos-latest]
steps:
- uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
- name: Install dependencies
run: npm install
- name: Run tests on ${{ matrix.browser }} ${{ matrix.os }}
uses: browserstack/github-actions/setup-env@master
with:
username: ${{ secrets.BROWSERSTACK_USERNAME }}
access-key: ${{ secrets.BROWSERSTACK_ACCESS_KEY }}
- run: npm test -- --browser=${{ matrix.browser }}
七、测试报告与优先级划分
1. 报告维度
- 功能通过率:各环境下功能测试的成功率。
- 视觉差异率:截图对比的差异数量及严重程度。
- 性能指标:加载时间、交互响应时间在不同设备的表现。
2. 问题优先级
- P1(阻断级):核心功能无法使用(如登录失败)。
- P2(严重):部分功能异常(如图表显示错误)。
- P3(一般):视觉瑕疵(如按钮边框缺失)。
- P4(建议):非关键体验问题(如动画卡顿)。
八、工具推荐
- 自动化框架:Selenium(Web)、Appium(移动)、Playwright(全平台)。
- 云测试平台:BrowserStack、Sauce Labs、Firebase Test Lab。
- 视觉测试:Percy、BackstopJS、Applitools。
- 性能监控:Lighthouse、WebPageTest。
17.jmeter中常用的函数有哪些
一、变量与参数化函数
1. ${__V()} - 变量取值函数
- 作用:动态获取变量的值,常用于变量名本身也是变量的场景。
- 示例:
${__V(myVar_${index})} # 获取名为myVar_1、myVar_2等变量的值
2. ${__P()} - 属性取值函数
- 作用:获取 JMeter 属性的值(通过
-J命令行参数或user.properties设置)。 - 示例:
${__P(server.host,localhost)} # 获取属性server.host的值,默认值为localhost
3. ${__property()} - 与__P()类似,但支持更多参数
- 示例:
${__property(server.port,8080,)} # 获取属性值并支持更新
二、随机数生成函数
1. ${__Random()} - 生成随机整数
- 作用:生成指定范围内的随机整数。
- 示例:
${__Random(1,100,randomNum)} # 生成1-100之间的随机数,存入变量randomNum
2. ${__RandomString()} - 生成随机字符串
- 作用:生成指定长度的随机字符串。
- 示例:
${__RandomString(10,abcdefghijklmnopqrstuvwxyz,randomStr)} # 生成10位随机小写字母
3. ${__UUID()} - 生成唯一标识符
- 作用:生成通用唯一识别码(UUID)。
- 示例:
${__UUID()} # 生成类似550e8400-e29b-41d4-a716-446655440000的UUID
三、时间与日期函数
1. ${__time()} - 获取当前时间戳
- 作用:获取当前时间的时间戳(毫秒)。
- 示例:
${__time(,currentTime)} # 获取当前时间戳,存入变量currentTime ${__time(yyyy-MM-dd HH:mm:ss,formattedTime)} # 格式化为指定日期时间格式
2. ${__dateTimeConvert()} - 时间格式转换
- 作用:将时间戳或日期字符串转换为其他格式。
- 示例:
${__dateTimeConvert(2023-01-01 12:00:00,yyyy-MM-dd HH:mm:ss,dd/MM/yyyy,)} # 转换为01/01/2023
四、字符串处理函数
1. ${__strSub()} - 字符串截取
- 作用:截取字符串的指定部分。
- 示例:
${__strSub(hello world,6,5,subStr)} # 从第6位开始截取5个字符,存入subStr(结果:world)
2. ${__regexFunction()} - 正则表达式处理
- 作用:使用正则表达式提取或替换字符串。
- 示例:
${__regexFunction(hello world,(\w+)\s(\w+),$2 $1,)} # 交换单词顺序(结果:world hello)
3. ${__unescapeHtml()} - HTML 转义处理
- 作用:将 HTML 转义字符还原为原始字符。
- 示例:
${__unescapeHtml(<h1>Hello</h1>,)} # 转换为<h1>Hello</h1>
五、文件与数据处理函数
1. ${__FileToString()} - 读取文件内容
- 作用:读取文件内容并存储到变量中。
- 示例:
${__FileToString(/path/to/file.txt,,fileContent)} # 读取文件内容到fileContent变量
2. ${__CSVRead()} - 读取 CSV 文件
- 作用:从 CSV 文件中读取数据(常用于参数化)。
- 示例:
${__CSVRead(data.csv,0)} # 读取data.csv文件的第1行第1列数据
六、数学计算函数
1. ${__intSum()} - 整数求和
- 作用:对多个整数进行求和。
- 示例:
${__intSum(10,20,result)} # 计算10+20,结果存入result变量
2. ${__counter()} - 计数器
- 作用:生成递增的计数器值。
- 示例:
${__counter(,counterVar)} # 每次调用递增1,初始值为1
七、调试与日志函数
1. ${__log()}, ${__logn()} - 日志输出
- 作用:将信息输出到 JMeter 日志文件。
- 示例:
${__log(This is a debug message,)} # 输出普通日志 ${__logn(This is a debug message with newline,)} # 输出带换行的日志
2. ${__debug()}, ${__debugVar()} - 调试变量
- 作用:在调试过程中查看变量值。
- 示例:
${__debugVar(myVar,)} # 在结果树中显示myVar变量的值


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









