







图片下载
首先是下载素材图片
# coding:utf-8
import requests
def downloads_pic(path,name):
url = "http://www.xxx/"
pic = requests.get(url, stream=True)
# save file
with open(path + name + '.png', 'wb') as _stream :
for chunk in pic.iter_content(1024):
if chunk:
_stream.write(chunk)
_stream.flush()
_stream.close()
pass
# 执行下载
for i in range(20):
file_name = "%03d" % (i+1)
downloads_pic('./hundr/', file_name)
pass下载好图片后如下图
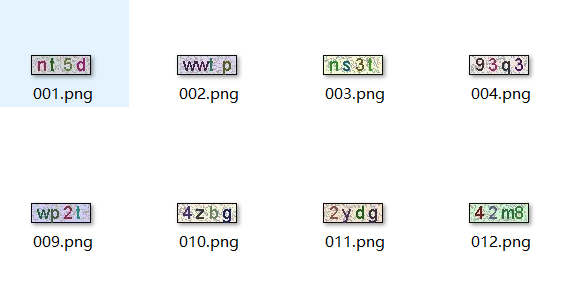
观察图片
如下图所示,每个字符的颜色是固定的,位置也是固定的(多张图对比)
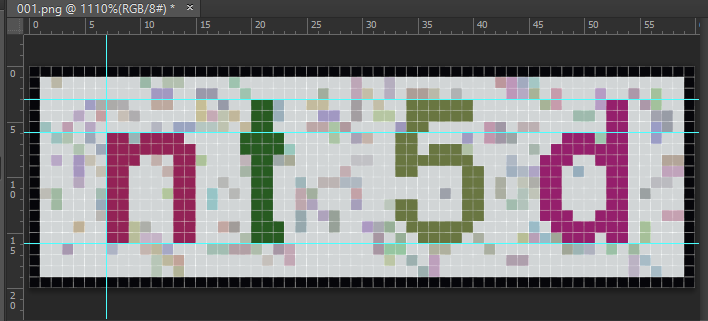
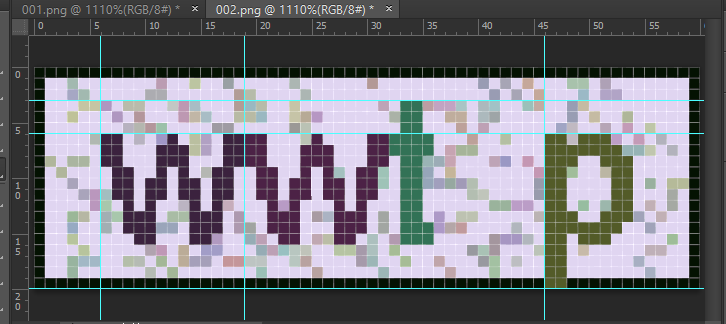
其中字符’w’可以得出一个字符占的宽度,’p’可以得出高度
从图片中可以分析出该验证码图片的生成原理:
- 固定4个区域(6,3,19,20),之后宽度13一个一个取
- 同时每个字符生成的颜色也是固定的,没有渐变
- 可以简单的推断图片先是生成背景,然后随机产生干扰点,再在图片上绘画字体,生成标量的图片,所以没有颜色的渐变,处理起来更加简单
那么思路就很清楚了
- 通过位置分割4块小的区域得到子图片
- 每个子图片查找到字体的颜色进行二值化
查找字体颜色可以通过计算颜色直方图找出占比最大的颜色,又由于背景色的存在,所以需要先统计全张图片的颜色得到背景色,然后在子图片中剔除掉背景颜色即可得到
处理图片
先将图片分割成4块小的图片,然后通过直方图二值化图片,最后转换成字符串特征(因为处理的结果是精确结果,所以不需要分类,本文这里粗处理一下)
# coding:utf-8
# python:2.7.x
from PIL import Image
from collections import defaultdict
import os
import os.path
def get_histogram(img):
# 统计最多出现次数
dicts = defaultdict(int)
pixels = img.load()
for x in range(img.width):
for y in range(img.height):
col = pixels[x,y]
dicts[col] += 1
# 排序
return sorted(dicts.iteritems(), key=lambda d: d[1], reverse=True)
pass
def thresholding(img, _threshold):
# 指定阈值二值化
_str = ""
pixels = img.load()
for x in range(img.width):
for y in range(img.height):
_str += "1" if(pixels[x, y] == _threshold) else "0"
# just for view it.
pixels[x, y] = (255, 0, 0, 0) if(pixels[x, y] == _threshold) else (255, 255, 255, 0)
# 255-前景为红色,0-背景黑色,这里修改了,下面一处必须修改
return _str
pass
def handle_image(filename, out_im_list=None):
# 处理图像: 分割并二值化,返回4个特征码的list
# 读取文件
im = Image.open(filename)
# 统计全局背景
bk_col, tmp = get_histogram(im)[0]
# 切成4块
im_list = []
for i in range(4):
box = (6 + i * 13, 3, 19 + i * 13, 20)
im_list.append(im.crop(box))
# 统计4块区域直方图二值化
cc_str = []
for i in range(4):
_hist = get_histogram(im_list[i])
# 去掉背景
k, v = _hist[0]
if k == bk_col:
_hist.remove((k, v))
threshold, v = _hist[0]
# 简单保存到字符串里
cc_str.append(thresholding(im_list[i], threshold))
# im_list[i].save("%s_%d.png" % i)
if out_im_list is not None:
out_im_list.append(im_list[i])
return cc_str
pass特征码识别
处理一张图片得到4个特征码,每个特征码对应了一个字符,那么哪个特征码对应哪个字符呢?对于该问题,肯定不能一个一个取对应(虽然只有26个字符+10个数字字符),这里我想了一个简单的实现方式处理该问题:
- 绑定特征码到二值化后的子图像
- 通过处理N个样本,得到全部已存在的特征码,合成全部特征码对应的子图像
- 通过肉眼观察合成的图片,人去识别里面的字符(仅需几秒),得到一个字符串
- 程序通过该字符串可以一一对应到特征码关系,读取图片然后比较特征码得出验证码
- *这步不是必须的,按照a-z0-9顺序重新排列图片然后合成图片生成特征码图片作为参考
在这个过程中,程序是可以知道每张图片对应了哪4个特征码,但是这些特征码程序并不知道意味着什么,所以需要人去翻译特征码与验证码(a-z0-9)的关系,然后程序就可以准确的返回对应的验证码
合成图片
def merge_cc(path):
# 自动合成指定目录里的特征码为一副图片
# 手动识别修改配置文件里的 file->
cc_str_list = []
im = Image.new("RGBA", (13 * 6, 17 * 6))
for parent, dirname, filename in os.walk(path):
for f_name in filename:
# 仅遍历path
im_list = []
# 获取特征码 此处简易实现
cc_str = handle_image(os.path.join(parent, f_name), im_list)
# 去掉重复的然后贴到图片上
for i in range(4):
if cc_str[i] in cc_str_list:
continue
# print cc_str[i] # 输出特征码
cc_str_list.append(cc_str[i])
# 合成图片
index = len(cc_str_list) + 5
x, y = (index % 6, int(index / 6) - 1)
im.paste(im_list[i], (x * 13, y * 17))
im.save(os.path.join(parent, "merge.png"))
pass重建验证-特征码图片
def reduce_cc(filename, cc_str):
# 根据提供的字符串重新排列图片得到标准图片
# 切割图片
im = Image.open(filename)
save_im = Image.new("RGBA", (13 * 6, 17 * 6))
im_list = []
for j in range(6):
for i in range(6):
im_list.append(im.crop((13 * i, 17 * j, 13 * (i + 1), 17 * (j + 1))))
# 通过字符串重新排序
codes = list(cc_code)
idx = 0
for s in cc_str:
index = codes.index(s) + 6
x, y = (index % 6, int(index / 6) - 1)
save_im.paste(im_list[idx], (x * 13, y * 17))
idx += 1
# 保存文件
save_im.save("reduce.png")
pass调用方式
# 分析验证码并合并
# merge_cc("2027")
# 重新排序图片,使图片与文字产生联系(一一对应)
# reduce_cc("merge.png", "nt5dwps39qy8hmax7fge24zbkr6c")
# reduce_cc("merge.png", "64xyd59febnk3pc27hszmaqwtg8r")加载特征码-验证码图片
def load_cc_tab(out_cc_tab):
# 通过标准图片得到对应的验证码表
im = Image.open("cc.png")
for j in range(6):
for i in range(6):
_im = im.crop((13 * i, 17 * j, 13 * (i + 1), 17 * (j + 1)))
# 获取cc码
out_cc_tab.append(thresholding(_im, (255, 0, 0, 255)))
pass读取文件并进行识别
def recognise_from_file(filename, cc_tab):
# 读取图片文件识别验证码
# cc_tab -- 识别表
# 返回IM句柄用于输出未识别验证码(人工优化)
im_list = []
rc_code = [] # 返回验证码
cc_str = handle_image(filename, im_list)
for i in range(4):
if cc_str[i] in cc_tab:
index = cc_tab.index(cc_str[i])
rc_code.append(cc_code[index])
else:
# 输出图片到err目录
im_list[i].save("./err/%s.png" %
''.join(random.sample('abcdefghijklmnopqrstuvwxyz', 5)))
print "have one cannot recognised."
return rc_code
pass简单的测试
def test(path):
# 简单测试: 将指定目录所有文件进行识别并修改文件名为验证码
cc_tab = []
load_cc_tab(cc_tab)
for parent, dirname, filename in os.walk(path):
for f_name in filename:
rc = recognise_from_file(
os.path.join(parent, f_name), cc_tab)
str_filename = ''.join(rc) + '_'\
+ ''.join(random.sample('abcdefghijklmnopqrstuvwxyz', 2))\
+ '_.png'
os.rename(
os.path.join(parent, f_name),
os.path.join(parent, str_filename)
)
print ''.join(rc)
pass结果
合成特征码图片结果如下:
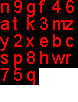
重新排序特征码图片:

测试的识别结果

相关资源下载
一些说明
- 图片合成是按照6*6设置的,因为26个字母加上10个数字正好36
- 图片转换特征码粗暴的将二值化(0,255)转换为01字串,很粗暴,也意味着简单
- 可以将特征码(13*17)压缩为28字节,然后再hash映射到一个字节(能表达36个)
- 本文的验证码识别不具有通用性,只是特定的图片特定的处理,仅仅提供思路,因为讲道理所有的图片验证码都是程序生成的,都是有迹可循的
- 由于是精确的图片处理,所以本文没用到常规的图片处理,以及分类器。
- 本文仅供研究使用,严禁用于他途

















 6282
6282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









