







上一篇说完IF结构,这一篇就接着总结分支结构中的switch,对于switch结构,编译器共有四种方案提供选择,我们不必去关心编译器何时会选择何种结构,因为这个完全取决于编译器作者,所以我们只需能识别出这四种方案是switch结构即可。
对于switch结构而言,不管哪种方案,其主要分两部分
引导代码
case块集合对于不同的方案,其case块集合是不变的,主要在于其引导方式的变化。
首先,来看方案一,这是最基础的情况,在vs系列中,其触发的条件是case在三个以内(由编译器决定)。
int main(int argc, char* argv[])
{
switch(argc)
{
case 1:
printf("case 1");
break;
case 2:
printf("case 2");
break;
default:
printf("default"); //注意此时没有break,表示default执行完继续执行
case 3:
printf("case 3");
break;
}
return 0;
}首先,先来看一下上面的代码,其实对于switch而言,其与if结构最大的一个不同是当case块中没有break时,需要顺序执行,那么这意味着switch的结构并不会同if结构一样。
对应的汇编代码
9: switch(argc)
10: {
//引导部分
0040D718 8B 45 08 mov eax,dword ptr [ebp+8]
0040D71B 89 45 FC mov dword ptr [ebp-4],eax
0040D71E 83 7D FC 01 cmp dword ptr [ebp-4],1
0040D722 74 0E je main+32h (0040d732)
0040D724 83 7D FC 02 cmp dword ptr [ebp-4],2
0040D728 74 17 je main+41h (0040d741)
0040D72A 83 7D FC 03 cmp dword ptr [ebp-4],3
0040D72E 74 2D je main+5Dh (0040d75d)
0040D730 EB 1E jmp main+50h (0040d750) //上面都没比较成功则跳转到default
//case块集合部分
11: case 1:
12: printf("case 1");
0040D732 68 24 20 42 00 push offset string "case 1" (00422024)
0040D737 E8 34 39 FF FF call printf (00401070)
0040D73C 83 C4 04 add esp,4
13: break;
0040D73F EB 29 jmp main+6Ah (0040d76a) //break 执行完跳转到switch结束
14: case 2:
15: printf("case 2");
0040D741 68 BC 2F 42 00 push offset string "argc == 0" (00422fbc)
0040D746 E8 25 39 FF FF call printf (00401070)
0040D74B 83 C4 04 add esp,4
16: break;
0040D74E EB 1A jmp main+6Ah (0040d76a)
17: default:
18: printf("default"); //注意此时没有break,表示default执行完继续执行
0040D750 68 2C 20 42 00 push offset string "argc == 1" (0042202c)
0040D755 E8 16 39 FF FF call printf (00401070)
0040D75A 83 C4 04 add esp,4 //此处没有jmp,说明default执行完会顺序执行下面case 3
19: case 3:
20: printf("case 3");
0040D75D 68 1C 20 42 00 push offset string "else else" (0042201c)
0040D762 E8 09 39 FF FF call printf (00401070)
0040D767 83 C4 04 add esp,4
21: break;
22: }
23: return 0;
0040D76A 33 C0 xor eax,eax在上面的汇编代码中,引导部分主要就是用于比较case值,当匹配到对应的值时,跳转到对应的case块中,因为case块中有break存在,此时就会产生jmp的语句(执行完跳转到switch结束),如果没有jmp,说明该case块没有break,此时会接着顺序执行,也就是因为这个特点,需要把所有的case块都集中在一起,否则无法做到没有无break时顺序执行。
对于switch的边界问题其实还是比较好识别的,因为这个特点比较明显,主要的是如何识别switch结束位置,这里switch结束的位置可以在case块中找,因为如果有break,那么其jmp的位置一般就是switch结束位置了。
在有些代码中,可能没有default,那么上面在引导部分都不符合条件时,就会直接jmp到switch结束的位置。
明白了switch的机制后,也就可以明白这种方案,其实在时间上来说,与if语句其实并没有显著的优点,毕竟这里再引导部分也是用if一个个进行比较的。
下面再来看方案二,方案二使用的是地址表引导的方案。对于之前的引导部分,其可以细分为三个部分,并不是简简单单的使用jxx进行比较。
引导部分
表达式求值
范围检查
查表并转移下面来观察下面这段的反汇编进行观察
int main(int argc, char* argv[])
{
switch(argc)
{
case 19:
printf("case 10");
break;
case 12:
printf("case 1");
break;
default:
printf("default");
break;
case 13:
printf("case 3");
break;
case 17:
printf("case 3");
break;
case 20:
printf("case 3");
break;
case 16:
printf("case 3");
break;
}
return 0;
}对应的反汇编代码
9: switch(argc)
10: {
//表达式求值部分
0040D718 8B 45 08 mov eax,dword ptr [ebp+8]
0040D71B 89 45 FC mov dword ptr [ebp-4],eax
0040D71E 8B 4D FC mov ecx,dword ptr [ebp-4]
0040D721 83 E9 0C sub ecx,0Ch
0040D724 89 4D FC mov dword ptr [ebp-4],ecx
//范围检查
0040D727 83 7D FC 08 cmp dword ptr [ebp-4],8
0040D72B 77 28 ja $L858+0Fh (0040d755)
//查表并转移
0040D72D 8B 55 FC mov edx,dword ptr [ebp-4]
0040D730 FF 24 95 B1 D7 40 00 jmp dword ptr [edx*4+40D7B1h]
11: case 19:
12: printf("case 10");
0040D737 68 24 20 42 00 push offset string "case 10" (00422024)
0040D73C E8 2F 39 FF FF call printf (00401070)
0040D741 83 C4 04 add esp,4
13: break;
0040D744 EB 58 jmp $L866+0Dh (0040d79e)
14: case 12:
15: printf("case 1");
0040D746 68 BC 2F 42 00 push offset string "case 2" (00422fbc)
0040D74B E8 20 39 FF FF call printf (00401070)
0040D750 83 C4 04 add esp,4
16: break;
0040D753 EB 49 jmp $L866+0Dh (0040d79e)
17: default:
18: printf("default");
0040D755 68 2C 20 42 00 push offset string "argc == 1" (0042202c)
0040D75A E8 11 39 FF FF call printf (00401070)
0040D75F 83 C4 04 add esp,4
19: break;
0040D762 EB 3A jmp $L866+0Dh (0040d79e)
//.....此处省略部分代码
29: case 16:
30: printf("case 3");
0040D791 68 1C 20 42 00 push offset string "else else" (0042201c)
0040D796 E8 D5 38 FF FF call printf (00401070)
0040D79B 83 C4 04 add esp,4
31: break;
32: }
33: return 0;
0040D79E 33 C0 xor eax,eax
归根结底这个机制其实就是查表机制,表中其实存着对应的case的地址,那么通过其索引就能跳转到对应的位置,下面我们对引导的三个部分细细来讨论一下
表达式求值,对于这部分而言,我们可以知道该case的最小值。拿上面那段程序来说,我们的case的最小值为12,那么对于数组而言,其下标的最小值肯定是0,那么对于数组的0~11项是不是就浪费了呢,所以这里使用了坐标平移的办法,也就是说最小值case 12对应其下标0。
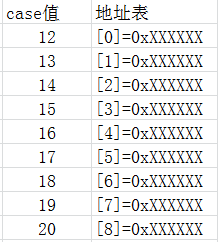
好了,明白了上面的对应关系后,如何得出case的最小值
0040D721 83 E9 0C sub ecx,0Ch在这行汇编代码中,我们发现其case值减去了一个值,其实这个值就是最小值,也就是0xC(十进制12)。
下面再来看范围检查这一部分,对于范围检查,因为可知其case的最大值,因为对于范围检查而言肯定是对地址越界检查,那么将地址表的最大项加上我们上面得出的case最小值就是case最大值。
0040D727 83 7D FC 08 cmp dword ptr [ebp-4],8
0040D72B 77 28 ja $L858+0Fh (0040d755)
//这里使用的是无符号比较,所以当其值为负数也会不符合条件(很大的正数)而跳转通过这里的汇编代码,我们可以得知其case的最大值为12 + 8 = 20。
好了,最后就是到了查表并跳转的部分了。这里的话我们主要解决一个问题,那就是当case值不存在时,数组表中填什么呢?如case 14就不存在,那么对于上图中的下标为三填写什么呢,这里我们需要看一下内存,补充一下上表即可得出结论


通过实践可以得出其地址表中空缺的地址会填写default的地址,如果没有default呢?那么其实就会填写switch end处的地址,这样子的就通过查表就可以满足当case值不存在时执行default了。
OK,下面该来说方案三了,对于方案三而言,其实算是对于上面的优化,对于引导部分,其多了一个步骤
引导部分
表达式求值
界限检查
查索引部分-此步骤相比方案二是多出来的
查表并转移下面先来说说方案二的问题,通过上面的分析,我们可以知道在地址表中,对于不存在的case项会填写default的地址,那么假设在一组序列中,其不存在的case很多这么办?如下面的代码
int main(int argc, char* argv[])
{
switch(argc)
{
case 23:
printf("hello1");
break;
case 89:
printf("hello2");
break;
case 47:
printf("hello3");
break;
case 72:
printf("hello2");
break;
case 22:
printf("hello3");
break;
case 56:
printf("hello4");
break;
}
return 0;
}我们来简单计算一下空间成本
数组项数* 4 = (89-23 + 1)*4 = 67 * 4 = 268有什么办法可以节省一下空间么,那么此时需要多一张索引表即可解决问题,其索引表每一项占一字节,用于记录地址表的索引位置,相当于之前的直接查地址表,现在需要先查找索引表得到索引,然后在根据索引表查地址,算是一个以时间换空间的方案吧。
 大概的思想就和左边的表一样,这里左边的地址表与上面代码中的不符,因为正常情况,一般是case值有多少项,其地址表就会有多少项,注意default地址也会在里面(只有一份)。这样子很明显因为索引值只占一字节,所以其总大小肯定比上面小的。
大概的思想就和左边的表一样,这里左边的地址表与上面代码中的不符,因为正常情况,一般是case值有多少项,其地址表就会有多少项,注意default地址也会在里面(只有一份)。这样子很明显因为索引值只占一字节,所以其总大小肯定比上面小的。
下面再来看一下反汇编代码
9: switch(argc)
10: {
//表达式求值
0040D718 8B 45 08 mov eax,dword ptr [ebp+8]
0040D71B 89 45 FC mov dword ptr [ebp-4],eax
0040D71E 8B 4D FC mov ecx,dword ptr [ebp-4]
0040D721 83 E9 16 sub ecx,16h //这里可以得出case最小值为22
//界限检查
0040D724 89 4D FC mov dword ptr [ebp-4],ecx
0040D727 83 7D FC 43 cmp dword ptr [ebp-4],43h //case最大值 22 + 0x43=89
0040D72B 77 6A ja $L864+0Dh (0040d797)
//查索引部分
0040D72D 8B 45 FC mov eax,dword ptr [ebp-4]
0040D730 33 D2 xor edx,edx
0040D732 8A 90 C6 D7 40 00 mov dl,byte ptr (0040d7c6)[eax] //在索引表取值,注意这里是一字节
//查表并转移
0040D738 FF 24 95 AA D7 40 00 jmp dword ptr [edx*4+40D7AAh] //根据索引表值在到地址表中获取地址跳转
11: case 23:
12: printf("hello1");
0040D73F 68 24 20 42 00 push offset string "case 10" (00422024)
0040D744 E8 27 39 FF FF call printf (00401070)
0040D749 83 C4 04 add esp,4
13: break;
0040D74C EB 49 jmp $L864+0Dh (0040d797)
14: case 89:
15: printf("hello2");
0040D74E 68 BC 2F 42 00 push offset string "argc == 0" (00422fbc)
0040D753 E8 18 39 FF FF call printf (00401070)
0040D758 83 C4 04 add esp,4
16: break;
0040D75B EB 3A jmp $L864+0Dh (0040d797)
//.....这里省略部分代码
26: case 56:
27: printf("hello4");
0040D78A 68 1C 20 42 00 push offset string "case 3" (0042201c)
0040D78F E8 DC 38 FF FF call printf (00401070)
0040D794 83 C4 04 add esp,4
28: break;
29: }
30: return 0;
0040D797 33 C0 xor eax,eax其原理就是中间使用了一字节的索引表进行间接查询地址,好了上面说了索引表的每一项都只占一字节,然而对于索引表还有一个就是最多只能存储256项,因此索引表只能存储256项索引编号,那么问题来了,当case最小值和case最大值的间隔大于255时,那么索引表就无法进行索引了。
所以,针对上面的问题,方案四就来了,方案四使用的是二叉平衡树加混合的方案。至于如何混,下面我们先来看一下例子
int main(int argc, char* argv[])
{
switch (argc)
{
case 3:
printf("hello 3");
break;
case 58:
printf("hello 7");
break;
case 153:
printf("hello 3");
break;
case 250:
printf("hello 5");
break;
case 256:
printf("hello 3");
break;
case 300:
printf("hello 5");
break;
case 317:
printf("hello 3");
break;
default:
printf("default");
break;
}
return 0;
}在这个例子中,很明显其case最小和最大的差值已经255,所以此时使用平衡树的方案,下面我们对上面的数值来构建一颗平衡树

对于二叉平衡树而言,其查找速度也会快很多了,其查找规则就是如果比根节点的值小,那么往左边找,大的话就往右边找。我们下面来看一下反汇编代码是否是这样呢?
0040D718 8B 45 08 mov eax,dword ptr [ebp+8]
0040D71B 89 45 FC mov dword ptr [ebp-4],eax
0040D71E 81 7D FC FA 00 00 00 cmp dword ptr [ebp-4],0FAh //250
0040D725 7F 23 jg main+4Ah (0040d74a) //大于走右边
0040D727 81 7D FC FA 00 00 00 cmp dword ptr [ebp-4],0FAh
0040D72E 74 64 je main+94h (0040d794) //根节点值
//下面是左子树部分
0040D730 83 7D FC 03 cmp dword ptr [ebp-4],3 //3
0040D734 74 31 je main+67h (0040d767)
0040D736 83 7D FC 3A cmp dword ptr [ebp-4],3Ah //58
0040D73A 74 3A je main+76h (0040d776)
0040D73C 81 7D FC 99 00 00 00 cmp dword ptr [ebp-4],99h //158
0040D743 74 40 je main+85h (0040d785)
0040D745 E9 86 00 00 00 jmp main+0D0h (0040d7d0) //都不符合到default
//下面是右子树部分
0040D74A 81 7D FC 00 01 00 00 cmp dword ptr [ebp-4],100h //256
0040D751 74 50 je main+0A3h (0040d7a3)
0040D753 81 7D FC 2C 01 00 00 cmp dword ptr [ebp-4],12Ch //300
0040D75A 74 56 je main+0B2h (0040d7b2)
0040D75C 81 7D FC 3D 01 00 00 cmp dword ptr [ebp-4],13Dh //317
0040D763 74 5C je main+0C1h (0040d7c1)
0040D765 EB 69 jmp main+0D0h (0040d7d0) //都不符合到default看完上面的汇编代码,其实可以发现第一次是对了,查找的是根节点,大于则跳转到右子树,等于说明找到了,剩下的就左子树情况,对于左右子树而言,可以发现其是顺序查找的,按照我们上面的平衡二叉树,应该也是要先查找中值呀?
其实对于方案四来说,先是使用平衡二叉树的方案,使用完二叉树方案,可以发现其左右子树的节点并未超过三个,符合方案一(由编译器决定),所以左右子树使用的是方案一。
 此时如果再增加一个多个值,那么其可能又会由方案一转变为方案或者方案三。
此时如果再增加一个多个值,那么其可能又会由方案一转变为方案或者方案三。
至于如何选择方案就是编译器做的事,我们只需知道不管case情况如何复杂,其最终肯定在这四种方案间混合。对于方案四而言,在还原时候不用去关心jg或者gl,因为对于二叉树查找而言,要么比较大于,然后比较等于,剩下的情况肯定就是小于了,所以在比较时我们只需把重心放在je或者jne上,因为此时cmp的值可能就是对应的case值。















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









