






1散点图
1.代码
A:未处理异常值
import ggplot as gp
import pandas as pd
import numpy as np
crime=pd.read_csv("crimeRatesByState2005.csv")
#去除异常值
#geom_point()折线散点图
#stat_smooth(color)添加趋势线
#ggplot(data, aes(x, y)) ,给参数data里传入数据,x里传入横坐标数据,y里传入纵坐标数据,即可画出一个空白框图
print(gp.ggplot(gp.aes(x='murder',y='burglary'),data=crime)+gp.geom_point(color='red'))B:
import ggplot as gp
import pandas as pd
import numpy as np
crime=pd.read_csv("crimeRatesByState2005.csv")
#去除异常值
crime2=crime[crime.state!='United States']
crime2=crime2[crime2.state!='District of Columbia']
#geom_point()折线散点图
#stat_smooth(color)添加趋势线
#ggplot(data, aes(x, y)) ,给参数data里传入数据,x里传入横坐标数据,y里传入纵坐标数据,即可画出一个空白框图
print(gp.ggplot(gp.aes(x='murder',y='burglary'),data=crime2)+gp.geom_point()+gp.stat_smooth(method='loess',color='red'))
2.分析
(1)ggplot(data, aes(x, y)) ,给参数data里传入数据,x里传入横坐标数据,y里传入纵坐标数据,即可画出一个空白框图
(2)geom_point(),散点图;geom_line(),折线图
geom_point() + geom_line(),折线散点图
(3)stat_smooth(color),添加趋势线
(4)AttributeError: module 'pandas' has no attribute 'tslib'
找到ggplot包中的utils.py模块,把pd.tslib.Timestamp 改为pd.Timestamp
>>>在ggplot包中stats目录下找到smoothers.py模块,把 from pandas.lib import Timestamp 改为 from pandas import Timestamp,把 pd.tslib.Timestamp 改为 pd.Timestamp。
>>>smoothed_data = smoothed_data.sort ('x')改为smoothed_data =smoothed_data.sort_values('x')
3.结果
A:
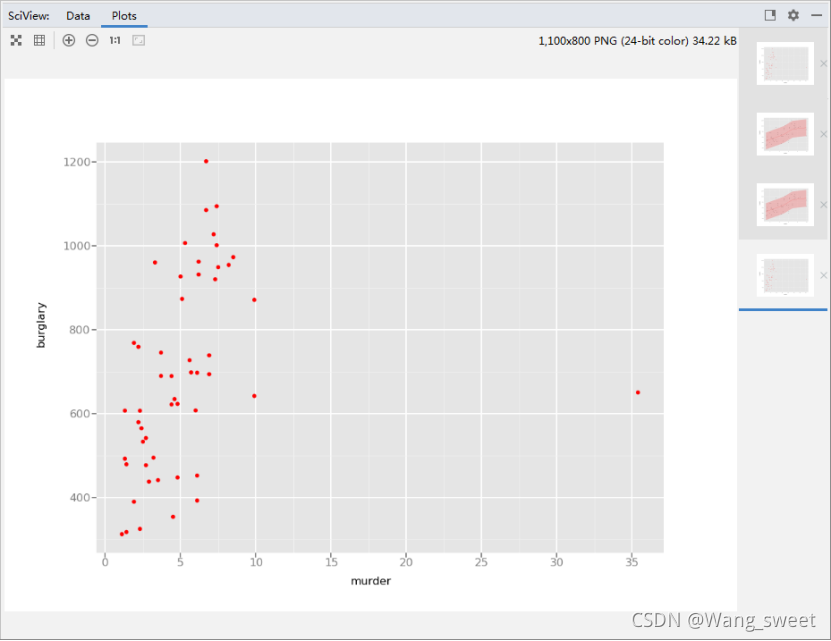
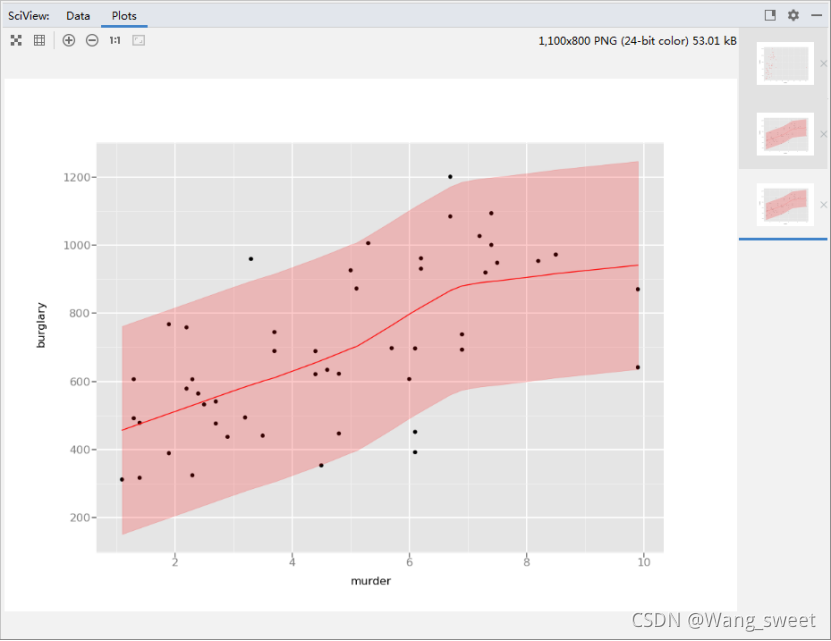
B:
2散点图距阵
1.代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
crime=pd.read_csv("crimeRatesByState2005.csv")
crime2=crime[crime.state!="United States"]
crime2=crime2[crime2.state!="District of Columbia"]
g=sns.pairplot(crime2,diag_kind="kde")
plt.show()
#可通过设置diag_kind参数设置对角图像,’kde‘设置为密度图 'hist'设置为直方图
2.分析
3.结果
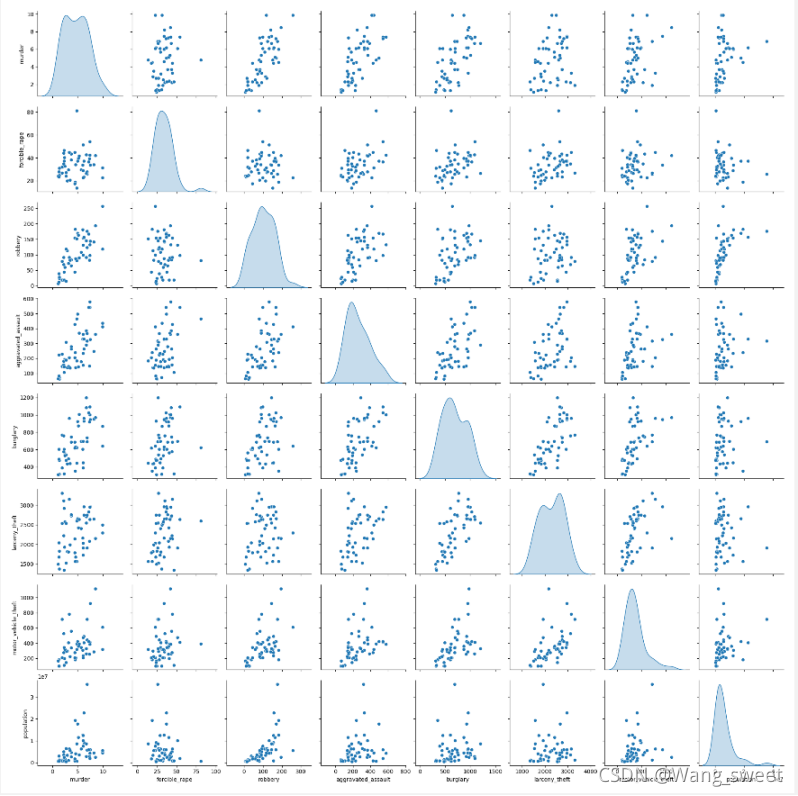
3气泡图
1.代码
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
crime=pd.read_csv("crimeRatesByState2005.csv")
print(list(crime.murder))
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']#处理乱码问题
crime2=crime[crime.state!="United States"]#去除异常值
crime2=crime2[crime2.state!="District of Columbia"]
#对”人口“数据处理
z=list(crime2.population/10000)
colors=np.random.rand(len(list(crime2.murder)))
cm=plt.cm.get_cmap('RdYlBu')
#s:指定散点图点的大小,默认为20,通过传入其他数值型变量,可以实现气泡图的绘制。
#c:指定散点图点的颜色,默认为蓝色,也可以传递其他数值型变量,通过cmap参数的色阶表示数值大小。
#alpha:设置散点的透明度。inewidths:设置散点边界线的宽度
cm=plt.scatter(list(crime2.murder), list(crime2.burglary),s=z,c=z,cmap = cm,linewidth=0.5,alpha=0.5)
plt.xlabel("谋杀案")#x轴标签
plt.ylabel("入室盗窃")#y轴标签
plt.title('入室盗窃与谋杀相关性的气泡图')
plt.show()2.分析
(1)在设置标题时,可以处理乱码问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
(2)气泡图的创建使用函数:scatter(x, y, s=20, c=None, cmap=None, alpha=None, linewidths=None)
#s:指定散点图点的大小,默认为20,通过传入其他数值型变量,可以实现气泡图的绘制。
#c:指定散点图点的颜色,默认为蓝色,也可以传递其他数值型变量,通过cmap参数的色阶表示数值大小。
#alpha:设置散点的透明度。inewidths:设置散点边界线的宽度
(3)plt.xlabel("mueder") #x轴标签
plt.ylabel("burglary") #y轴标签
plt.title('入室盗窃与谋杀相关性的气泡图') #设置标签
3.结果
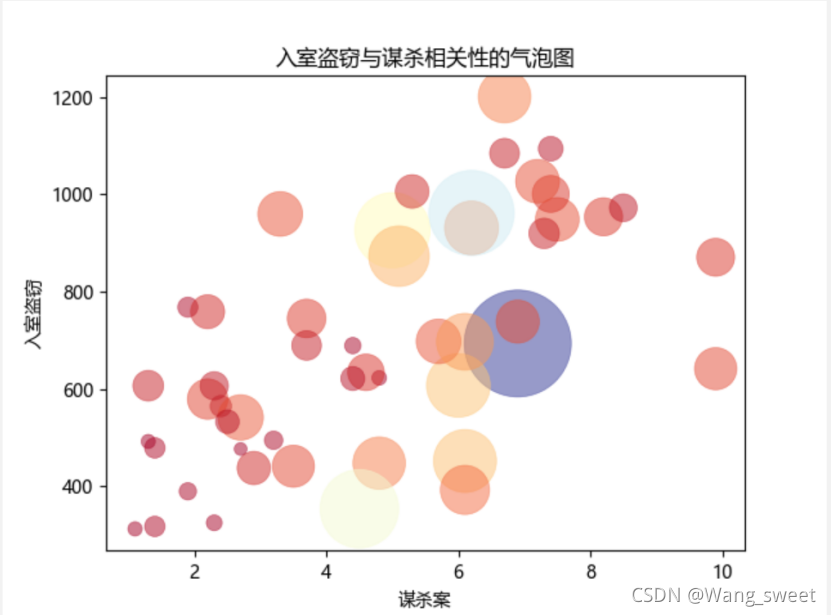
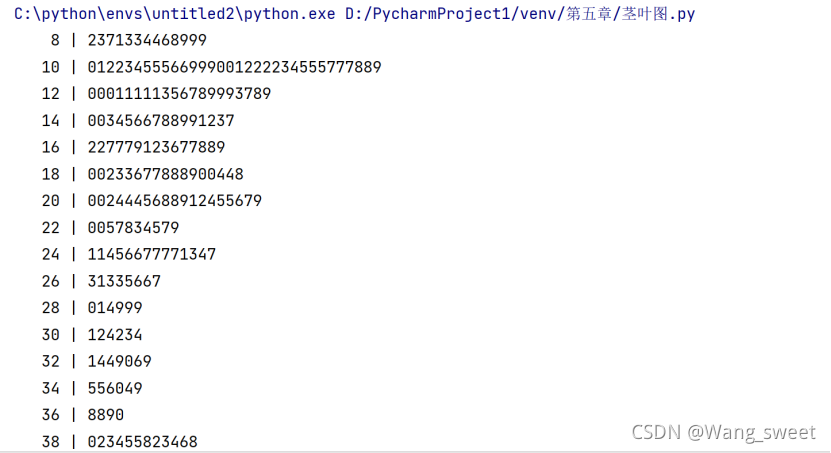
4茎叶图
1.代码
import numpy as np
import math
from itertools import groupby
import pandas as pd
birth=pd.read_csv("birth-rate.csv")
birth.dropna(subset=['2008'],inplace=True)
dirt={} #字典
data=list(round(birth['2008'],1))
rangenum=[] #列表
#k 和 h 分别为每个数值的十位数字和个位数字的字符形式
for k,g in groupby(sorted(data),key=lambda x:int(x)):
lst=map(str,list(map(lambda y:divmod(int(y*10),10)[1],list(g))))
dirt[k]=''.join(lst)
rangenum.append(k)
num=list(range(rangenum[0],rangenum[-1],2))
for i in num:
a=''
for k in sorted(dirt.keys()):
if 0<=k-i<=1:
a=a+''+dirt[k]
elif k-i>1:
break
print(str(i).rjust(5),'|',a)2.分析
3.结果
5直方图
1.代码
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']#设置字体
plt.rcParams['axes.unicode_minus']=False #字符显示
titanic=pd.read_csv("birth-rate.csv")
#dropna(subset=None,inplace=False)处理缺失值
# subset array-like选定列 potional所有列
# inplace True在原表上进行修改 False不在原表上进行修改
titanic.dropna(subset=['2008'],inplace=True)#处理缺失值,删除含有缺失2008中的值
plt.style.use('ggplot')
#bins:指定直方图条形的个数 edgecolor:设置直方图边框色
# label:设置直方图的标签,可通过legend展示其图例
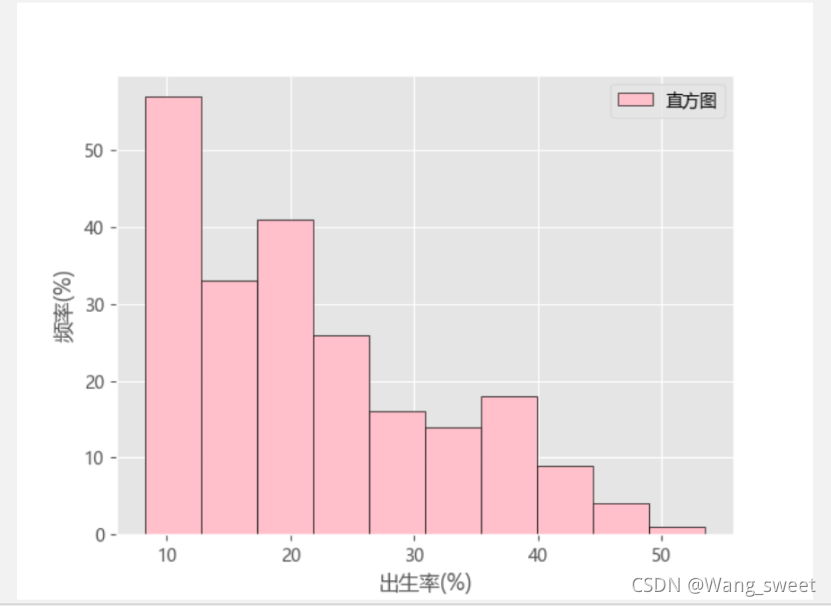
plt.hist(titanic['2008'],bins=10,color='pink',edgecolor='k',label='直方图')
#参数 top, left, bottom,right的值为布尔值,分别代表设置绘图区四个边框线上的的刻度线是否显示
plt.tick_params(top=False,right=False)#去除右边和顶部边界的刻度
plt.legend()
plt.xlabel("出生率(%)")
plt.ylabel("频率(%)")
plt.show()
2.分析
(1)titanic.dropna(subset=['2008'],inplace=True)
#dropna(subset=None,inplace=False)处理缺失值,删除含有缺失2008中的值
DataFrame.dropna(axis=0,how='any',thresh=None,subset=None,inplace=False)
# 0表示对包含缺失值的行进行删除 1表示对包含缺失值的列进行删除
# how any表示有任何NA存在就删除所在行或列 all表示该行或列必须都是NA才删除
# thresh int整数数据类型 optional随意数据类型
# subset array-like选定列 potional所有列
# inplace True在原表上进行修改 False不在原表上进行修改
(2)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']#设置字体
plt.rcParams['axes.unicode_minus']=False #字符显示
(3)绘制直方图
#bins:指定直方图条形的个数 edgecolor:设置直方图边框色
# label:设置直方图的标签,可通过legend展示其图例
plt.hist(titanic['2008'],bins=10,color='pink',edgecolor='k',label='直方图')
(4)plt.tick_params(top=True,right=True)
#参数 top, left, bottom,right的值为布尔值,分别代表设置绘图区四个边框线上的的刻度线是否显示
3.结果
6密度图
1.代码
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']#设置字体
plt.rcParams['axes.unicode_minus']=False #字符显示
titanic=pd.read_csv("birth-rate.csv")
titanic.dropna(subset=['2008'],inplace=True)
#处理缺失值,删除含有缺失2008中的值
kde=mlab.GaussianKDE(titanic['2008'])
x2 = np.linspace(titanic['2008'].min(),titanic['2008'].max(),1000)
line2 = plt.plot(x2,kde(x2),'g-',linewidth = 2)
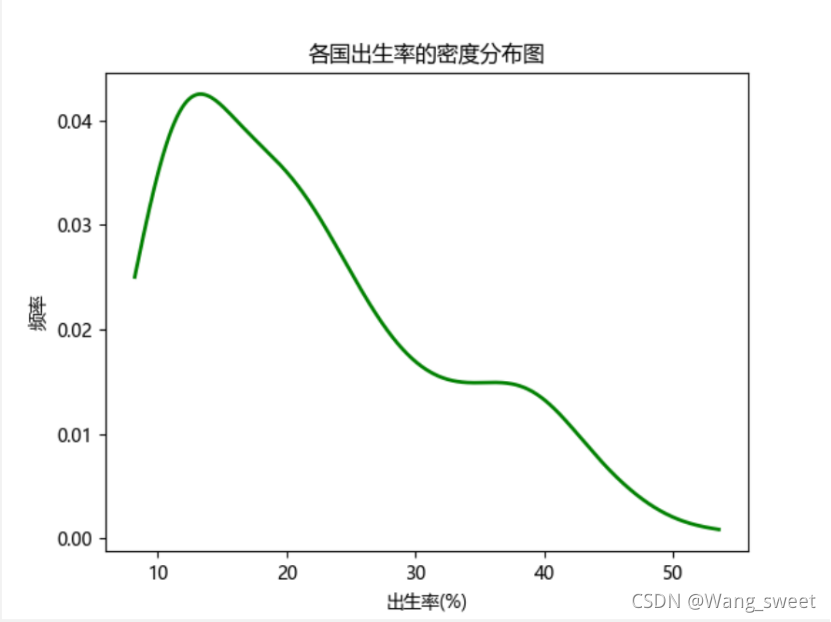
plt.xlabel("出生率(%)")
plt.ylabel("频率")
plt.title('各国出生率的密度分布图')
plt.show()
2.分析
3.结果
7密度图与直方图结合
1.代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
#设置字体 显示字符 读取数据 删除’2008‘数据中的缺失值 使用ggplot绘图方式
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
titanic = pd.read_csv('birth-rate.csv')
titanic.dropna(subset=['2008'],inplace=True)
plt.style.use('ggplot')
#直方图
plt.hist(titanic['2008'],bins=np.arange(titanic['2008'].min(),titanic['2008'].max(),3),density=True,color='steelblue',edgecolor='k')
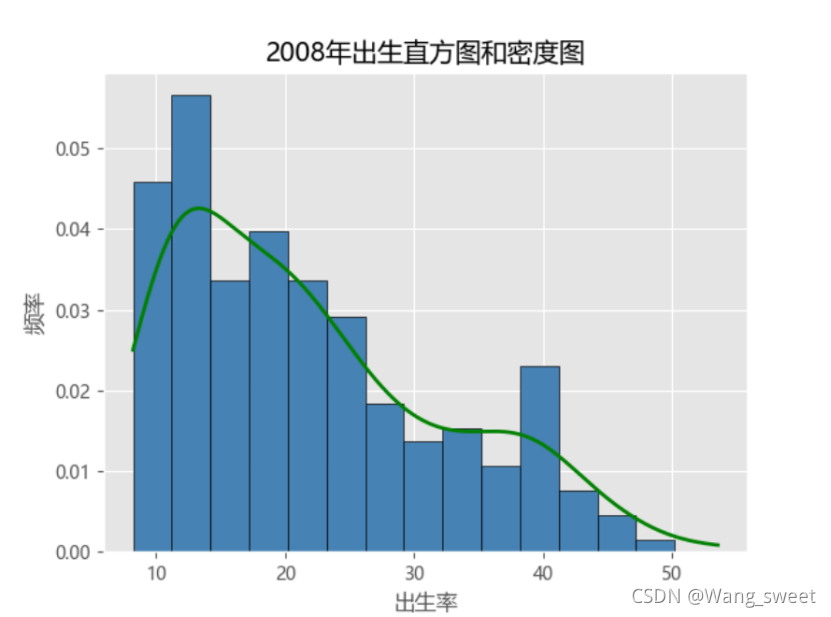
plt.title('2008年出生直方图和密度图')
plt.xlabel('出生率')
plt.ylabel('频率')
plt.tick_params(top=False,right=False)
#密度图
kde = mlab.GaussianKDE(titanic['2008'])
x2 = np.linspace(titanic['2008'].min(),titanic['2008'].max(),1000)
line2 = plt.plot(x2,kde(x2),'g-',linewidth = 2)
plt.show()
2.分析
3.结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









