







Scrapyd
Scrapyd是一个用于部署scrapy项目和通过HTTP API控制爬虫的服务软件。
- 官方文档:http://scrapyd.readthedocs.org/
- Github项目地址: https://github.com/scrapy/scrapyd
Scrapy使用教程
- 安装pip install scrapyd
- 运行scrapyd命令,访问127.0.0.1:6800可看到可视化界面
Scrapy工作原理
- 服务器端(scrapyd): 运行客户端部署的爬虫。
- 客户端(scrapyd-client):将本地的scrapy项目打包发送到scrapyd 这个服务端
安装 scrapyd-client: pip install scrapyd-client
部署Scrapy项目使用教程
- scrapy项目配置scrapy.cfg文件
其中的username 和 password 用于在部署时验证服务器的HTTP basic authentication,须要注意的是这里的用户密码并不表示访问该项目须要验证,而是登录服务器用的。
[settings]
default = ScrapyProject.settings
# demo用来标识项目, 可任意命名, 不指定时。标识名默认是default
[deploy:demo]
# 部署爬虫到目标服务器(url)
url = http://localhost:6800/
project = ScrapyProject
username = admin
#访问服务器所需的用户名和密码(如果不需要密码可以不写)
password = westos123
- scrapyd-deploy部署项目
# 将本地爬虫项目部署到远程服务器端
scrapyd-deploy demo -p ScrapyProject
# 运行命令查看服务端状态
curl http://localhost:6800/daemonstatus.json
- 查看项目spide
通过scrapyd-deploy -l 查看当前目录下的可以使用的部署方式(target)
scrapy list
scrapyd-deploy -l
scrapyd-deploy -L xxxx
Scrapyd API接口
scrapyd的web界面比较简单,主要用于监控,所有的调度工作全部依靠接口实现.
官方文档: http://scrapyd.readthedocs.org/en/stable/api.html
开启爬虫 schedule
curl http://localhost:6800/schedule.json -d project=项目名称 -d spider=爬虫名
停止 cancel
curl http://localhost:6800/cancel.json -d project=项目名称 -d job=jobID
列出爬虫
curl http://localhost:6800/listspiders.json?project=项目名称
删除项目
curl http://localhost:6800/delproject.json -d project=项目名称
SpiderKeeper可视化部署
SpdierKeeper通过配合scrpyd管理爬虫,支持一键式部署,定时采集任务,启动,暂停等一系列的操作.原理是: 对scrapyd的api进行封装,最大限度减少你跟命令行交互次数.
依赖包安装
- scrapy
- scrapyd
- SpiderKeeper
启动SpiderKeeper
spiderkeeper --server=http://localhost:6800
启动成功后, 在浏览器访问127.0.0.1:5000,效果如下:

创建项目
若使用scrpayd-deploy工具部署后,spiderkeeper无法自动识别出部署的项目,必须在网页中手动部署.
- 在scrpay项目中scrapy.cfg文件中写好scrapyd服务器信息
- 生成egg文件命令
scrapyd-deploy --build-egg output.egg
- 上传文件

运行项目
spiderkeeper
可以一次运行和定时周期运行。
访问127.0.0.0:5000端口,输入用户名和密码(通过下图发现用户名和密码均为admin):
 进入页面之后:
进入页面之后:
- 创建一次性爬虫任务:

- 创建周期性爬虫任务:
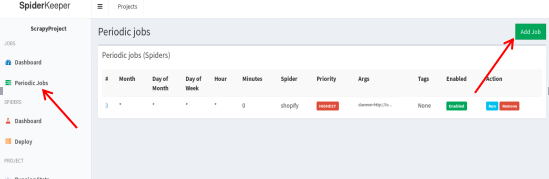
设置你的爬取周期:
 运行爬虫任务之后刷新页面即可查看结果。
运行爬虫任务之后刷新页面即可查看结果。















 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









