







 文章介绍了如何利用MMDetection工具包对视频进行处理,包括通过配置文件和检查点引入模型,查看图片,逐帧处理视频,理解并应用inference_detector函数进行目标检测,以及对检测结果进行灰度处理和图像拼接,最终将图片重新组合回视频。
文章介绍了如何利用MMDetection工具包对视频进行处理,包括通过配置文件和检查点引入模型,查看图片,逐帧处理视频,理解并应用inference_detector函数进行目标检测,以及对检测结果进行灰度处理和图像拼接,最终将图片重新组合回视频。
前言
在参加 OpenMMLab AI 实战营中,有个作业要求利用 MMDetection (目标检测工具包)训练模型,然后利用这个模型对一段小视频进行处理 (保留 mask 部分的彩色, 背景部分取灰)。文章的素材当然也来自实战营啦。这里主要讲一下处理视频的过程,训练模型的过程略过。
一、模型引入
from mmdet.apis import init_detector
model = init_detector(config="../work_dir/balloon.py", checkpoint="../work_dir/latest.pth")
这里 config 为训练模型的配置文件,checkpoint 为训练完保存的模型文件
二、查看图片
要利用 MMDetection 处理视频,就要先知道如何查看模型处理完之后的图片
from mmdet.apis import inference_detector, show_result_pyplot
img_path = "../data/balloon/val/3825919971_93fb1ec581_b.jpg"
result = inference_detector(model, img_path)
show_result_pyplot(model, img_path, result, score_thr=0.85)
结果如下:

三、视频每帧
我们处理视频,很容易可以想到讲视频拆穿一帧一帧处理,一帧就是一张图片,这里利用 mmcv 对视频进行处理
import mmcv
v = mmcv.VideoReader("test_video.mp4")
v.cvt2frames("frame_dir/in")

在处理后我们可以得到 150 张图片

四、处理每帧
0、理解 inference_detector

inference_detector 函数传入一个 model 既训练的模型,和一张或几张图片,重点在于 returns ,返回在这说的不是很清楚,单个返回的是 bbox, segm, 即边框和分割信息
result = inference_detector(model, img)
bbox, segm = result
bbox = np.array(bbox[0]) # bbox 为列表
print(bbox.shape) # (23, 5)
segm = np.array(segm[0])
print(segm.shape) # (23, 1024, 683)
这里的 23 代表检测到 23 个目标
bbox 中含有的信息为 (x, y, w, h, n)即距离左上角的宽度和长度、框的长度和宽度、概率
segm 中 (1024, 683)为图片宽度和高度,值为 Bool, true 则为 mask, false 则为背景
另外,可以看到这里引入了 numpy,一方面是为了处理方便,一方面是为了加快速度
1、处理图片
score_thr = 0.85
balloon_cnt = bbox[bbox[:, -1] > score_thr].shape[0]
data = mmcv.imread(img_path) # -> ndarray
tmp = data.copy()
# Gray = (Red * 0.3 + Green * 0.59 + Blue * 0.11)
# 'bgr'
data[:, :, 0] = data[:, :, 2] * 0.3 + data[:, :, 1] * 0.59 + data[:, :, 0] * 0.11
data[:, :, 1] = data[:, :, 0]
data[:, :, 2] = data[:, :, 0]
for balloon in segm[:balloon_cnt]:
data[balloon] = tmp[balloon]
mmcv.imwrite(data, "out.jpg")
这里首先判断了一下为目标(这里是 balloon 气球)大于 0.85 概率的数量,接着对整张图片进行灰度计算 (这里要注意 mmcv.imread() 返回的通道为 bgr ),最后将含有目标的部分用原来的数值替代,最后利用mmcv 保存图片
结果如下:

五、拼接图片
上面我们将视频拆成图片,最后我们当然要将图片拼接成视频啦
mmcv.frames2video(frame_dir="frame_dir/out", video_file="video_out.mp4")
利用 mmcv 一行代码搞定
最后
最后看看结果吧

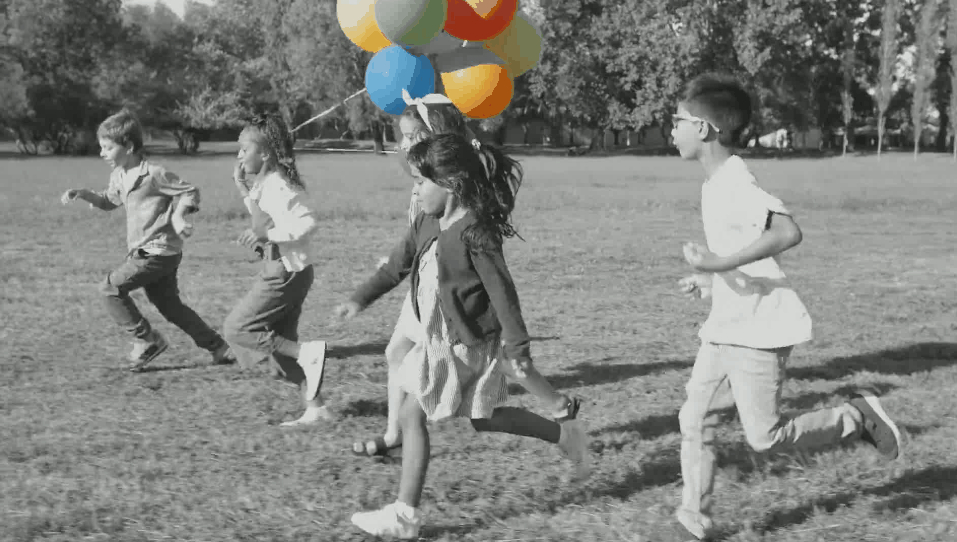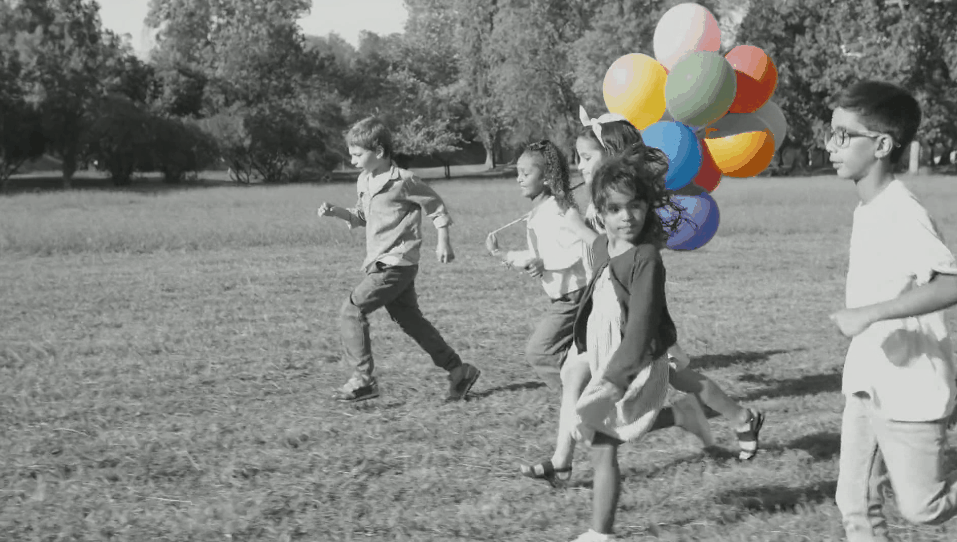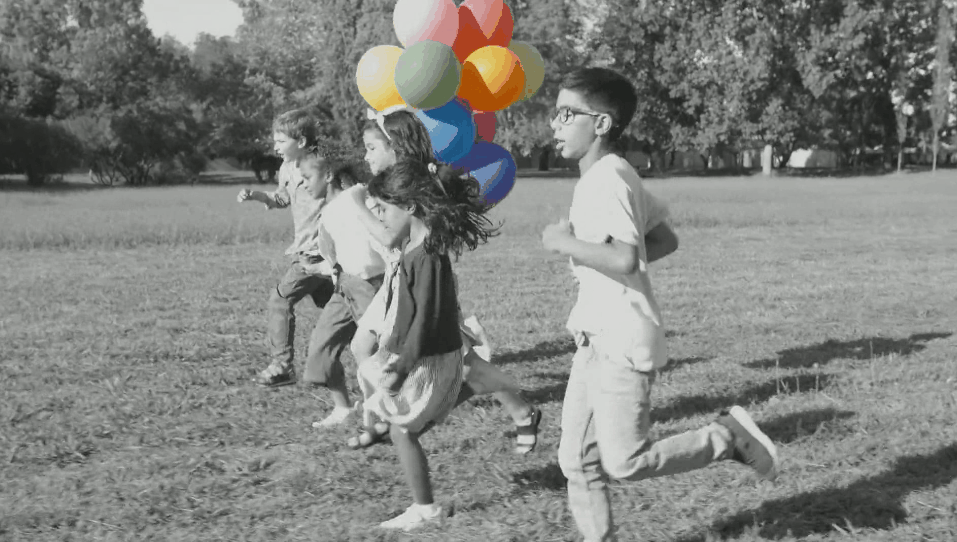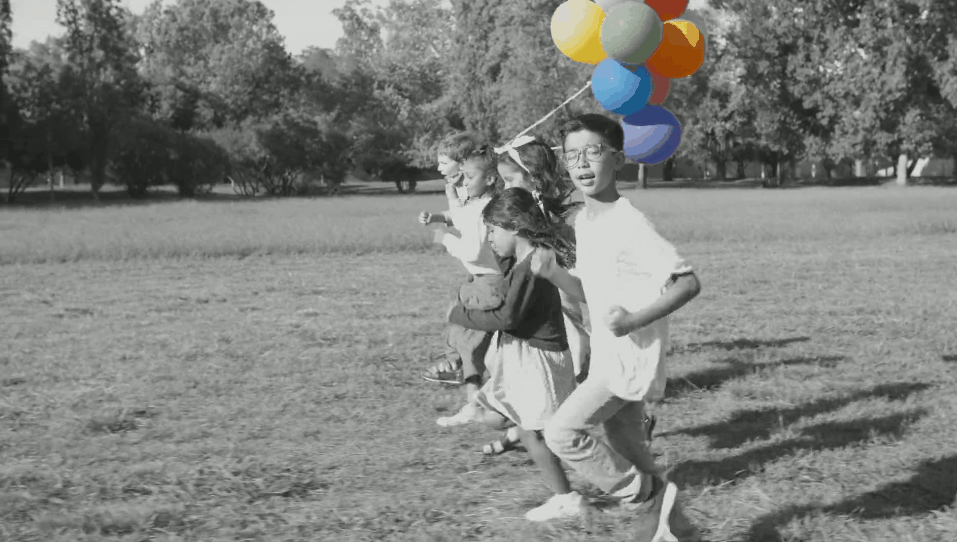


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









