







这篇文章主要介绍了微信公众号文章的爬取过程,分析采用js加密和cookies设置等反爬机制。
更多方案详细分析流程和接口说明地址:https://wblog-one.vercel.app/
在早期的微信公众号版本中,反爬机制并不包括js加密,主要是依靠监控用户IP地址,如果单个IP地址频繁访问公众号会出现被封号的情况。但在新版本中,微信公众号加入了js加密反爬机制以加强安全性。
具体的文章爬取过程如下:
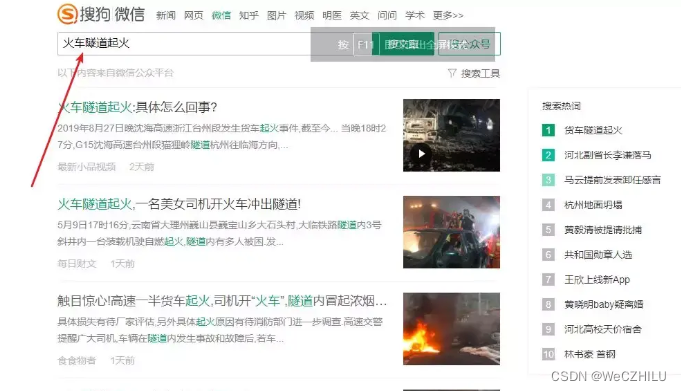
1. 打开搜狗微信页面,并在输入框中输入任意关键词,例如“火车隧道起火”。
2. 搜出的结果将是与关键词相关的公众号文章列表。
3. 爬虫程序通过设置cookies以及JS解密,解密获取被加密的文章地址。
4. 爬虫程序会模拟浏览器,反复地请求公众号文章的URL链接,并且抓取有用数据。
为了应对上述反爬机制,爬虫程序通常采用常轮换IP地址、随机延迟请求时间、多代理池轮换等手段,以提高请求的稳定性和隐蔽性,确保获取数据的准确性。
更多方案详细分析流程和接口说明地址:https://wblog-one.vercel.app/
具体分析步骤
打开搜狗页面搜狗微信页面,在输入框中输入任意关键词例如火车隧道起火,搜出来的都是涉及关键词的公号文章列表
更多方案详细分析流程和接口说明地址:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3722
3722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









