








Hill climbing search algorithm is one of the simplest algorithm which falls under local search and optimization techniques. Here’s how it’s defined in ‘An Introduction to Machine Learning’ book by Miroslav Kubat:

Evaluation function at step 3 calculates the distance of the current state from the final state. So in case of 3x3 Slide Puzzle we have:
Final State:
1 2 3
4 5 6
7 8
Consider Current State:
1 2 3
4 5 6
7 8
Evaluation Function dF calculates the sum of the moves required for each tile to reach its final state. Since tiles 1 to 7 are already in it’s correct position, they don’t need to be moved. However, tile 8 is 1 move away from it’s final position.
dF(8) = m(1)+m(2)+m(3)+m(4)+m(5)+m(6)+m(7)+m(8)
= 1
Hill climbing evaluates the possible next moves and picks the one which has least distance. It also checks if the new state after the move was already observed. If true, then it skips the move and picks the next best move. As the vacant tile can only be filled by it’s neighbors, Hill climbing sometimes get’s locked and couldn’t find any solution. It’s one of the major drawbacks of this algorithm.
Another drawback which is highly documented is local optima. The algorithm decides the next move(state) based on immediate distance(cost), assuming that the small improvement now is the best way to reach the final state. However, the path chosen may lead to higher cost(more steps) later.
Analogues to entering a valley after climbing a small hill.
In order to get around the local optima, I propose usage of depth-first approach.
Hill Climbing with depth-first approach
Idea is to traverse a path for a defined number of steps(depth) to confirm that it’s the best move.
- Loop over all the possible next moves(states) for current state.
- Call step 1 until depth d is reached. This generates a tree of height d.
- Pick the move(state) with minimum cost(dF)
- Return dF so that evaluation can be done at
depth-1level.
I observed that depth-first approach improves overall efficiency of reaching the final state. However, its memory intensive, proportional to the depth value used. This is because, system has to keep track of future states as per the depth used.
Here’s a brief comparison of the Distance by Moves charts for various depths:
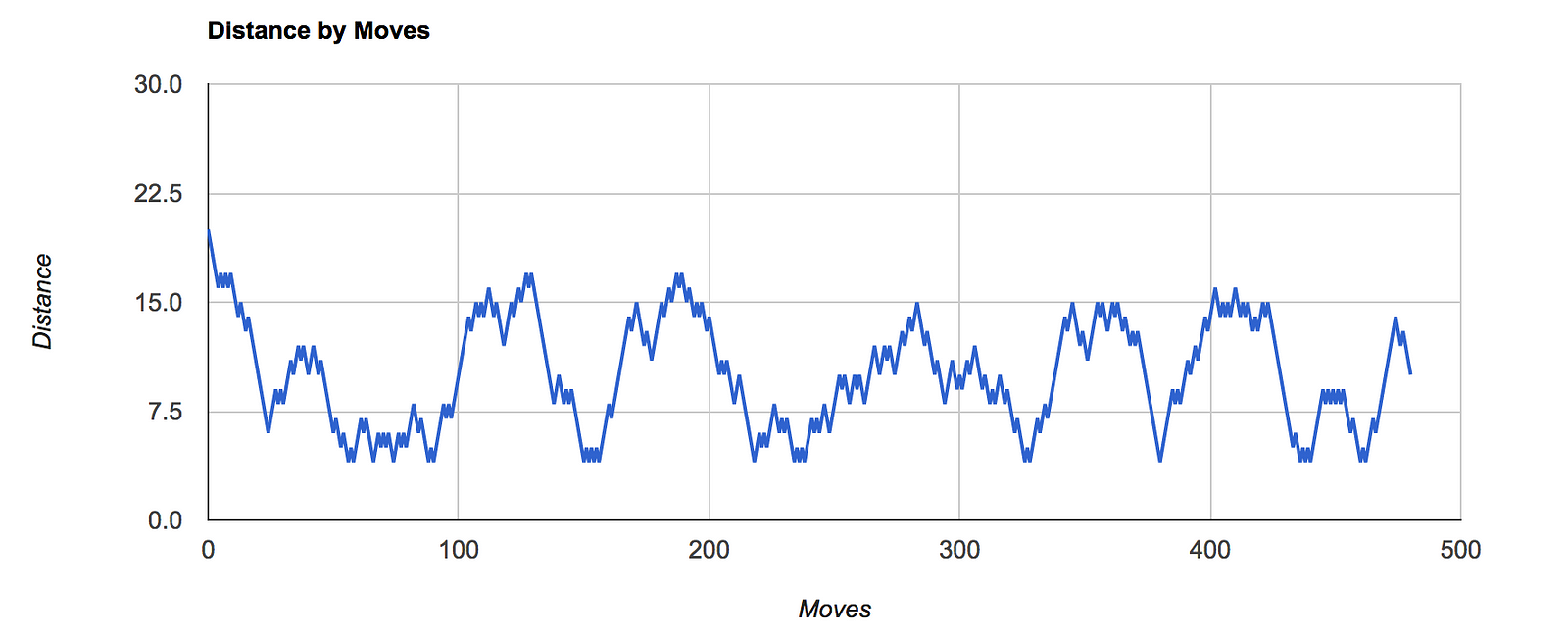
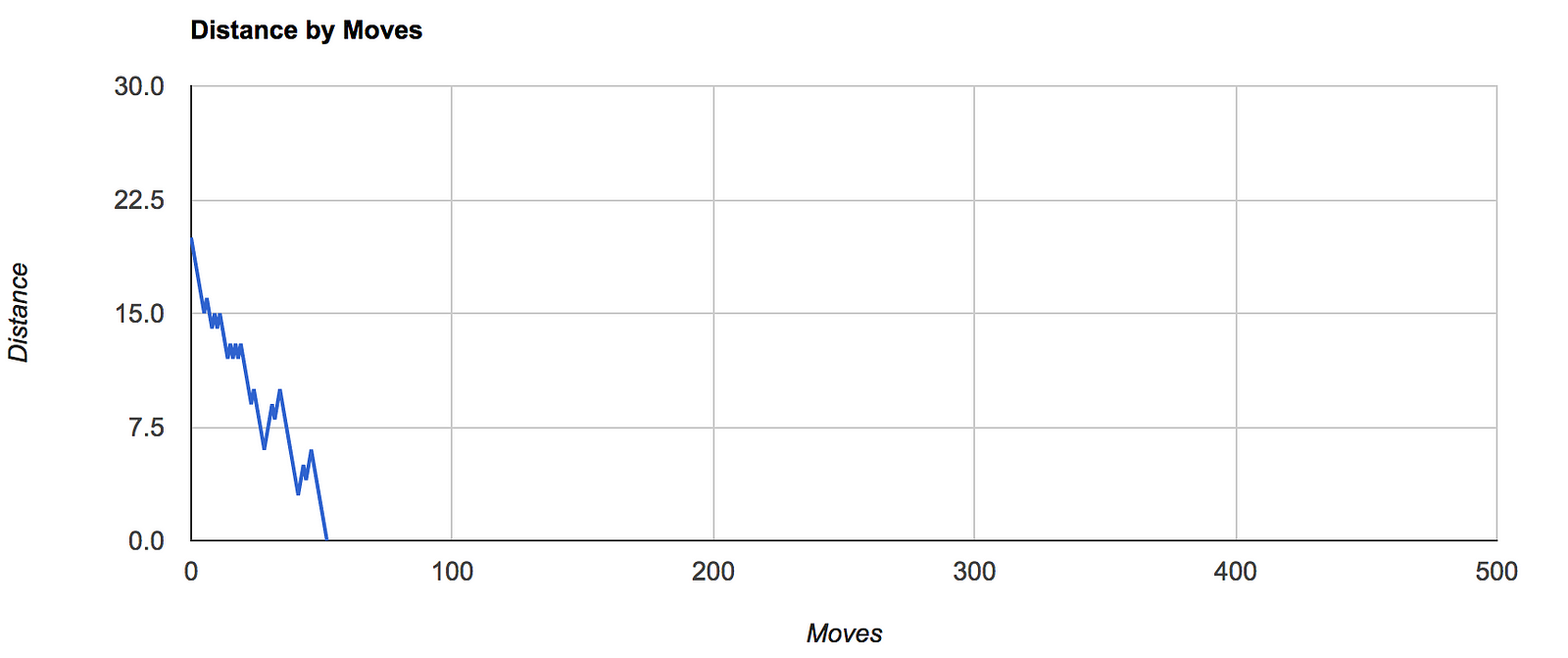
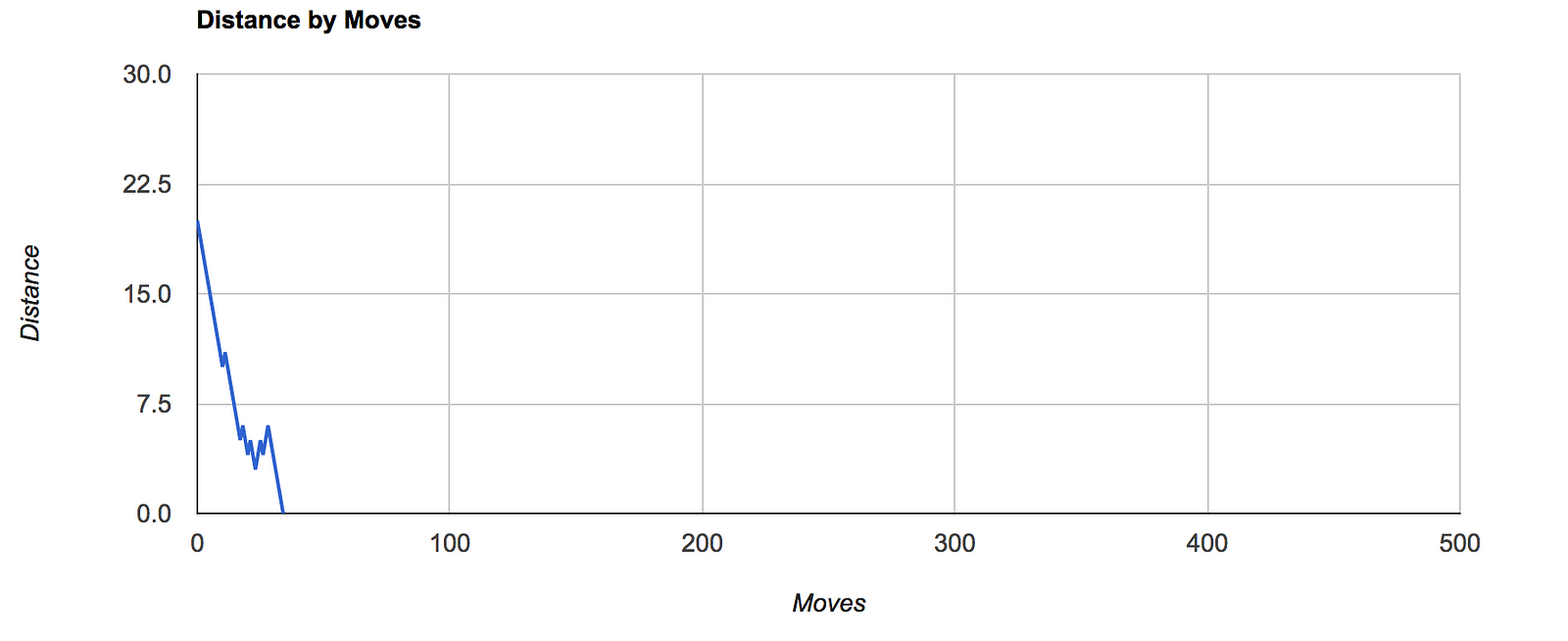
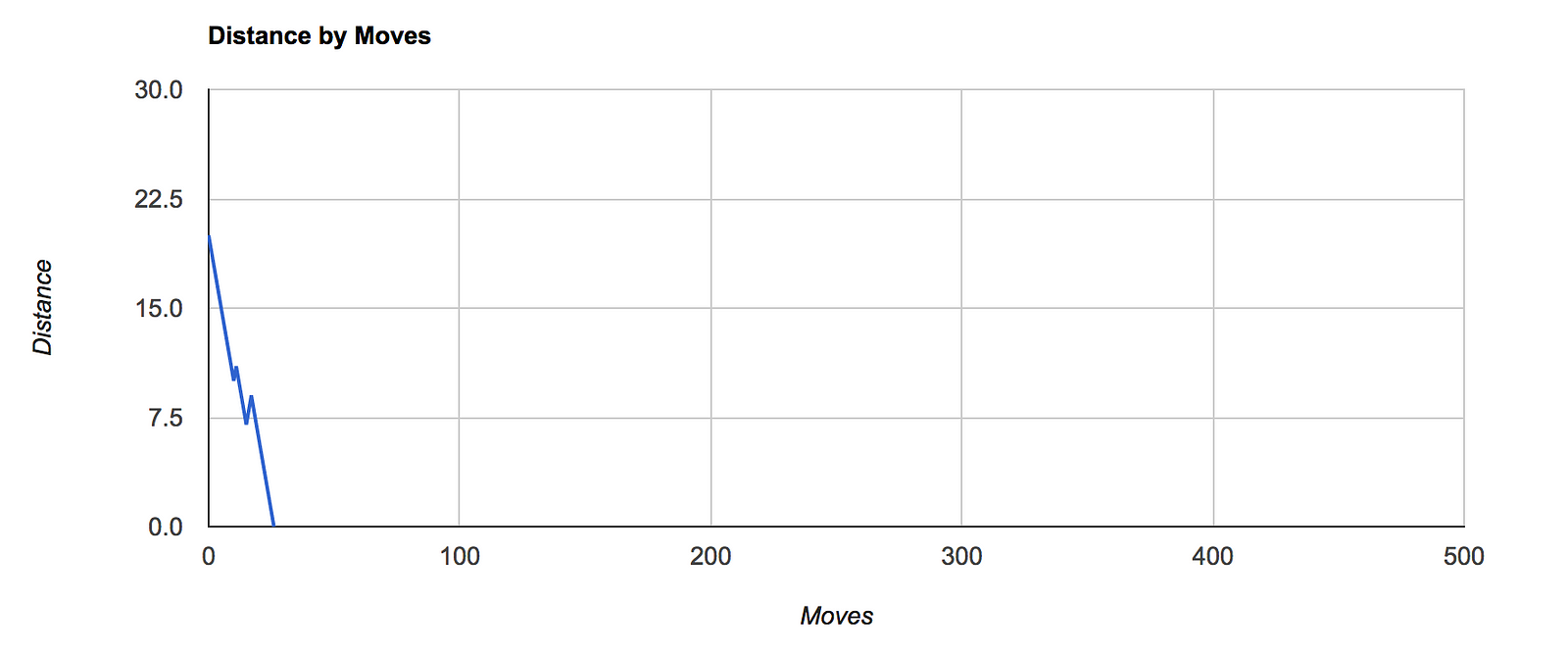
A live evaluation can be performed here. Try out various depths and complexities and see the evaluation graphs. Sometimes, puzzle remains unresolved due to lock down(no new state).
Or, if you are just in mood of solving the puzzle, try yourself against the bot powered by Hill Climbing Algorithm.
Hit the like button on this article every time you lose against the bot :-)
Have fun!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









