







用户行为序列是推荐系统中最重要的一类特征,比如用户的点击序列、观看序列等等。
一、行为序列信息构成
序列中每个元素的embedding由多个部分拼接而成,以下为两个主要部分:
1、物料ID的embedding。
2、时间差信息。即物料消费的时间与当前时间的时间差值。
3、其他信息,比如观看视频的一些元信息(比如作者、来源、分类等)还有动作程度(比如观看时长、观看次数等)。
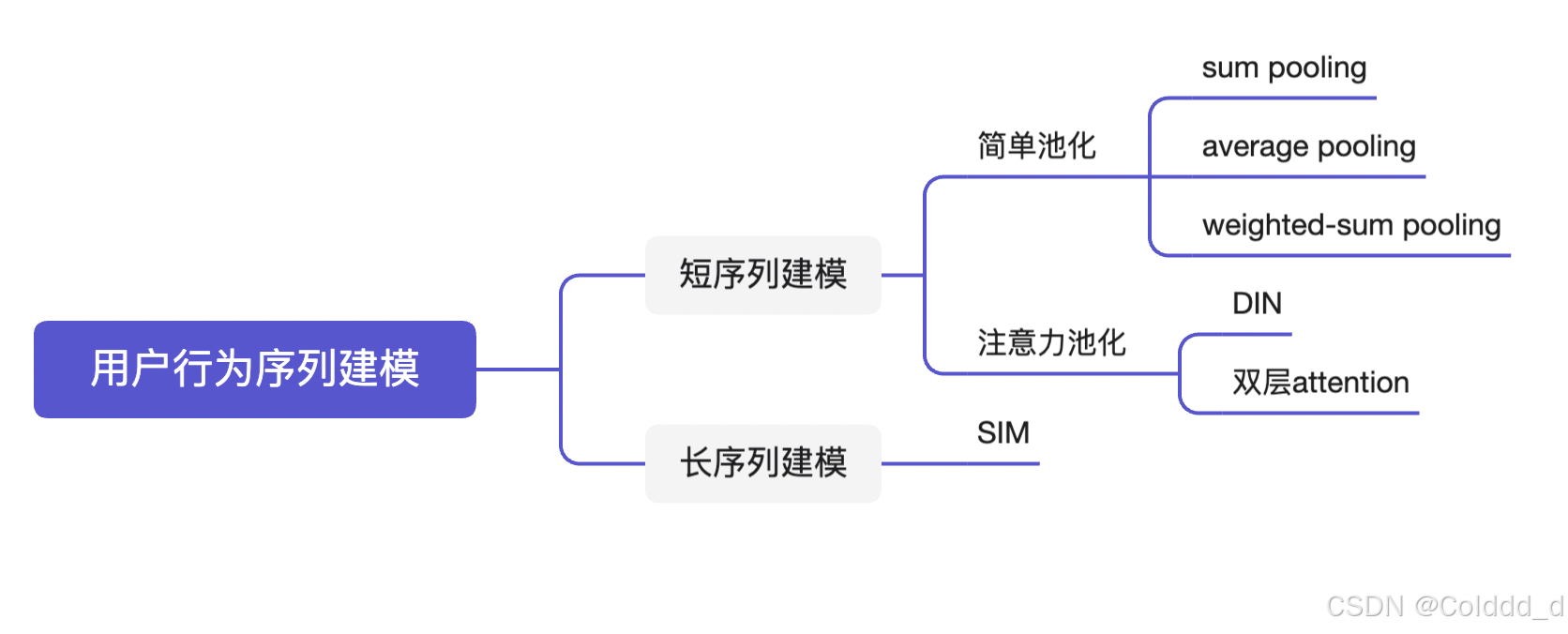
二、简单pooling
要将用户行为序列压缩成一个embedding,最简单的方式是按位操作(element-wise)。
1、Sum pooling:
Youtube DNN就采用sum pooling来建模。这样做的缺点如下:
- 用户行为与候选物品之间缺少特征交叉。
- 推荐不同候选物品时,用户行为序列建模结果不变。
- 每个行为同等对待,重要性没有区分。
2、Average Pooling:
3、Weighted-sum Pooling:,权重由时间差或者动作程度等来决定。
简单pooling得到的用户兴趣是固定的&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









