







看别人做数据分析/训练模型的时候,总会看到在数据预处理阶段有一步「数据归一化」,scikit-learn代码如下:
from sklearn import preprocessing
x = ... # x为样本数据
min_max_scaler = preprocessing.MinMaxScaler()
x_new = min_max_scaler.fit_transform(x)那么,为什么需要这样做呢?主要原因是为了数值稳定。
下面用多层感知机(MLP)来举例。
反向传播算法(BP)往往是神经网络能够“学”到知识的手段,在单层感知机中,有如下等式:

其中,w是权重,x是输入,b是偏置,σ(·)是sigmoid函数。
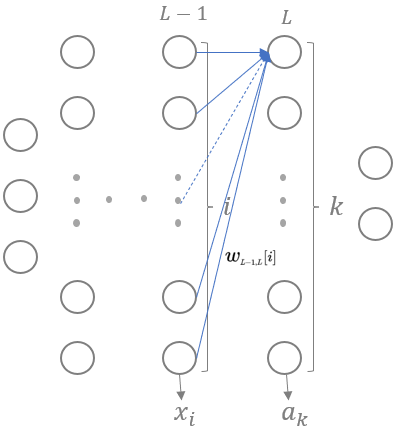
在形如图1的MLP中,有如下等式:


其中,上标[L-1]指第L-1层,其实挺好理解:用第L-1层的信息计算第L层。
根据反向传播推导:(用第一个隐藏层->输入x的反传过程举例)
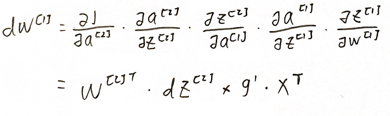
可以看出,每一次更新都有一项wi·gi',这就意味着:随着网络的加深,由于链式法则需要连乘wi·gi',而每一个wi·gi'都比较大(大于1),从而出现梯度爆炸。
-
未进行归一化,权重变大:(红线粗细反应权重大小)
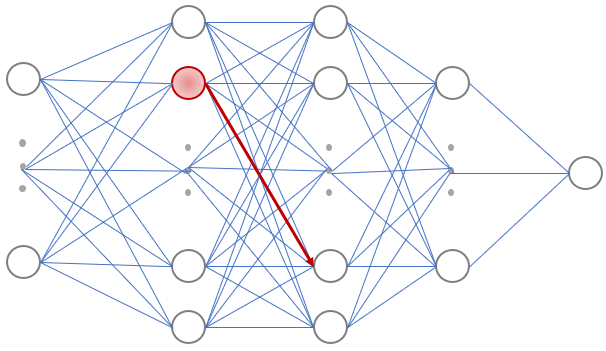
-
进行归一化,权重变小:
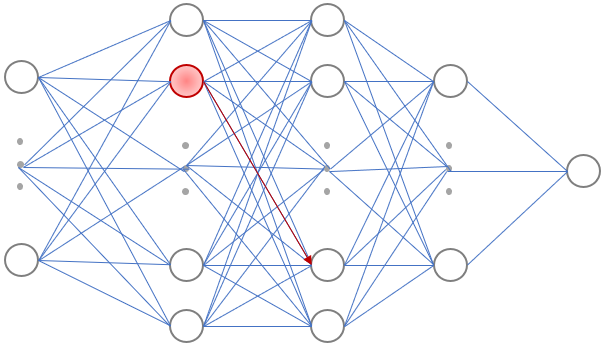
另外,权重增量dw和输入x有关系,x越大,那么dw越大,这就意味着:在梯度下降过程中,较大x的更新速度要大于较小x,从而需要更多的迭代才能找到最优解。如果把所有x归一化到相同的数值区间后,优化目标的等值图会变得更圆(下图右),从而每个x的更新速度变得更一致,更容易找到最优解:
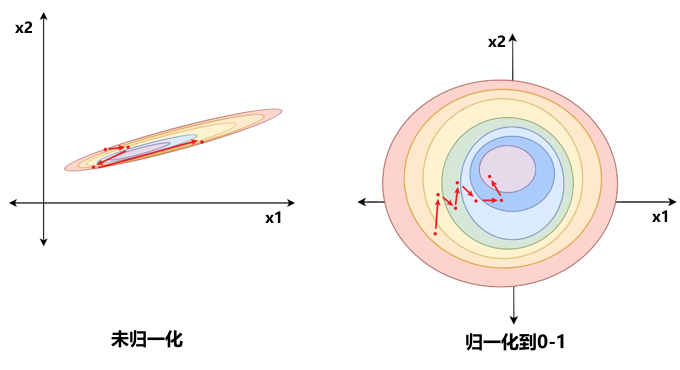
小结:归一化实际上就是使数据的量纲保持一致,使得模型更容易训练。
如有新的想法,期待交流探讨~
















 1441
1441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









