







本文思路
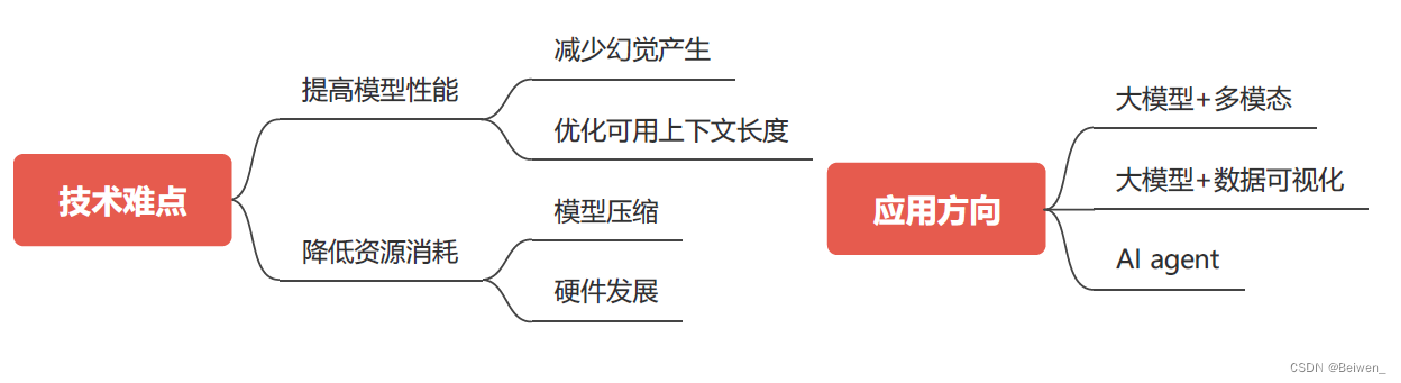
一 技术难点
1.1 提高模型性能
1.1.1 减少幻觉产生
让我们首先用几个例子看一下什么是幻觉:
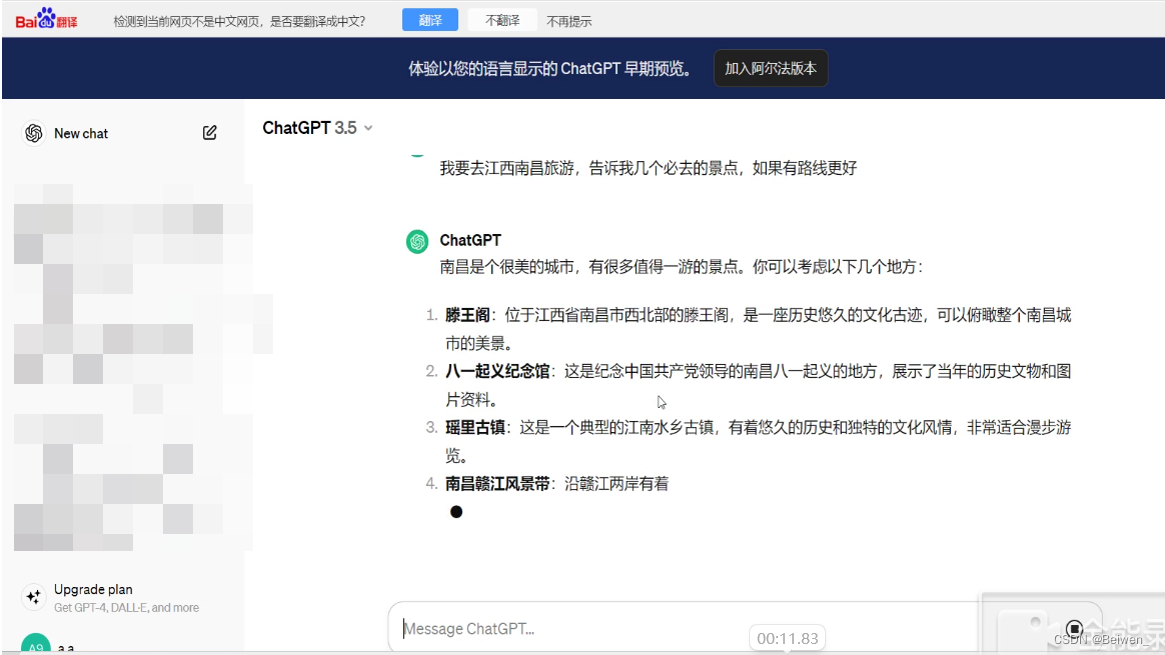
这里的“瑶里古镇”并非江西南昌的景点,而是江西景德镇的景点;
下面我编造一个奢侈品品牌叫“阿拉尊品”,看看chat3.5怎么说:
chat3.5的幻觉案例
另外,姑姑和姑父结婚生子的严重后果?
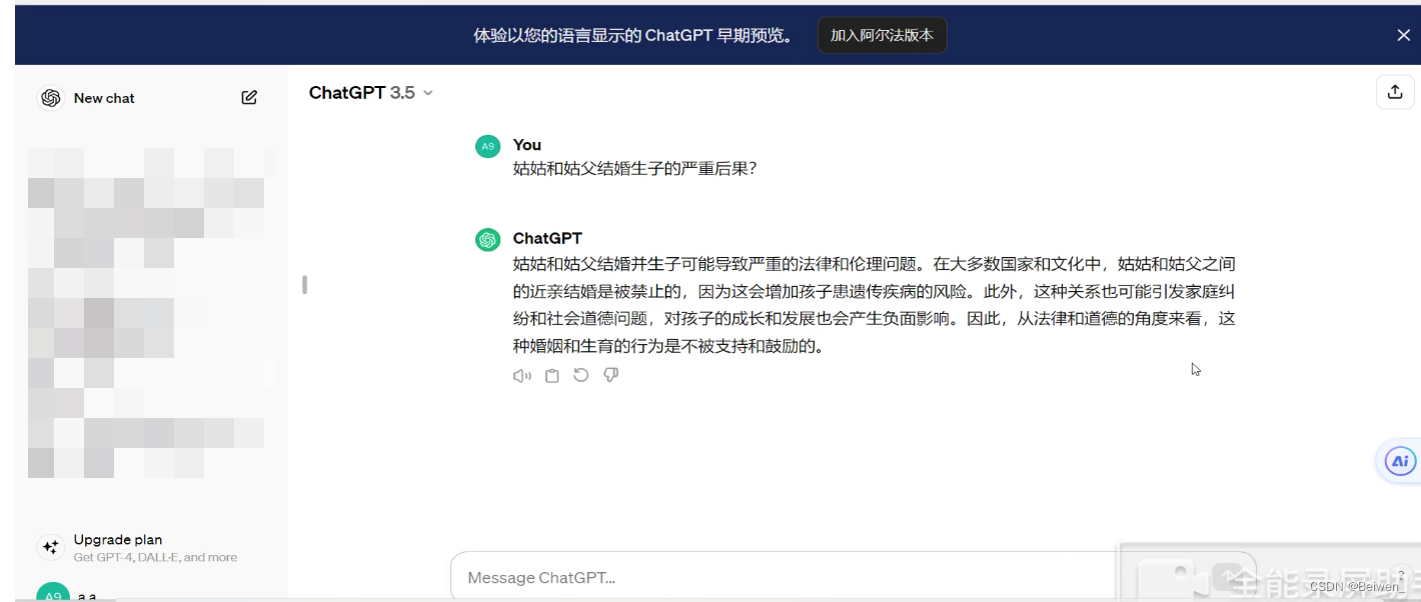
以上便是我们使用chat3.5来产生的幻觉案例,当然,由于这个模型是比较早发布的,现在很多新模型的“幻觉”问题已经被改善,本文也是主要为了介绍概念;
三类主要幻觉
参考资料:Cognitive Mirage: A Review of Hallucinations in Large Language Models https://arxiv.org/abs/2309.06794,以及https://zhuanlan.zhihu.com/p/666278645
-
三类主要幻觉:
- 输入冲突幻觉
- 上下文冲突幻觉
- 事实冲突幻觉(最为常见!)
-
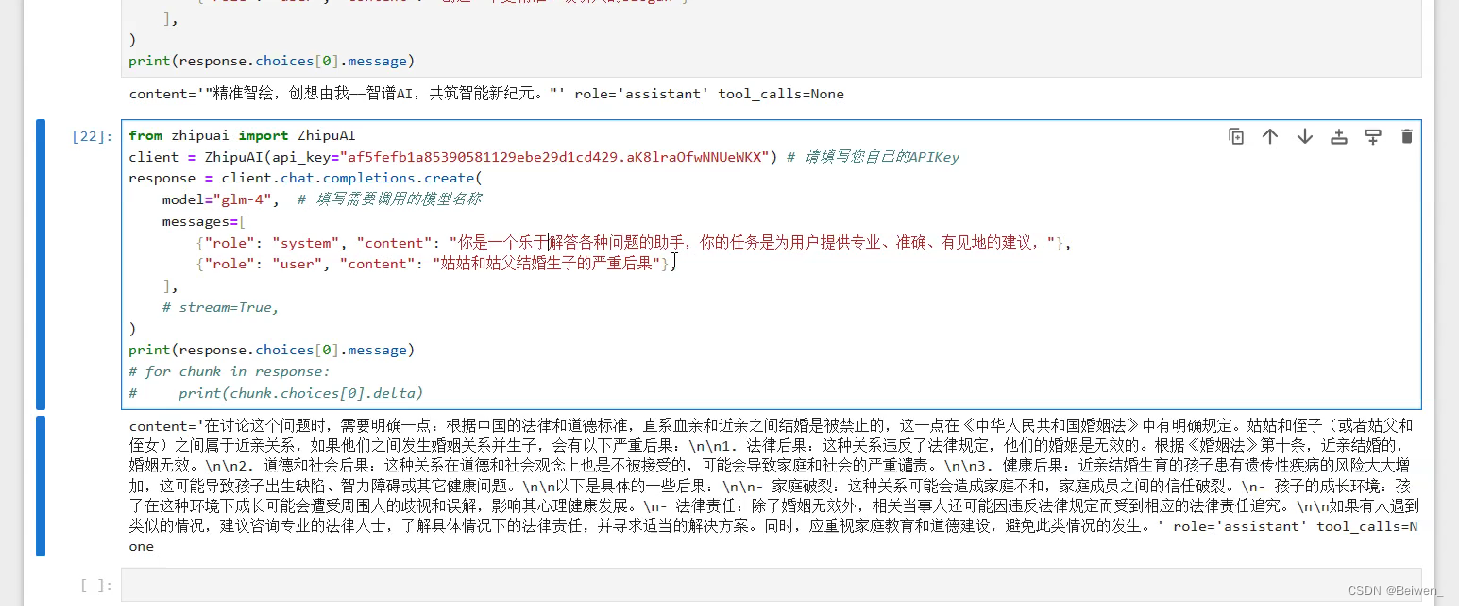
输入冲突幻觉指的是LLM回答的结果与user query冲突,比如说下图中我问的是姑姑和姑父结婚,而LLM回答的却是“姑姑和侄子”或者“姑父和侄女”结婚是近亲结婚;
-
上下文冲突幻觉比较少见,指的是LLM自身的回答中出现冲突;举例:

用户:告诉我一些关于NBA总主管的信息?
模型:在全球最受欢迎的篮球联赛 NBA 中,专员亚当-西尔弗一直被视为领导者和决策者。其次,西尔弗多次强调他对球员健康和福祉的关注。在这种情况下,斯特恩的言行与其所宣称的关心球员福利的目标相冲突。
可以看出来在以上的回答中,模型先提到了西尔弗,而后没有任何衔接的转向了对斯特恩的描述。
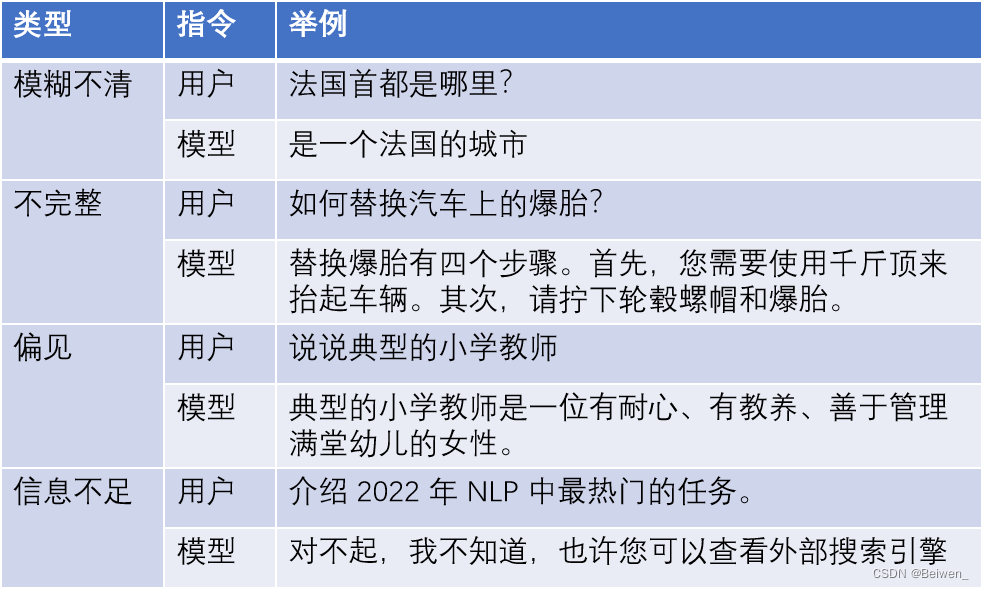
- 其他问题与幻觉的区分
- 模糊不清
- 不完整
- 偏见
- 信息不足(拒绝回答)
那么,如何减少幻觉的产生呢?
在介绍方法之前我们先介绍一下LLM的训练过程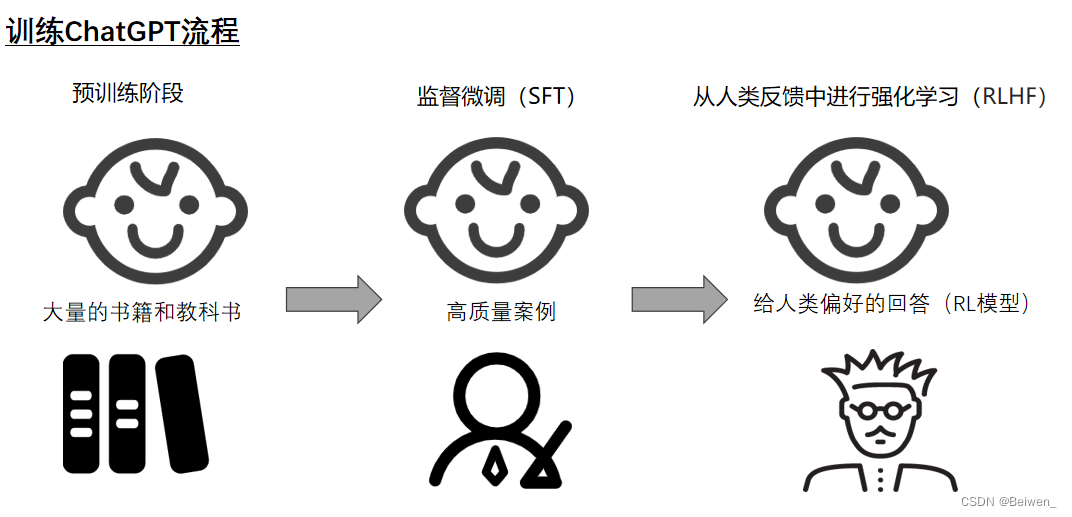
- 首先是预训练阶段,在这个过程中我们会喂给大模型大量的数据,就像给让一个小孩去阅读大量书籍和教科书,此时的关键是走量;
- 其次是SFT(监督微调)阶段,我们给大模型少量、高质量数据,实现有监督的微调;
比如说多多给他读诗,语段等等,使其最终变成特定领域的大模型, 比如说情感分析,机器翻译等;
类比小孩终于读了大学,学了本专业的高质量基础知识; - 最后是RLHF阶段,也就是从人类反馈中进行强化学习,而此时“人类反馈”常常使用的是一个强化学习模型(reinforcement learning模型-RL模型);我们训练RL模型来为LLM生成反馈,让LLM知道什么是很好、好、中等、不好……等等答案;类比小孩经过了导师的点拨成了能给给出高质量回答的博士;
减少幻觉产生的方法
-
预训练阶段;
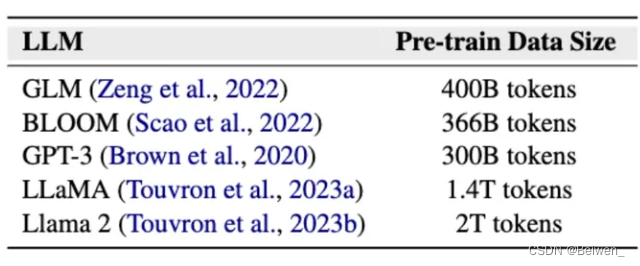
该阶段产生幻觉的原因:训练数据的质量问题,毕竟在该阶段有极其大量的数据喂给大模型训练,如果此时数据质量不高,必然给大模型造成影响;下图是各个模型用于预训练过程的数据量,由图可见最小也是300B的tokens
这里介绍一下什么是token,可以理解为大语言模型可以处理的最小单元,可能是一个字、一个词;
- 方法1:在LLM时代之前——手动处理
- 方法2:自动选择可靠数据
e.g.Llama2在构建预训练语料库时,从维基百科(这种基本上绝对可靠的数据)等来源中向上抽取数据 - 方法3:过滤掉噪声数据
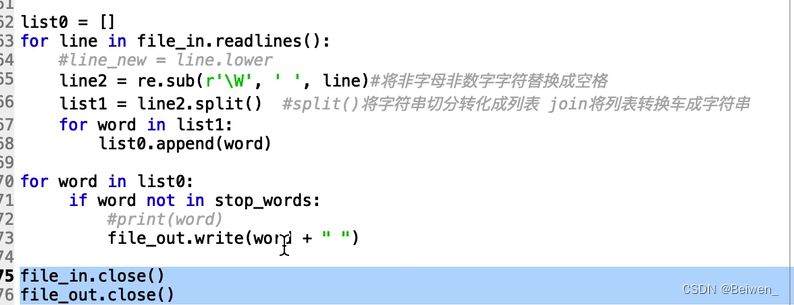
比如说如下代码就是一个过滤掉噪声的一个示例,我们也可以使用这样的方式人工优化预训练数据,使得大模型减少噪声(图源,b站up主,侵即改)
-
SFT阶段来改进(SFT:Supervised Fine-Tuning,监督微调)
- 该阶段产生幻觉的原因:“行为克隆”
- 解决方法:可以引入一些诚实的样本,即承认无能力回答的回答
- 该方法存在的问题:由于大模型倾向仿照在SFT阶段中人类喂给的答案模式来回答,所以如果我们引入“诚实样本”也可能造成LLM原本知道问题的答案,却还是倾向于回答“无能力”,以减少幻觉。
-
RLHF阶段来改进(Reinforcement Learning from Human Feedback,即从人类反馈中进行强化学习)
e.g.基于诚实的强化学习(honesty-oriented RL)可以帮助语言模型自由探索知识边界
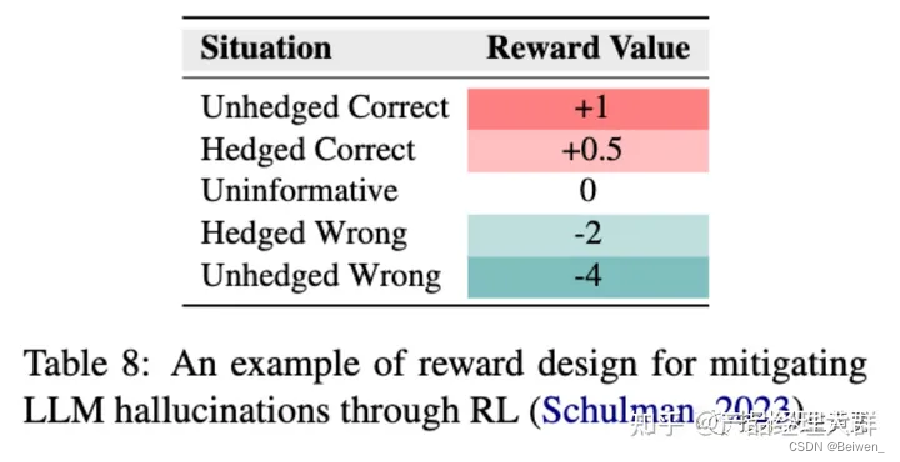
下图是一位科研人员提出的训练RL模型的方法,hedged指的是拐弯抹角的,而unhedged指的是坚定的,当LLM给出拐弯抹角的正确答案时,RL模型会给出少量奖励,而不是坚定正确答案时的大量奖励;
-
其他解决方案
- 提示词工程 Prompt engineering
e.g.“系统提示”(即ChatGPT的API中system参数)中明确告诉LLMs不要传播虚假信息。
案例可以详见下面的视频,我对以下视频做出解释- 在给出特殊提示之前,LLM生成的回答中“八大仙人”其实是产生了幻觉,真实的景点是“八大山人”;做了提示工程之后则改为了正确的“八大山人”
- 提示词工程 Prompt engineering
提示词工程的作用-案例
后面的内容会在之后的文章里跟上哦~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











