







Java 小白的历练之路 —— 从 0 到 1
CONTENTS
- 写在前面:
个人博客地址:https://wl2o2o.github.io/- 写作背景: 笔者是一名大三在校生,目前正在努力学习 Java 方向,笔记书写于22年暑假期间,虽然起步有点晚,但是每天都在坚持,只要努力,光一定会 shine 向我的!
- 笔记发表于此,与君共勉,一同学习!加油!!!
Essay笔记来源
Java全栈知识体系——泛型
哔哩哔哩老杜Java——哔哩哔哩
Java程序员进阶之路——沉默王二
老杜Java零基础
P58
具体的命名规范:
1、顾名思义;
2、驼峰原则:一高一低:例如:PowerNodeNotes;
3、类名、接口名首字母大写 ;
变量名方法名首字母小写;
常量名全部大写,单词之间用_下划线连接:USER_AGE;
P60
关键字:
int、long、float…public static void boolean private protect 蓝色字体、小写显示
P63
提取帮助文档:也就是写在/** 这里面的注释信息。
*
*@author
*@version
*/
javadoc -d+文件夹名(文件夹绝对路径)+(需要提取的信息)+Java源文件
例如:javadoc -d javaapi -author -version VarTest02.java
P70
1,变量的分类:
public class Test{
int i;//全局变量
public static void main(String[] args){
int j;局部变量
}
}
2,变量的作用域:即有效范围(出了大括号就处于非作用域)!
P72
标识符可以标志什么:
类名、方法名、常量、变量、接口名
记录所有编程出现的错误,记录错误~!
P113
public class Homework1{
public static void main(String[] args){
int i=10;
i=i++;
System.out.println(i); //运行结果为10!
}
}
//Java和C++源代码运行结果不一样,C++结果为11、Java为10.
原因:编译器原理不一样,其中Java的代码可以理解为一下三行:
(在Java语言中i++,这种表达式在执行的时候,会提前将i变量找一个存储空间临时存储,不同于C++)
int temp=i;
i++;
i=temp;
因此!!!可以理解为:分号之后++再加一
P116
接收键盘输入:
在Java中则怎么接收键盘信息呢?
第一种形式:
//创建一个键盘扫描器对象(s为对象名,上下对应)
java.util.Scanner s =new java.util.Scanner(System.in);
java.util.Scanner s =new java.util.Scanner(System.in);
int i=s.nextInt();
System.out.println();
String str =s.next();
System.out.println();
//接收用户的输入,从键盘上接受一个int类型的数据、
//i变量有值了,并且i变量中保存的这个值是用户输入的数字。
//i变量就是接收键盘数据的
int i=s.nextInt();
System.out.println("您输入的数字是:"+i);
int j=s.nextInt();
System.out.println("您输入的数字是:"+j);
//字符串类型
String str = s.next();
其他数据类型类似
其中println:print为打印、ln为换行。
另外一种形式:
import java.util.Scanner; //idea可以自动引入
//创建键盘扫描器对象
Scanner s = new Scanner(System.in);
int num1 = s.nextInt();
System.out.println(num1+"+"+num2+"=");
头歌实践教学平台项目案例练习:
//什么是类、怎么创建类:
package step1;
public class Test {
public static void main(String[] args) {
/********** Begin **********/
//创建Dog对象
//设置Dog对象的属性
Dog wuhuarou = new Dog();
wuhuarou.name="五花肉";
wuhuarou.color="棕色";
wuhuarou.variety="阿拉斯加";
//输出小狗的属性
System.out.println("名字:" + wuhuarou.name + ",毛色:" + wuhuarou.color+ ",品种:" +wuhuarou.variety );
//调用方法
wuhuarou.eat();
wuhuarou.run();
/********** End **********/
}
}
//在这里定义Dog类
/********** Begin **********/
class Dog{
String name,color,variety;
void eat(){
System.out.println("啃骨头");
}
void run(){
System.out.print("叼着骨头跑");
}
}
/********** End **********/
关于质数:
package step2;
public class FindZhiShu {
public static void main(String[] args) {
/*
打印输出质数的时候务必按照如下格式:System.out.print(质数+" ");
使用print进行打印同时被打印输出的质数后加上一个空格,
以便于与平台提供的结果格式保持一致!
*/
/**********begin**********/
a:for(int i = 2;i < 1000;i++){ //此循环遍历次数较多,若对代码效率有要求,则可进一步改进代码:如下:
for(int j = 2;j<i;j++)
if(i%j==0){
continue a;
}
System.out.print(i+" ");
}
/**********end**********/
}
}
**********************改进之后的代码*********************
package step2;
public class FindZhiShu {
public static void main(String[] args) {
/*
打印输出质数的时候务必按照如下格式:System.out.print(质数+" ");
使用print进行打印同时被打印输出的质数后加上一个空格,
以便于与平台提供的结果格式保持一致!
*/
/**********begin**********/
System.out.print("2 "); //因为2是特殊的质数,又因下面循环会自动跳过偶数,因此先将2打印出来。
a:for(int i = 3;i < 1000;i+=2){
for(int j = 2;j<i;j++)
if(i%j==0){
continue a; //此方法运用了给循环做标记,以此可以对continue和break进行明确的命令指示。
}
System.out.print(i+" ");
}
/**********end**********/
}
}
《方法》
定义:
是可以完成某一个特定的功能,并且可被重复利用。
在面向对象的语言中,函数称为方法,类似于C语言总的函数。方法写在类体中,可以写在main函数前后,不分顺序,因为main函数为执行入口。
方法结构定义:
【修饰符列表】 返回值类型 方法名 (形式参数列表){
方法体;
}
注意:
【】符号叫中括号、以上中括号里的内容表是不是必须的,是可以选择的,方法体由Java语句构成;
关于修饰符列表:
也不是必须的,目前可写成public static(称为静态方法)
break与return的区别:
break:用来终止一个switch语句和距离最近的循环
return:用来终止一个方法。
方法优化:
例题:编写一个方法,输出大于某个正整数n的最小的质数(思考:这个方法应该取什么名字,这个方法的形参是什么,返回值类型是什么?)
public class Homework2{
public static void main(String[] args){
//假设目前系统给定一个正整数n,n为5
int n = 7;
//输出大于5的最小质数
while(true){
n++;
//需要一个判断是否为质数的方法。。
if(isZhiShu(n)){
System.out.print("最小质数是"+n);
break;
}
}
}
//该方法返回一个Boolean字符,用于main方法中的if判断语句。
public static boolean isZhiShu(int num){
//判断num是否为质数
//可以利用循环取余的方法来判断是否可以整除除1和本身的数字
for(int i = 2; i < num;i++ ){
if(num%i==0){
return false;
}
}
//return语句容易写在for循环里面,写在里面判断不完全
//return之所以写在外面是因为要让循环执行完毕,执行完毕才可以正确判断
return true;
}
}
编程思路以及改进版:
import java.util.Scanner;
public class Homework2{
public static void main(String[] args){
//以下代码省略,新增打印质数的方法
/*
//假设目前系统给定一个正整数n,n为5
int n = 7;
//输出大于5的最小质数
while(true){
n++;
//需要一个判断是否为质数的方法。。
if(isZhiShu(n)){
System.out.print("最小质数是"+n);
break;
}
}
*/
//引入用户输入的数据
Scanner s = new Scanner(System.in);
int num = s.nextInt();
//直接调用打印质数的方法
printZhiShu(num);
}
//代码不够精简,还可以在main()中调用打印输出质数的方法
public static void printZhiShu(int num){
//while循环仍可精简,但是精简之后不易理解,代码如下:
/*
while(isZhiShu(num)){
}
System.out.print("最小质数是"+num);
*/
/*while(true){
//需要一个判断是否为质数的方法。。
if(isZhiShu(++num)){
System.out.print("最小质数是"+num);
break;
}
}
*/
while(!isZhiShu(++num)){
}
System.out.print("最小质数是"+num);
}
//该方法返回一个Boolean字符,用于main方法中的if判断语句。
public static boolean isZhiShu(int num){
//判断num是否为质数
//可以利用循环取余的方法来判断是否可以整除除1和本身的数字
for(int i = 2; i < num;i++ ){
if(num%i==0){
return false;
}
}
//return语句容易写在for循环里面,写在里面判断不完全
//return之所以写在外面是因为要让循环执行完毕,执行完毕才可以正确判断
return true;
}
}
//以上代码为编程思路,以下为精简代码:
/*
import java.util.Scanner;
public class Homework2{
public static void main(String[] args){
Scanner s = new Scanner(System.in);
int num = s.nextInt();
printZhiShu(num);
}
public static void printZhiShu(int num){
while(!isZhiShu(++num)){
}
System.out.print("最小质数是"+num);
}
public static boolean isZhiShu(int num){
for(int i = 2; i < num;i++ ){
if(num%i==0){
return false;
}
}
return true;
}
}
*/
方法重载
同一个类中:方法名相同,形参个数或者类型不同。
优点:代码整齐美观,记忆方法名较少。
含义:就是可以定义多个相同名字的方法(例如:public static int sum(int a,int b)和public static int sum(long a,long b))
原理:Java编译器会自动识别方法名,若方法名相同,则进行参数类型匹配,所以名方法重载。
怎么判断:方法名相同、形参类型不同、形参个数不同、形参顺序不同
方法递归
含义:方法调用自己的方法!
典例:从前有座山,山里有个和尚说:{从前有座山,山里有个和尚说}:{从前有座山,山里有个和尚说}——递归。。。
老杜这样说:
方法递归?
1、什么是方法递归?
方法自己调用自己,这就是方法递归。
2、当递归时程序没有结束条件,一定会发生:
栈内存溢出错误:StackOverflowError
所以:递归必须要有结束条件。(这是一个非常重要的知识点。)
JVM发生错误之后一定会推出JVM。
3、递归假设是有结束条件的,就一定不会发生栈内存溢出吗?
假设这个结束条件时对的,是合法的,递归有时候也会出现栈内存溢出的错误。
因为有时候,可能递归的太深,栈内存不够(因为一直在压栈)
4、不建议在实际的开发中使用递归,,能用for循环while循环代替的尽量使用循环来做,因为循环的效率较高,耗费内存少。递归耗费的内存较多,另外递归若使用不当,则会导致JVM的死掉。
(极少数的情况下是必须要用递归的。)
所以:递归还是要认真学习的!
老杜讲经验:
如果遇到了栈内存溢出,怎么调bug?
第一步:
先检查递归的结束条件对不对。如果不对,则进一步修改,直到正确。
第二步:
如果假设条件没问题,这个时候需要手动调整JVM的栈内存初始大小(通过命令行适当调大。)
第三步:
如果还会栈内存溢出,则继续调大。(Java -X 这个命令可以查看调整堆栈大小的参数。具体格式如下图所示:)
老杜栈内存溢出图:
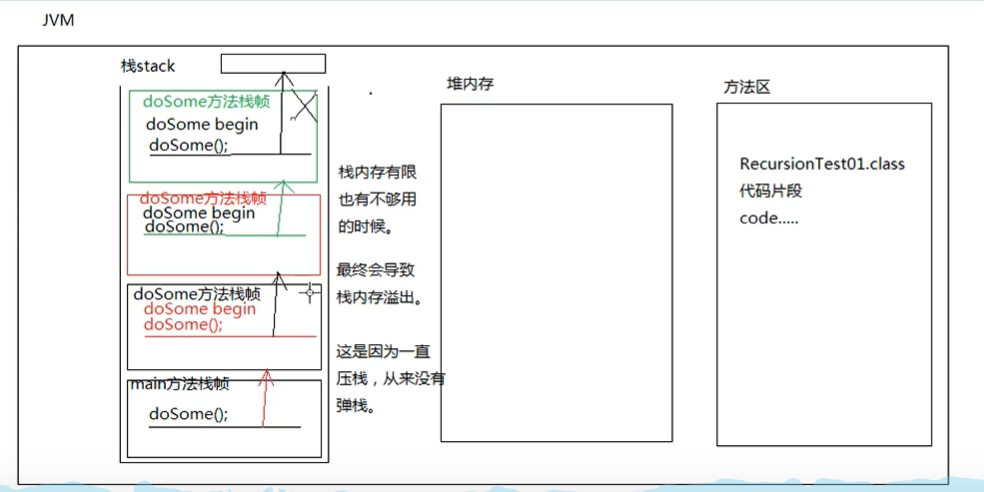
如何指 定栈内存大小:

递归实例
题目:计算1~ 10的和。
不用递归思路:写一个for循环方法,直接调用。
用递归思路:(方法调用打法)

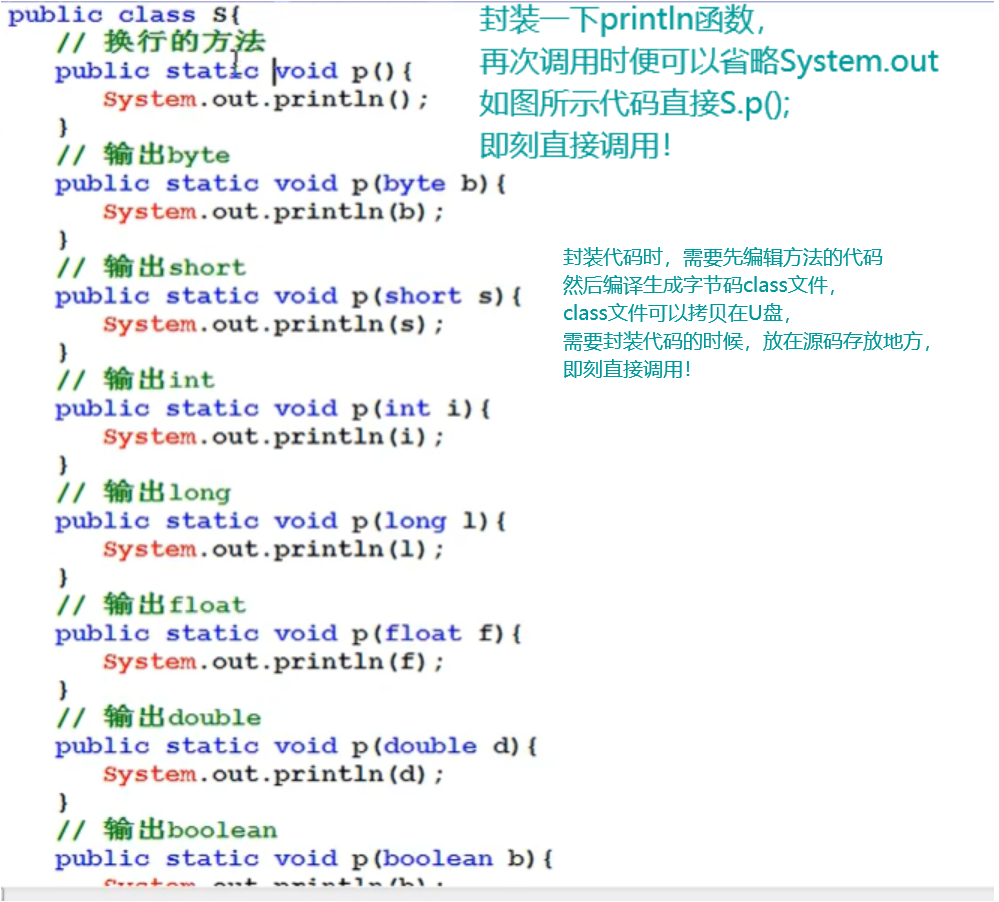
《代码的包装与封装》
封装及使用方法:
《认识面向对象》
面向对象与面向过程:
面向过程的优缺点:
缺点:(高度耦合)
面向过程的程序的每一个功能之间都是因果关系,因为A所以B,AB联合成一个子模块,然后模块与模块之间形成因果关系。因此任何一个功能之间出现问题,就会导致另一出现问题。 这就是高度耦合!(耦合度就是粘连程度)
耦合度高导致扩展力差(主板集成显卡)
耦合度低导致扩展力强(独立下显卡,螺栓与螺母等)
优点:(快速开发)
对于小型项目,可以直接通过因果关系来写代码。不需要前期对象的提取、模型的建立,可以直接干活,从而实现功能。
什么是面向对象的开发模式?
万物皆为对象,人眼看到的是各个对象之间的联系,更符合人类的思维方式。因此,面向对象在成为主流。
如何判断面向过程和面向对象?
可以通过耦合度等判断。
三个过程:
OOA–>OOD–>OOP
分析 设计 编程
三大特征:
封装、继承、多态。(任何一个面向对象的编程语言都包括这三个特征。)
类与对象
浅析类与对象:
类是一个集合,包含对象的特征,是特征的总结。
而对象是真实存在的,万物皆可对象。
在Java语言中,要想得到对象,必须先定义类,,,对象是通过类创建的。
例如:先定义人类,才可以定义魏磊。哈哈哈哈。
重要概念:
《实例化》
含义:通过类创建对象的过程叫做实例化。
《实例》
含义:对象又被称为实例。
(此处补充类与对象的图)
《抽象》
含义:魏磊到人类的过程程为抽象。
类–【实例化】–>对象(实例)
对象–【抽象】–>类
public class 明星类{
/*
类 = 属性 + 方法
属性来源于状态; (名词) 数据是以数据形式存在的,所以只能存放在变量中。 即属性即变量。
方法来源于动作; (动词)
*/
//属性
int 身高;
int 体重;
//方法
打篮球(){
}
学习(){
}
}
对象的创建:
“没对象,new一个”
创建对象语法:XueSheng s1 = new XueSheng();
XueSheng s1 = new XueSheng();此时此刻就相当于 :int i = 1;
XueSheng:数据类型
s1:变量名
new:运算符
XueSheng:类名
Java变量
变量的分类:
1局部变量
2成员变量
3静态变量
4常量 (要求大写)
Java进阶之路笔记
常用的48个关键字
沉默王二2021年10月22日
“二哥,就我之前学过的这些 Java 代码中,有 public、static、void、main 等等,它们应该都是关键字吧?”三妹的脸上泛着甜甜的笑容,我想她在学习 Java 方面已经变得越来越自信了。
“是的,三妹。Java 中的关键字可不少呢!你一下子可能记不了那么多,不过,先保留个印象吧,对以后的学习会很有帮助。”
PS:按照首字母的自然顺序排列。
- abstract: 用于声明抽象类,以及抽象方法。
- boolean: 用于将变量声明为布尔值类型,只有 true 和 false 两个值。
- break: 用于中断循环或 switch 语句。
- byte: 用于声明一个可以容纳 8 个比特的变量。
- case: 用于在 switch 语句中标记条件的值。
- catch: 用于捕获 try 语句中的异常。
- char: 用于声明一个可以容纳无符号 16 位比特的 Unicode 字符open in new window的变量。
- class: 用于声明一个类。
- continue: 用于继续下一个循环,可以在指定条件下跳过其余代码。
- default: 用于指定 switch 语句中除去 case 条件之外的默认代码块。
- do: 通常和 while 关键字配合使用,do 后紧跟循环体。
- double: 用于声明一个可以容纳 64 位浮点数的变量。
- else: 用于指示 if 语句中的备用分支。
- enum: 用于定义一组固定的常量(枚举)。
- extends: 用于指示一个类是从另一个类或接口继承的。
- final: 用于指示该变量是不可更改的。
- finally: 和
try-catch配合使用,表示无论是否处理异常,总是执行 finally 块中的代码。 - float: 用于声明一个可以容纳 32 位浮点数的变量。
- for: 用于声明一个 for 循环,如果循环次数是固定的,建议使用 for 循环。
- if: 用于指定条件,如果条件为真,则执行对应代码。
- implements: 用于实现接口。
- import: 用于导入对应的类或者接口。
- instanceof: 用于判断对象是否属于某个类型(class)。
- int: 用于声明一个可以容纳 32 位带符号的整数变量。
- interface: 用于声明接口。
- long: 用于声明一个可以容纳 64 位整数的变量。
- native: 用于指定一个方法是通过调用本机接口(非 Java)实现的。
- new: 用于创建一个新的对象。
- null: 如果一个变量是空的(什么引用也没有指向),就可以将它赋值为 null,和空指针异常息息相关。
- package: 用于声明类所在的包。
- private: 一个访问权限修饰符,表示方法或变量只对当前类可见。
- protected: 一个访问权限修饰符,表示方法或变量对同一包内的类和所有子类可见。
- public: 一个访问权限修饰符,除了可以声明方法和变量(所有类可见),还可以声明类。
main()方法必须声明为 public。 - return: 用于在代码执行完成后返回(一个值)。
- short: 用于声明一个可以容纳 16 位整数的变量。
- static: 表示该变量或方法是静态变量或静态方法。
- strictfp: 并不常见,通常用于修饰一个方法,确保方法体内的浮点数运算在每个平台上执行的结果相同。
- super: 可用于调用父类的方法或者字段。
- switch: 通常用于三个(以上)的条件判断。
- synchronized: 用于指定多线程代码中的同步方法、变量或者代码块。
- this: 可用于在方法或构造函数中引用当前对象。
- throw: 主动抛出异常。
- throws: 用于声明异常。
- transient: 修饰的字段不会被序列化。
- try: 于包裹要捕获异常的代码块。
- void: 用于指定方法没有返回值。
- volatile: 保证不同线程对它修饰的变量进行操作时的可见性,即一个线程修改了某个变量的值,新值对其他线程来说是立即可见的。
- while: 如果循环次数不固定,建议使用 while 循环。
关键字顺序排序:
byte<short(char)<int<long<float<doublepackage step2;
用户自定义方法
(tips:如果是静态方法,那么调用时就不用new关键字来创建对象来调用了)
当预先定义方法无法满足我们的要求时,就需要自定义一些方法,比如说,我们来定义这样一个方法,用来检查数字是偶数还是奇数。
public static void findEvenOdd(int num) {
if (num % 2 == 0) {
System.out.println(num + " 是偶数");
} else {
System.out.println(num + " 是奇数");
}
}
方法名叫做 findEvenOdd,访问权限修饰符是 public,并且是静态的(static),返回类型是 void,参数有一个整型(int)的 num。方法体中有一个 if else 语句,如果 num 可以被 2 整除,那么就打印这个数字是偶数,否则就打印这个数字是奇数。
方法被定义好后,如何被调用呢?
/**
* @author 微信搜「沉默王二」,回复关键字 PDF
*/
public class EvenOddDemo {
public static void main(String[] args) {
findEvenOdd(10);
findEvenOdd(11);
}
public static void findEvenOdd(int num) {
if (num % 2 == 0) {
System.out.println(num + " 是偶数");
} else {
System.out.println(num + " 是奇数");
}
}
}
main() 方法是程序的入口,并且是静态的,那么就可以直接调用同样是静态方法的 findEvenOdd()。
当一个方法被 static 关键字修饰时,它就是一个静态方法。换句话说,静态方法是属于类的,不属于类实例的(不需要通过 new 关键字创建对象来调用,直接通过类名就可以调用)。
访问权限控制
1.修饰类
- 默认访问权限(包访问权限):用来修饰类的话,表示该类只对同一个包中的其他类可见。
- public:用来修饰类的话,表示该类对其他所有的类都可见。
2.修饰类的方法和变量
- 默认访问权限(包访问权限):如果一个类的方法或变量被包访问权限修饰,也就意味着只能在同一个包中的其他类中显示地调用该类的方法或者变量,在不同包中的类中不能显式地调用该类的方法或变量。
- private:如果一个类的方法或者变量被 private 修饰,那么这个类的方法或者变量只能在该类本身中被访问,在类外以及其他类中都不能显式的进行访问。
- protected:如果一个类的方法或者变量被 protected 修饰,对于同一个包的类,这个类的方法或变量是可以被访问的。对于不同包的类,只有继承于该类的类才可以访问到该类的方法或者变量。
- public:被 public 修饰的方法或者变量,在任何地方都是可见的。
代码初始化块
三个规则:
- 类实例化的时候执行代码初始化块;
- 实际上,代码初始化块是放在构造方法中执行的,只不过比较靠前;
- 代码初始化块里的执行顺序是从前到后的。
补充:什么叫构造方法?有参?无参?
public class StudentDemo {
public static void main(String[] args) {
// 类名称 对象名 = new 类名称();
Student stu1 = new Student(); //无参构造方法执行
Student stu2 = new Student("张三",23); //全参构造方法执行
//赋值
stu1.setName("李四");
stu1.setAge(23);
//对象名.成员变量名;
System.out.println("姓名:"+stu1.getName()+",年龄:"+ stu1.getAge());
System.out.println("姓名:"+stu2.getName()+",年龄:"+ stu2.getAge());
}
}
方法的继承
关键字:extend,super(用于继承父类)
“在默认情况下,子类的构造方法在执行的时候会主动去调用父类的构造方法。也就是说,其实是构造方法先执行的,再执行的代码初始化块。”
知识拓展:
什么是@Overwide?
@Override是伪代码,表示重写(当然不写也可以),不过写上有如下好处:
1、可以当注释用,方便阅读;
2、编译器可以给你验证@Override下面的方法名是否是你父类中所有的,如果没有则报错。例如,你如果没写@Override,而你下面的方法名又写错了,这时你的编译器是可以编译通过的,因为编译器以为这个方法是你的子类中自己增加的方法。
举例:在重写父类的onCreate时,在方法前面加上@Override 系统可以帮你检查方法的正确性。
@Override
public void onCreate(Bundle savedInstanceState)
{…….}
这种写法是正确的,如果你写成:
@Override
public void oncreate(Bundle savedInstanceState)
{…….}
编译器会报如下错误:The method oncreate(Bundle) of type HelloWorld must override or implement a supertype method,以确保你正确重写onCreate方法(因为oncreate应该为onCreate)。而如果你不加@Override,则编译器将不会检测出错误,而是会认为你为子类定义了一个新方法:oncreate
抽象类
敲黑板知识点:
写在前面:
什么是抽象?抽象的含义?
抽象是不确定的、不具体的概念或事物。在Java中的抽象类,是指需要在子类中通过方法扩展来实现新的方法。
**关键字:**abstract
语句格式:
abstract class AbstractPlayer {
}
命名规则:
关于抽象类的命名,《阿里的 Java 开发手册》上有强调,“抽象类命名要使用 Abstract 或 Base 开头”,这条规约还是值得遵守的。
Tips:
抽象类是不能实例化的,尝试通过 new 关键字实例化的话,编译器会报错,提示“类是抽象的,不能实例化”。
虽然抽象类不能实例化,但可以有子类。子类通过 extends 关键字来继承抽象类。就像下面这样。
Demo code:
public class BasketballPlayer extends AbstractPlayer {
}
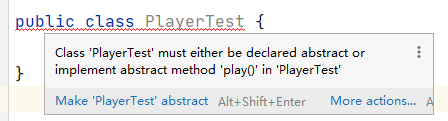
抽象的方法不能定义在普通类中。否则会在类和方法处出现两个报错。
错误提示。第一处在类级别上,提示“这个类必须通过 abstract 关键字定义”,见下图。
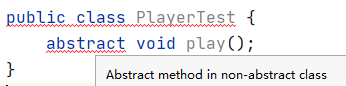
第二处在尝试定义 abstract 的方法上,提示“抽象方法所在的类不是抽象的”,见下图。
But,抽象类中既可以定义抽象方法、也可以普通方法。
抽象方法的应用场景
第一种场景。
当我们希望一些通用的功能被多个子类复用的时候,就可以使用抽象类。比如说,AbstractPlayer 抽象类中有一个普通的方法 sleep(),表明所有运动员都需要休息,那么这个方法就可以被子类复用。
Demo:
abstract class AbstractPlayer {
public void sleep() {
System.out.println("运动员也要休息而不是挑战极限");
}
}
子类 BasketballPlayer 继承了 AbstractPlayer 类:
class BasketballPlayer extends AbstractPlayer {
}
也就拥有了 sleep() 方法。BasketballPlayer 的对象可以直接调用父类的 sleep() 方法:
BasketballPlayer basketballPlayer = new BasketballPlayer();
basketballPlayer.sleep();
如此,就实现了代码的复用。
第二种场景。
当我们需要在抽象类中定义好 API,然后在子类中扩展实现的时候就可以使用抽象类。比如说,AbstractPlayer 抽象类中定义了一个抽象方法 play(),表明所有运动员都可以从事某项运动,但需要对应子类去扩展实现,表明篮球运动员打篮球,足球运动员踢足球。
知识拓展:
什么是API?
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。"
抽象类实例:
读取大小写helloworld:
https://tobebetterjavaer.com/oo/abstract.html
接口
关键字:
interface
语法格式:
public interface jiekou1
class A extends B implements jiekou1,jiekou2,jiekou3
小结论:
- 接口中允许定义变量
- 接口中允许定义抽象方法
- 接口中允许定义静态方法(Java 8 之后)
- 接口中允许定义默认方法(Java 8 之后)
除此之外,我们还应该知道:
1)接口不允许直接实例化,否则编译器会报错。
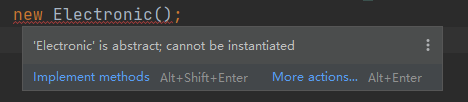
需要定义一个类去实现接口,见下例。
public class Computer implements Electronic {
public static void main(String[] args) {
new Computer();
}
@Override
public int getElectricityUse() {
return 0;
}
}
然后再实例化。
Electronic e = new Computer();
知识点拓展:
JAVA中extends 与implements有啥区别?
- 在类的声明中,通过关键字extends来创建一个类的子类。一个类通过关键字implements声明自己使用一个或者多个接口。
extends 是继承某个类, 继承之后可以使用父类的方法, 也可以重写父类的方法; implements 是实现多个接口, 接口的方法一般为空的, 必须重写才能使用 - extends是继承父类,只要那个类不是声明为final或者那个类定义为abstract的就能继承,JAVA中不支持多重继承,但是可以用接口 来实现,这样就要用到implements,继承只能继承一个类,但implements可以实现多个接口,用逗号分开就行了
比如
class A extends B implements C,D,E
(56条消息) Java之implements_小白study的博客-CSDN博客_implements
作业:多态与重载
构造与重载
抽象类与接口?
内部类
== = = = = = = 内部类(四种内部类详解)= = = = = = = ==
一、基本介绍:一个类的内部又完整的嵌套了另一个类结构。被嵌套的类称为内部类(inner class),嵌套其他类的类称为外部类(outer class)。是我们类的第五大成员【思考:类的五大成员是哪些?[属性、方法、构造器、代码块、内部类]】,内部类最大的特点就是可以直接访问私有属性,并且可以体现类与类之间的包含关系,注意:内部类是学习的难点,同时也是重点,后面看底层源码时,有大量的内部类.
如果定义类在局部位置(方法中/代码块) :(1) 局部内部类 (2) 匿名内部类
定义在成员位置 (1) 成员内部类 (2)静态内部类
在 Java 中,可以将一个类定义在另外一个类里面或者一个方法里面,这样的类叫做内部类。
二、基本语法
class Outer{ //外部类
class Inner{ //内部类
}
}
class Other{ //外部其他类
}
三、分类
一般来说,内部类分为成员内部类、局部内部类、匿名内部类和静态内部类。
定义在外部类的局部位置上(如方法内):
1)局部内部类(有类名)
2)匿名内部类(没有类名,重点!!!)
定义在外部类的成员位置上:
1)成员内部类(没用static修饰)
2)静态内部类(使用static修饰)
1.成员内部类:
成员内部类可以无限制访问外部类的所有成员属性。
内部类可以随心所欲地访问外部类的成员,但外部类想要访问内部类的成员,就不那么容易了,必须先创建一个成员内部类的对象,再通过这个对象来访问:
public class Wanger {
int age = 18;
private String name = "沉默王二";
static double money = 1;
public Wanger () {
new Wangxiaoer().print();
}
class Wangxiaoer {
int age = 81;
public void print() {
System.out.println(name);
System.out.println(money);
}
}
}
这种创建内部类的方式在实际开发中并不常用,因为内部类和外部类紧紧地绑定在一起,使用起来非常不便。
2.局部内部类
3.匿名内部类
4.静态内部类
第一,静态内部类不能访问外部类的所有成员变量;
第二,静态内部类可以访问外部类的所有静态变量,包括私有静态变量。
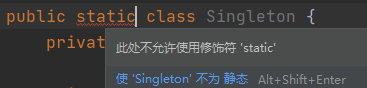
第三,外部类不能声明为 static。”
“三妹,你看,在 Singleton 类上加 static 后,编译器就提示错误了。”
总结
为什么要使用内部类?
在《Think in java》中有这样一句话:
使用内部类最吸引人的原因是:每个内部类都能独立地继承一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。
在我们程序设计中有时候会存在一些使用接口很难解决的问题,这个时候我们可以利用内部类提供的、可以继承多个具体的或者抽象的类的能力来解决这些程序设计问题。可以这样说,接口只是解决了部分问题,而内部类使得多重继承的解决方案变得更加完整。
使用内部类还能够为我们带来如下特性(摘自《Think in java》):
- 1、内部类可以使用多个实例,每个实例都有自己的状态信息,并且与其他外围对象的信息相互独立。
- 2、在单个外部类中,可以让多个内部类以不同的方式实现同一个接口,或者继承同一个类。
- 3、创建内部类对象的时刻并不依赖于外部类对象的创建。
- 4、内部类并没有令人迷惑的“is-a”关系,他就是一个独立的实体。
- 5、内部类提供了更好的封装,除了该外围类,其他类都不能访问。
关键字
1.static
static的作用
“static 关键字的作用可以用一句话来描述:‘方便在没有创建对象的情况下进行调用,包括变量和方法’。也就是说,只要类被加载了,就可以通过类名进行访问。”我扶了扶沉重眼镜,继续说到,“static 可以用来修饰类的成员变量,以及成员方法。我们一个个来看。”
demo:
public class Counter {
int count = 0;
Counter() {
count++;
System.out.println(count);
}
public static void main(String args[]) {
Counter c1 = new Counter();
Counter c2 = new Counter();
Counter c3 = new Counter();
}
}
/*
我们创建一个成员变量 count,并且在构造函数中让它自增。因为成员变量会在创建对象的时候获取内存,因此每一个对象都会有一个 count 的副本, count 的值并不会随着对象的增多而递增。
*/
public class StaticCounter {
static int count = 0;
StaticCounter() {
count++;
System.out.println(count);
}
public static void main(String args[]) {
StaticCounter c1 = new StaticCounter();
StaticCounter c2 = new StaticCounter();
StaticCounter c3 = new StaticCounter();
}
}
/*
简单解释一下哈,由于静态变量只会获取一次内存空间,所以任何对象对它的修改都会得到保留,所以每创建一个对象,count 的值就会加 1,所以最终的结果是 3,明白了吧?三妹。这就是静态变量和成员变量之间的差别。
*/
warnning:
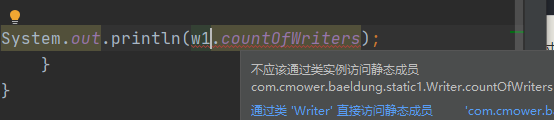
“另外,需要注意的是,由于静态变量属于一个类,所以不要通过对象引用来访问,而应该直接通过类名来访问,否则编译器会发出警告。”
static的特点:
- 静态方法属于这个类而不是这个类的对象;
(因为静态方法不用类的实例化,所以直接通过类来调用,不通过类的实例来调用,因此不应通过对象调用)
- 调用静态方法的时候不需要创建这个类的对象;
- 静态方法可以访问静态变量。
那么问题来了,为什么main方法是静态的,这就涉及到Java的编译器JVM了,为了代码简洁与方便调用,main函数作为程序的入口,所以设为静态更为合适。
二哥这么说:
“如果 main 方法不是静态的,就意味着 Java 虚拟机在执行的时候需要先创建一个对象才能调用 main 方法,而 main 方法作为程序的入口,创建一个额外的对象显得非常多余。”我不假思索的回答令三妹感到非常的钦佩。
“java.lang.Math 类的几乎所有方法都是静态的,可以直接通过类名来调用,不需要创建类的对象。”
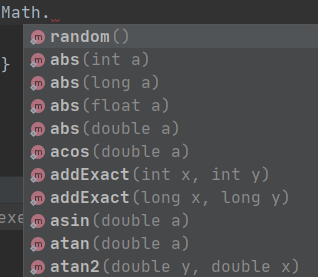
综上所述(由上可得):
一些函数基本上都是静态的。
静态代码块
“除了静态变量和静态方法,static 关键字还有一个重要的作用。”我心情愉悦地对三妹说,“用一个 static 关键字,外加一个大括号括起来的代码被称为静态代码块。”
“就像下面这串代码。”
public class StaticBlock {
static {
System.out.println("静态代码块");
}
public static void main(String[] args) {
System.out.println("main 方法");
}
}
“静态代码块通常用来初始化一些静态变量,它会优先于 main() 方法执行。”
2.this
this除了可以指向当前方法或者构造函数的对象,还可以完成以下工作:
- 调用当前类的方法;
this()可以调用当前类的构造方法;- this 可以作为参数在方法中传递;
- this 可以作为参数在构造方法中传递;
- this 可以作为方法的返回值,返回当前类的对象。
01、 指向当前对象
demo:
WithoutThisStudent(String name, int age) {
name = name;
age = age;
}
伪代码运行结果:
null 0
null 0
更改之后的demo:
WithThisStudent(String name, int age) {
this.name = name;
this.age = age;
}
运行正确√
02、调用当前类的方法
“我们可以在一个类中使用 this 关键字来调用另外一个方法,如果没有使用的话,编译器会自动帮我们加上。”我对自己深厚的编程功底充满自信,“在源代码中,method2() 在调用 method1() 的时候并没有使用 this 关键字,但通过反编译后的字节码可以看得到。”
03、调用当前类的构造方法
调用无参的constructor
public class InvokeConstrutor {
InvokeConstrutor() {
System.out.println("hello");
}
InvokeConstrutor(int count) {
this();
System.out.println(count);
}
public static void main(String[] args) {
InvokeConstrutor invokeConstrutor = new InvokeConstrutor(10);
}
}
“也可以在无参构造方法中使用 this() 并传递参数来调用有参构造方法。”话音没落,我就在键盘上敲了起来,“来看下面这段代码。”
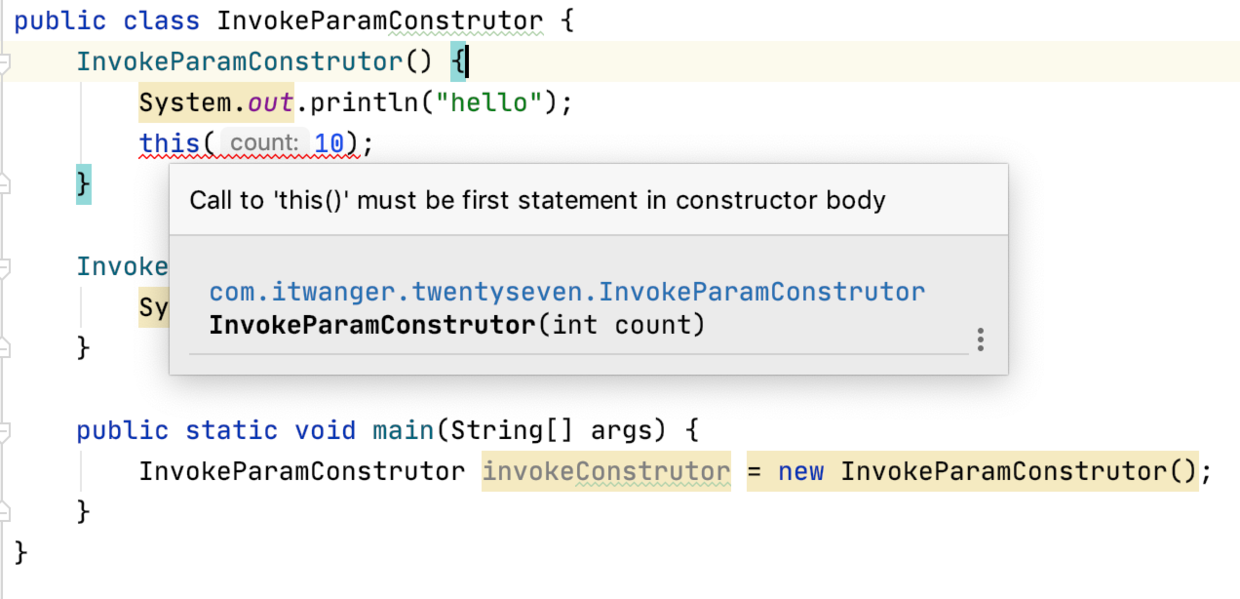
public class InvokeParamConstrutor {
InvokeParamConstrutor() {
this(10);
System.out.println("hello");
}
InvokeParamConstrutor(int count) {
System.out.println(count);
}
public static void main(String[] args) {
InvokeParamConstrutor invokeConstrutor = new InvokeParamConstrutor();
}
}
warning:
“不过,需要注意的是,this() 必须放在构造方法的第一行,否则就报错了。”
04、作为参数在方法中传递(没看懂
05、作为参数在构造方法中传递
06、作为方法的返回值
public class ThisAsMethodResult {
ThisAsMethodResult getThisAsMethodResult() {
return this;
}
void out() {
System.out.println("hello");
}
public static void main(String[] args) {
new ThisAsMethodResult().getThisAsMethodResult().out();
}
}
“getThisAsMethodResult() 方法返回了 this 关键字,指向的就是 new ThisAsMethodResult() 这个对象,所以可以紧接着调用 out() 方法——达到了链式调用的目的,这也是 this 关键字非常经典的一种用法。”
3.super
“super 关键字的用法主要有三种。”
- 指向父类对象;
- 调用父类的方法;
super()可以调用父类的构造方法。
4.final
什么是序列化?
序列化是什么意思呢?Java 的序列化是指,将对象转换成以字节序列的形式来表示,这些字节序中包含了对象的字段和方法。序列化后的对象可以被写到数据库、写到文件,也可用于网络传输。
“被 final 修饰的变量无法重新赋值。换句话说,final 变量一旦初始化,就无法更改。”
final类:
“如果一个类使用了 final 关键字修饰,那么它就无法被继承…”
“等等,哥,我知道,String 类就是一个 final 类。”还没等我说完,三妹就抢着说到。
“说得没毛病。”
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {}
⚠️⚠️⚠️:String 是 immutable 类(不可变对象)
“那三妹你知道为什么 String 类要设计成 final 吗?”
“这个还真不知道。”三妹的表情透露出这种无奈。
“原因大致有 3 个。”
- 为了实现字符串常量池的需要
- 为了线程安全的需要
- 为了 HashCode 的不可变性的需要
“想了解更详细的原因,可以一会看看我之前写的这篇文章。”
5.instanceof
语法格式:
(object) instanceof (type)
对象 类型
用意也非常简单,判断对象是否符合指定的类型,结果要么是 true,要么是 false。在反序列化的时候,instanceof 操作符还是蛮常用的,因为这时候我们不太确定对象属不属于指定的类型,如果不进行判断的话,就容易抛出 ClassCastException 异常。
Java 是一门面向对象的编程语言,也就意味着除了基本数据类型,所有的类都会隐式继承 Object 类。所以下面的结果肯定也会输出 true。
Thread thread = new Thread();
System.out.println(thread instanceof Object);
如何使用?
// 先判断类型
if (obj instanceof String) {
// 然后强制转换
String s = (String) obj;
// 然后才能使用
}
先用 instanceof 进行类型判断,然后再把 obj 强制转换成我们期望的类型再进行使用。
JDK 16 的时候,instanceof 模式匹配转了正,意味着使用 instanceof 的时候更便捷了。
if (obj instanceof String s) {
// 如果类型匹配 直接使用 s
}
不可变对象
01、什么是不可变类?
一个类的对象在通过构造方法创建后如果状态不会再被改变,那么它就是一个不可变(immutable)类。它的所有成员变量的赋值仅在构造方法中完成,不会提供任何 setter 方法供外部类去修改。
自从有了多线程,生产力就被无限地放大了,所有的程序员都爱它,因为强大的硬件能力被充分地利用了。但与此同时,所有的程序员都对它心生忌惮,因为一不小心,多线程就会把对象的状态变得混乱不堪。
引入关键字:synchronized(同步)
为了保护状态的原子性、可见性、有序性,我们程序员可以说是竭尽所能。其中,synchronized(同步)关键字是最简单最入门的一种解决方案。
假如说类是不可变的,那么对象的状态就也是不可变的。这样的话,每次修改对象的状态,就会产生一个新的对象供不同的线程使用,我们程序员就不必再担心并发问题了。
02、常见的不可变类
String类
为什么要将String类设置为不可变类?
原因如下:
1)常量池的需要
字符串常量池是 Java 堆内存中一个特殊的存储区域,当创建一个 String 对象时,假如此字符串在常量池中不存在,那么就创建一个;假如已经存,就不会再创建了,而是直接引用已经存在的对象。这样做能够减少 JVM 的内存开销,提高效率。
2)hashCode 的需要
因为字符串是不可变的,所以在它创建的时候,其 hashCode 就被缓存了,因此非常适合作为哈希值(比如说作为 HashMap 的键),多次调用只返回同一个值,来提高效率。
3)线程安全
就像之前说的那样,如果对象的状态是可变的,那么在多线程环境下,就很容易造成不可预期的结果。而 String 是不可变的,就可以在多个线程之间共享,不需要同步处理。
因此,当我们调用 String 类的任何方法(比如说 trim()、substring()、toLowerCase())时,总会返回一个新的对象,而不影响之前的值。
String cmower = "沉默王二,一枚有趣的
可变参数
泛型
什么是泛型
泛型:就是指在类定义时不会设置类中的属性或方法参数的具体类型,而是在类使用时(创建对象)再进行类型的定义。会在编译期检查类型是否错误。

类声明后的<>中这个T被称为类型参数,用于指代任意类型,实际上这个T只是个代表,写什么都可以。表示此时的value1,value2都是在类定义时没有明确类型,只有在使用时才告知编译器类型。出于规范,类型参数用单个的大写字母来代替,常见如下:
- T:代表任意类
- E:表示Element的意思,或是异常
- K:与V搭配使用
- V:与K搭配使用
以下内容来源于Java全栈体系:
通过泛型可以将不同数据类型的add()方法复用为一个方法:
eg:泛型add()方法:
private static <T extends Number> double add(T a, T b) {
System.out.println(a + "+" + b + "=" + (a.doubleValue() + b.doubleValue()));
return a.doubleValue() + b.doubleValue();
}
- 泛型中的类型在使用时指定,不需要强制类型转换(类型安全,编译器会检查类型)
看下这个例子:
List list = new ArrayList();
list.add("xxString");
list.add(100d);
list.add(new Person());
我们在使用上述list中,list中的元素都是Object类型(无法约束其中的类型),所以在取出集合元素时需要人为的强制类型转化到具体的目标类型,且很容易出现java.lang.ClassCastException异常。
引入泛型,它将提供类型的约束,提供编译前的检查:
List<String> list = new ArrayList<String>();
// list中只能放String, 不能放其它类型的元素
更多内容请见:
https://www.pdai.tech/md/java/basic/java-basic-x-generic.html
注解
直接开始上实例:
class A{
public void test() {
}
}
class B extends A{
/**
* 重载父类的test方法
*/
@Override
public void test() {
}
/**
* 被弃用的方法
*/
@Deprecated
public void oldMethod() {
}
/**
* 忽略告警
*
* @return
*/
@SuppressWarnings("rawtypes")
public List processList() {
List list = new ArrayList();
return list;
}
}
Java 1.5开始自带的标准注解,包括@Override、@Deprecated和@SuppressWarnings:
@Override:表示当前的方法定义将覆盖父类中的方法@Deprecated:表示代码被弃用,如果使用了被@Deprecated注解的代码则编译器将发出警告@SuppressWarnings:表示关闭编译器警告信息
枚举(enum)
定义:
“枚举(enum),是 Java 1.5 时引入的关键字,它表示一种特殊类型的类,继承自 java.lang.Enum。”
“我们来新建一个枚举 PlayerType。”
eg:
public enum PlayerType {
TENNIS,
FOOTBALL,
BASKETBALL
}
01 “既然枚举是一种特殊的类,那它其实是可以定义在一个类的内部的,这样它的作用域就可以限定于这个外部类中使用。”我说。
eg:
public class Player {
private PlayerType type;
public enum PlayerType {
TENNIS,
FOOTBALL,
BASKETBALL
}
public boolean isBasketballPlayer() {
return getType() == PlayerType.BASKETBALL;
}
public PlayerType getType() {
return type;
}
public void setType(PlayerType type) {
this.type = type;
}
}
02 由于枚举是 final 的,所以可以确保在 Java 虚拟机中仅有一个常量对象,基于这个原因,我们可以使用“==”运算符来比较两个枚举是否相等,参照 isBasketballPlayer() 方法。
03 “枚举还可用于 switch 语句,和基本数据类型的用法一致。”我说。
04 “如果枚举中需要包含更多信息的话,可以为其添加一些字段,比如下面示例中的 name,此时需要为枚举添加一个带参的构造方法,这样就可以在定义枚举时添加对应的名称了。”我继续说。
eg:
public enum PlayerType {
TENNIS("网球"),
FOOTBALL("足球"),
BASKETBALL("篮球");
private String name;
PlayerType(String name) {
this.name = name;
}
}
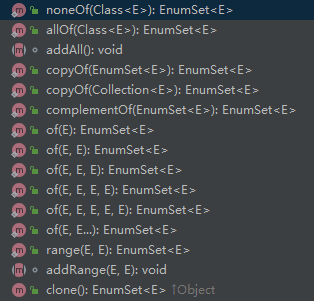
05 “EnumSet 是一个专门针对枚举类型的 Set 接口(后面会讲)的实现类,它是处理枚举类型数据的一把利器,非常高效。”我说,“从名字上就可以看得出,EnumSet 不仅和 Set 有关系,和枚举也有关系。”
06 “因为 EnumSet 是一个抽象类,所以创建 EnumSet 时不能使用 new 关键字。不过,EnumSet 提供了很多有用的静态工厂方法。”
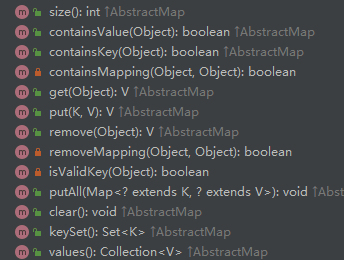
07 “除了 EnumSet,还有 EnumMap,是一个专门针对枚举类型的 Map 接口的实现类,它可以将枚举常量作为键来使用。EnumMap 的效率比 HashMap 还要高,可以直接通过数组下标(枚举的 ordinal 值)访问到元素。”
08 “和 EnumSet 不同,EnumMap 不是一个抽象类,所以创建 EnumMap 时可以使用 new 关键字。”
EnumMap<PlayerType, String> enumMap = new EnumMap<>(PlayerType.class);
09 有了 EnumMap 对象后就可以使用 Map 的一些方法了,见下图。
和 HashMap(后面会讲)的使用方法大致相同,来看下面的例子。
EnumMap<PlayerType, String> enumMap = new EnumMap<>(PlayerType.class);
enumMap.put(PlayerType.BASKETBALL,"篮球运动员");
enumMap.put(PlayerType.FOOTBALL,"足球运动员");
enumMap.put(PlayerType.TENNIS,"网球运动员");
System.out.println(enumMap);
System.out.println(enumMap.get(PlayerType.BASKETBALL));
System.out.println(enumMap.containsKey(PlayerType.BASKETBALL));
System.out.println(enumMap.remove(PlayerType.BASKETBALL));
“来看一下输出结果。”
{TENNIS=网球运动员, FOOTBALL=足球运动员, BASKETBALL=篮球运动员}
篮球运动员
true
篮球运动员
“除了以上这些,《Effective Java》这本书里还提到了一点,如果要实现单例的话,最好使用枚举的方式。”我说。
单例:。。。
反射
何为正射?何为反射?
“一般情况下,我们在使用某个类之前已经确定它到底是个什么类了,拿到手就直接可以使用 new 关键字来调用构造方法进行初始化,之后使用这个类的对象来进行操作。”
Writer writer = new Writer();
writer.setName("沉默王二");
像上面这个例子,就可以理解为“正射”。而反射就意味着一开始我们不知道要初始化的类到底是什么,也就没法直接使用 new 关键字创建对象了。
我们只知道这个类的一些基本信息,就好像我们看电影的时候,为了抓住一个犯罪嫌疑人,警察就会问一些目击证人,根据这些证人提供的信息,找专家把犯罪嫌疑人的样貌给画出来——这个过程,就可以称之为反射。
反射的缺点:
- 破坏封装:由于反射允许访问私有字段和私有方法,所以可能会破坏封装而导致安全问题。
- 性能开销:由于反射涉及到动态解析,因此无法执行 Java 虚拟机优化,再加上反射的写法的确要复杂得多,所以性能要比“正射”差很多,在一些性能敏感的程序中应该避免使用反射。
好处:
- 开发通用框架:像 Spring,为了保持通用性,通过配置文件来加载不同的对象,调用不同的方法。
- 动态代理:在面向切面编程中,需要拦截特定的方法,就会选择动态代理的方式,而动态代理的底层技术就是反射。
- 注解:注解本身只是起到一个标记符的作用,它需要利用发射机制,根据标记符去执行特定的行为。
详情参考:
集合框架(容器)
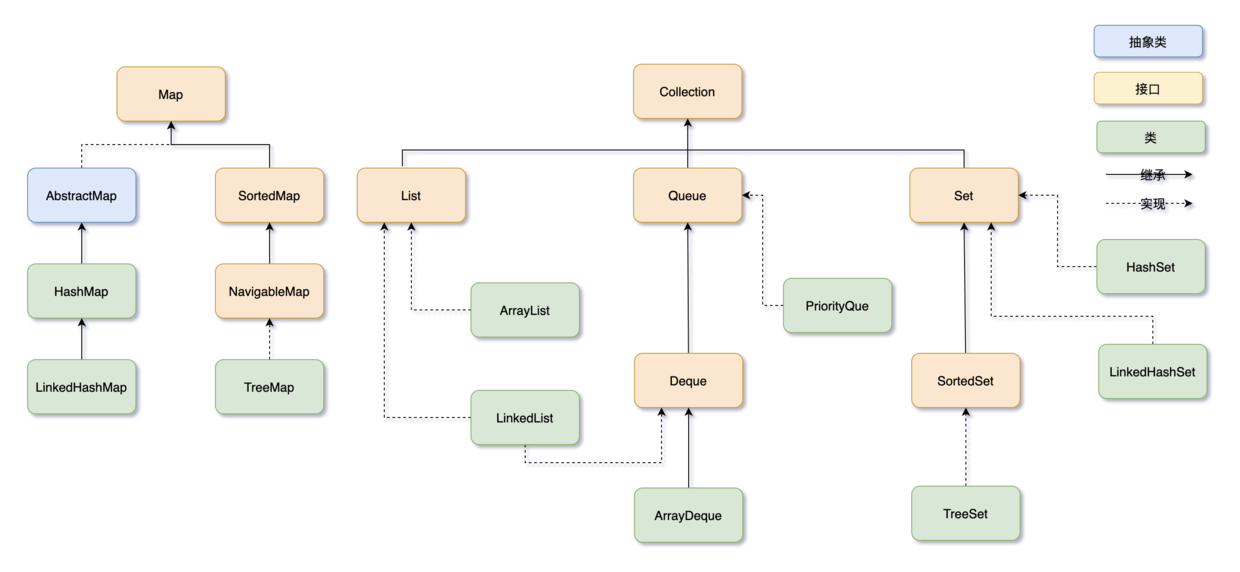
集合框架的结构图:
单词:
Collection——集合;
Map——图、表(两个类间的映射关系);
List——列举、列表;
Array——数组;
Arraylist——数组列表;
Linkedlist——链表;
Stack——栈; 执行效率较低
Vector——矩阵、模型 线程安全
Java 集合框架可以分为两条大的支线:
- Collection,主要由 List、Set、Queue 组成,List 代表有序、可重复的集合,典型代表就是封装了动态数组的 ArrayList 和封装了链表的 LinkedList;Set 代表无序、不可重复的集合,典型代表就是 HashSet 和 TreeSet;Queue 代表队列,典型代表就是双端队列 ArrayDeque,以及优先级队列 PriorityQue。
- Map,代表键值对的集合,典型代表就是 HashMap。
01、List
List 的特点是存取有序,可以存放重复的元素,可以用下标对元素进行操作
02、Set
说在前面:
Set 集合不是关注的重点,因为底层都是由 Map 实现的,为什么要用 Map 实现呢?
因为 Map 的键不允许重复、无序吗
Set 的特点是存取无序,不可以存放重复的元素,不可以用下标对元素进行操作,和 List 有很多不同
Set是Java中的集合类,提供了一种无顺序,不重复的集合。常用的子类包括HashSet, TreeSet等。
03、Queue
Queue,也就是队列,通常遵循先进先出(FIFO)的原则,新元素插入到队列的尾部,访问元素返回队列的头部。
04、Map
Map 保存的是键值对,键要求保持唯一性,值可以重复。
浅析ArrayList(动态数组)
arraylist是接口list的实现类,有很多方便调用的预定义方法,便于用户直接调用。
List接口常用方法:
1、add(Object element): 向列表的尾部添加指定的元素。
/*
List<String> alist = new ArrayList<>();
alist.add("沉默王二");
*/
2、size(): 返回列表中的元素个数。
3、get(int index): 返回列表中指定位置的元素,index从0开始。
4、add(int index, Object element): 在列表的指定位置插入指定元素。
5、set(int i, Object element): 将索引i位置元素替换为元素element并返回被替换的元素。
6、clear(): 从列表中移除所有元素。
7、isEmpty(): 判断列表是否包含元素,不包含元素则返回 true,否则返回false。
8、contains(Object o): 如果列表包含指定的元素,则返回 true。
9、remove(int index): 移除列表中指定位置的元素,并返回被删元素。
10、remove(Object o): 移除集合中第一次出现的指定元素,移除成功返回true,否则返回false。
11、iterator(): 返回按适当顺序在列表的元素上进行迭代的迭代器。
12、indexof():正序查找一个元素。倒叙查找为lastIndexOf()
ArrayList 可以称得上是集合框架方面最常用的类了,可以和 HashMap 一较高下。
ArrayList 在数组的基础上实现了自动扩容,并且提供了比数组更丰富的预定义方法(各种增删改查),非常灵活。
创建一个ArrayList的语法格式:
ArrayList<String> alist = new ArrayList<String>();//标准
/*可以通过上面的语句来创建一个字符串类型的 ArrayList(通过尖括号来限定 ArrayList 中元素的类型,如果尝试添加其他类型的元素,将会产生编译错误),更简化的写法如下:*/
List<String> alist = new ArrayList<>();
由于 ArrayList 实现了 List 接口,所以 alist 变量的类型可以是 List 类型;new 关键字声明后的尖括号中可以不再指定元素的类型,因为编译器可以通过前面尖括号中的类型进行智能推断。
如果非常确定 ArrayList 中元素的个数,在创建的时候还可以指定初始大小。
浅析linkedList(链表)
链表这门内功大致分为三个层次:
- 第一层叫做“单向链表”,我只有一个后指针,指向下一个数据;
- 第二层叫做“双向链表”,我有两个指针,后指针指向下一个数据,前指针指向上一个数据。
- 第三层叫做“二叉树”,把后指针去掉,换成左右指针。
创建一个LinkedList的语法格式:
LinkedList<String> list = new LinkedList();
1)招式一:增
可以调用 add 方法添加元素:
list.add("沉默王二");
list.add("沉默王三");
list.add("沉默王四");
add 方法内部其实调用的是 linkLast 方法:
public boolean add(E e) {
linkLast(e);
return true;
}
linkLast,顾名思义,就是在链表的尾部链接:
- 添加第一个元素的时候,first 和 last 都为 null。
- 然后新建一个节点 newNode,它的 prev 和 next 也为 null。
- 然后把 last 和 first 都赋值为 newNode。
此时还不能称之为链表,因为前后节点都是断裂的。
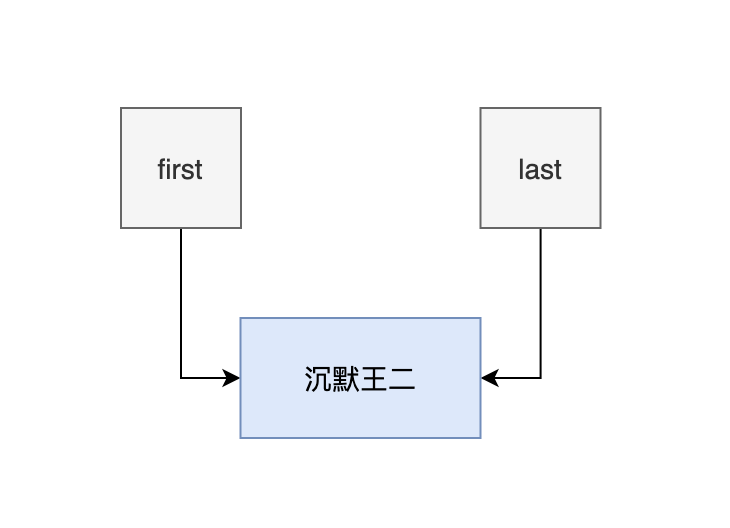
- 添加第二个元素的时候,first 和 last 都指向的是第一个节点。
- 然后新建一个节点 newNode,它的 prev 指向的是第一个节点,next 为 null。
- 然后把第一个节点的 next 赋值为 newNode。
此时的链表还不完整。
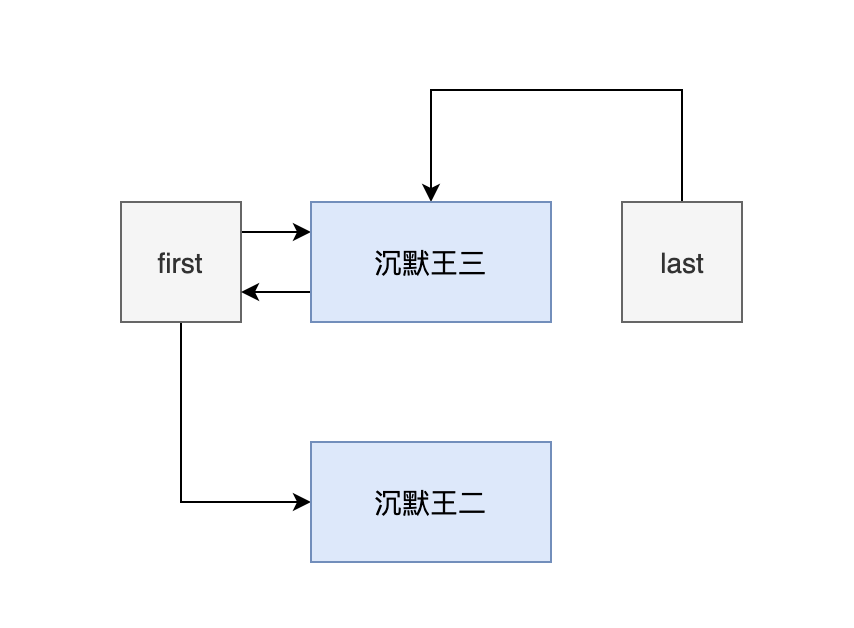
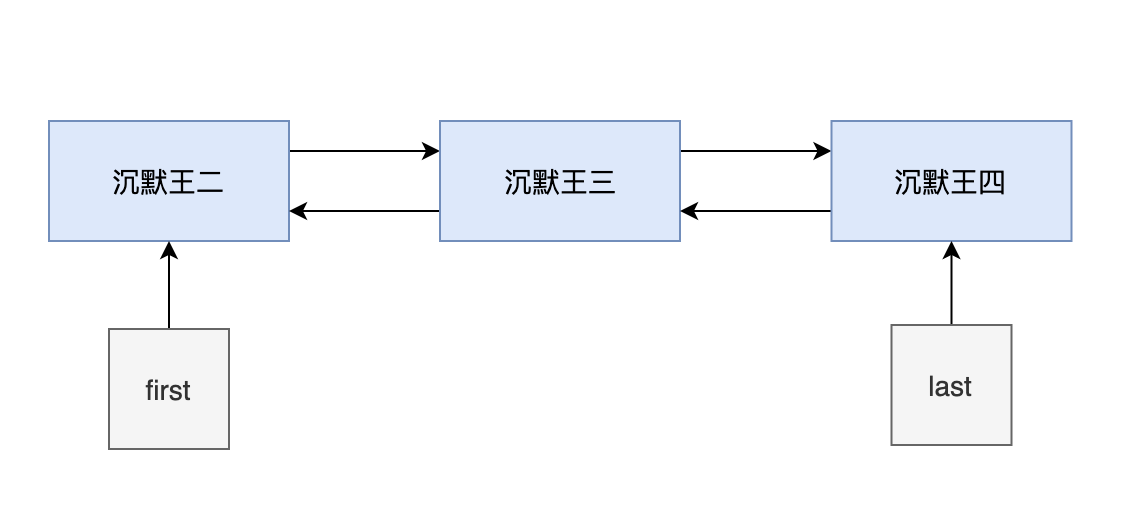
- 添加第三个元素的时候,first 指向的是第一个节点,last 指向的是最后一个节点。
- 然后新建一个节点 newNode,它的 prev 指向的是第二个节点,next 为 null。
- 然后把第二个节点的 next 赋值为 newNode。
此时的链表已经完整了。
我这个增的招式,还可以演化成另外两个:
addFirst()方法将元素添加到第一位;addLast()方法将元素添加到末尾。
addFirst 内部其实调用的是 linkFirst:
public void addFirst(E e) {
linkFirst(e);
}
linkFirst 负责把新的节点设为 first,并将新的 first 的 next 更
2)招式二:删
我这个删的招式还挺多的:
remove():删除第一个节点remove(int):删除指定位置的节点remove(Object):删除指定元素的节点removeFirst():删除第一个节点removeLast():删除最后一个节点
remove 内部调用的是 removeFirst,所以这两个招式的功效一样。
remove(int) 内部其实调用的是 unlink 方法。
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
新为之前的 first。
unlink 方法其实很好理解,就是更新当前节点的 next 和 prev,然后把当前节点上的元素设为 null。
3)招式三:改
可以调用 set() 方法来更新元素:
list.set(0, "沉默王五");
来看一下 set() 方法:
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
首先对指定的下标进行检查,看是否越界;然后根据下标查找原有的节点:
size >> 1:也就是右移一位,相当于除以 2。对于计算机来说,移位比除法运算效率更高,因为数据在计算机内部都是二进制存储的。
换句话说,node 方法会对下标进行一个初步判断,如果靠近前半截,就从下标 0 开始遍历;如果靠近后半截,就从末尾开始遍历。
找到指定下标的节点就简单了,直接把原有节点的元素替换成新的节点就 OK 了,prev 和 next 都不用改动。
4)招式四:查
我这个查的招式可以分为两种:
- indexOf(Object):查找某个元素所在的位置
- get(int):查找某个位置上的元素
indexOf 的内部分为两种,一种是元素为 null 的时候,必须使用 == 来判断;一种是元素为非 null 的时候,要使用 equals 来判断。因为 equals 是不能用来判 null 的,会抛出 NPE 错误。
get 方法的内核其实还是 node 方法,这个之前已经说明过了,这里略过。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
其实,查这个招式还可以演化为其他的一些,比如说:
getFirst()方法用于获取第一个元素;getLast()方法用于获取最后一个元素;poll()和pollFirst()方法用于删除并返回第一个元素(两个方法尽管名字不同,但方法体是完全相同的);pollLast()方法用于删除并返回最后一个元素;peekFirst()方法用于返回但不删除第一个元素。
虽然ArrayList经常喊LinkedList一声师弟,但二者之间其实挺和谐的。但我知道,在外人眼里,同门师兄弟,总要一较高下的。
比如说,我们俩在增删改查时候的时间复杂度。
ArrayList和LinkedList的区别
增删改查时候的时间复杂度。
由此,可以得出这样的结论:遍历 LinkedList 的时候,千万不要使用 for 循环,要使用迭代器。
Java中的Iterator和Iterable区别
Iterator:迭代器
Iterable:可迭代的
什么是迭代器?
迭代器 (iterator)有时又称 光标 (cursor)是**程序设计的 软件设计模式** ,可在容器对象(container,例如 链表 或 数组 )上遍访的接口,设计人员无需关心容器对象的内存分配的实现细节。
**中文名:** 迭代器
**外文名:** iterator
在 Java 中,我们对 List 进行遍历的时候,主要有这么三种方式。
第一种:for 循环。
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + ",");
}
第二种:迭代器。
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + ",");
}
第三种:for-each。
for (String str : list) {
System.out.print(str + ",");
}
fail-fast
官翻:
In systems design, a fail-fast system is one which immediately reports at its interface any condition that is likely to indicate a failure. Fail-fast systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed process. Such designs often check the system's state at several points in an operation, so any failures can be detected early. The responsibility of a fail-fast module is detecting errors, then letting the next-highest level of the system handle them.
fail-fast 是一种通用的系统设计思想,一旦检测到可能会发生错误,就立马抛出异常,程序将不再往下执行。——一种保护机制。
demo:
List<String> list = new ArrayList<>();
list.add("沉默王二");
list.add("沉默王三");
list.add("一个文章真特么有趣的程序员");
for (String str : list) {
if ("沉默王二".equals(str)) {
list.remove(str);
}
}
System.out.println(list);
这段代码看起来没有任何问题,但运行起来就报错了。

 那该如何正确地删除元素呢?
那该如何正确地删除元素呢?
1)remove 后 break
List<String> list = new ArrayList<>();
list.add("沉默王二");
list.add("沉默王三");
list.add("一个文章真特么有趣的程序员");
for (String str : list) {
if ("沉默王二".equals(str)) {
list.remove(str);
break;
}
}
break 后循环就不再遍历了,意味着 Iterator 的 next 方法不再执行了,也就意味着 checkForComodification 方法不再执行了,所以异常也就不会抛出了。
但是呢,当 List 中有重复元素要删除的时候,break 就不合适了。
3)使用 Iterator
List<String> list = new ArrayList<>();
list.add("沉默王二");
list.add("沉默王三");
list.add("一个文章真特么有趣的程序员");
Iterator<String> itr = list.iterator();
while (itr.hasNext()) {
String str = itr.next();
if ("沉默王二".equals(str)) {
itr.remove();
}
}
为什么使用 Iterator 的 remove 方法就可以避开 fail-fast 保护机制呢?看一下 remove 的源码就明白了。** 循环**
简单地总结一下,fail-fast 是一种保护机制,可以通过 for-each 循环删除集合的元素的方式验证这种保护机制。
那也就是说,for-each 本质上是一种语法糖,遍历集合时很方面,但并不适合拿来操作集合中的元素(增删)。
HashMap
什么是hashmap?
说在前面:
说到HashMap,就先说一下Map
map是用于存储键值对(<key,value>)的集合类,也可以说是一组键值对的映射(数学概念)。
Map的特点
1.没有重复的 key(一方面,key用set保存,所以key必须是唯一,无序的;另一方面,map的取值基本上是通过key来获取value,如果有两个相同的key,计算机将不知道到底获取哪个对应值;这时候有可能会问,那为什么我编程时候可以用put()方法传入两个key值相同的键值对?那是因为源码中,传入key值相同的键值对,将作为覆盖处理)
2.每个 key 只能对应一个 value, 多个 key 可以对应一个 value(这就是映射的概念,最经典的例子就是射箭,一排射手,一排箭靶,一个射手只能射中一个箭靶,而每个箭靶可能被不同射手射中。这里每个射手只有一根箭,不存在三箭齐发还都中靶这种骚操作。将射手和射中的靶子连线,这根线加射手加靶子就是一个映射)
3.key,value 都可以是任何引用类型(包括 null)的数据(只能是引用类型)
4.Map 取代了古老的 Dictionary 抽象类(知道就行,可以忽略)
————————————————
版权声明:本文为CSDN博主「酒吧七」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36711757/article/details/80394272
一、hash 方法的原理
把任意长度的输入(输入叫做预映射,知道就行),通过一种函数(hashCode() 方法),变换成固定长度的输出,该输出就是***\*哈希值\****(hashCode),这种函数就叫做***\*哈希函数\****,而计算哈希值的过程就叫做***\*哈希\****。哈希的主要应用是哈希表和分布式缓存。
这里有个问题,哈希算法和哈希函数不是一个东西,哈希函数是哈希算法的一种实现,以后面试就说哈希函数就行。
在将键值对存入数组之前,将key通过哈希算法计算出哈希值,把哈希值作为数组下标,把该下标对应的位置作为键值对的存储位置,通过该方法建立的数组就叫做***\*哈希表\****,而这个存储位置就叫做***\*桶(bucket)\****。数组是通过整数下标直接访问元素,哈希表是通过字符串key直接访问元素,也就说哈希表是一种特殊的数组(关联数组),哈希表广泛应用于实现数据的快速查找(在map的key[集合](https://so.csdn.net/so/search?q=集合&spm=1001.2101.3001.7020)中,一旦存储的key的数量特别多,那么在要查找某个key的时候就会变得很麻烦,数组中的key需要挨个比较,哈希的出现,使得这样的比较次数大大减少。)
哈希表选用哈希函数计算哈希值时,可能不同的 key 会得到相同的结果,一个地址怎么存放多个数据呢?这就是***\*哈希冲突(碰撞)\****。解决哈希冲突有两种方法,拉链法(链接法)和开放定址法(这种没用过)。***\*拉链法\****:将键值对对象封装为一个node结点,新增了next指向,这样就可以将碰撞的结点链接成一条单链表,保存在该地址(数组位置)中。
再来看一下 hash 方法的源码(JDK 8 中的 HashMap):
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
key.hashCode() 是用来获取键位的哈希值的,理论上,哈希值是一个 int 类型,范围从-2147483648 到 2147483648。前后加起来大概 40 亿的映射空间,只要哈希值映射得比较均匀松散,一般是不会出现哈希碰撞的。
取模运算有两处。
取模运算(“Modulo Operation”)和取余运算(“Remainder Operation ”)两个概念有重叠的部分但又不完全一致。主要的区别在于对负整数进行除法运算时操作不同。取模主要是用于计算机术语中,取余则更多是数学概念。
一处是往 HashMap 中 put 的时候(putVal 方法中):
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
}
一处是从 HashMap 中 get 的时候(getNode 方法中):
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {}
}
其中的 (n - 1) & hash 正是取模运算,就是把哈希值和(数组长度-1)做了一个“与”运算。
可能大家在疑惑:取模运算难道不该用 % 吗?为什么要用 & 呢?
这是因为 & 运算比 % 更加高效,并且当 b 为 2 的 n 次方时,存在下面这样一个公式。
a % b = a & (b-1)
用 2 n 2^n 2n 替换下 b 就是:
a % 2^n = a & (2^n-1)
综上所述,hash 方法是用来做哈希值优化的,把哈希值右移 16 位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。
说白了,hash 方法就是为了增加随机性,让数据元素更加均衡的分布,减少碰撞。
二、扩容机制
大家都知道,数组一旦初始化后大小就无法改变了,所以就有了 [ArrayList]这种“动态数组”,可以自动扩容。
HashMap 的底层用的也是数组。向 HashMap 里不停地添加元素,当数组无法装载更多元素时,就需要对数组进行扩容,以便装入更多的元素。
当然了,数组是无法自动扩容的,所以如果要扩容的话,就需要新建一个大的数组,然后把小数组的元素复制过去。
HashMap 的扩容是通过 resize 方法来实现的,JDK 8 中融入了红黑树,比较复杂,为了便于理解,就还使用 JDK 7 的源码,搞清楚了 JDK 7 的,我们后面再详细说明 JDK 8 和 JDK 7 之间的区别。
三、加载因子为什么是0.75
哈希函数计算结果越分散均匀,哈希碰撞的概率就越小,map的存取效率(时间复杂度)就会越高。
哈希表长度越长,空间成本越大,哈希函数计算结果越分散均匀。
*扩容机制*(实际上就是负载因子)和哈希函数越合理,空间成本越小,哈希函数计算结果越分散均匀。
从HashMap的默认构造函数源码可知,构造函数就是对下面几个字段进行初始化。
负载因子越大(长度一定),最大结点容量越大,resize次数越少,空间成本越小,map的存取效率就会越高。
桶数组初始容量(长度)越大(加载因子一定),最大结点容量越大,resize次数越少,空间成本越大,map的存取效率就会越高。
涉及到概率论的泊松分布与二项分布。
引入红黑树的概念:
这里存在一个问题,即使负载因子和哈希函数设计的再合理,也免不了会出现****拉链过长****(桶内结点过多)的情况,一旦出现拉链过长,则会严重影响HashMap的性能。于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能。
四、线程不安全
有何体现:
多线程下扩容会死循环、多线程下 put 会导致元素丢失、put 和 get 并发时会导致 get 到 null,也就是环链死循环、数据丢失、数据覆盖三个问题。其中环链在JDK1.8已经解决,但还是有数据覆盖的问题。
究其根本:
线程不安全主要是发生在扩容函数中,即根源是在transfer函数中:transfer函数代码如下:
/**
*
@version JDK1.7
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
HashMap的扩容操作,重新定位每个桶的下标,并采用头插法将元素迁移到新数组中。头插法会将链表的顺序翻转,这也是形成死循环的关键点。
key 用 Set 存放,所以想做到 key 不允许重复,key 对应的类(一般是String)需要重写 hashCode 和 equals 方法
- HashMap不是同步,HashTable是同步的,但HashTable已经弃用,如果需要线程安全,可以用synchronizedMap,例如 Map m = Collections.synchronizedMap(new HashMap(…));

















 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











