






重要提示,严正声明:注意法律和网站的使用条款,拒绝违法违规操作。仅作学习研究使用。
前提:已经安装好相关软件或服务
【我的是win10系统; Python3.8;Anaconda Navigator;jupyter Notebook...】
【也可以用PyCharm或VSCode,但我没试过】
技术说明:
1.Requests库:用于发送HTTP请求,获取网页内容
2.BeautifulSoup库:用于解析HTML,提取所需数据
步骤:
1 打开 Anaconda,点 jupyter Notebook 下面的 Launch ,进入jupyter的浏览器 文件夹(第三张图)【一般会自动弹出】
可以为爬虫项目单独创建一个环境 Environments (第二张图中),避免版本库冲突。【但我没整这个】

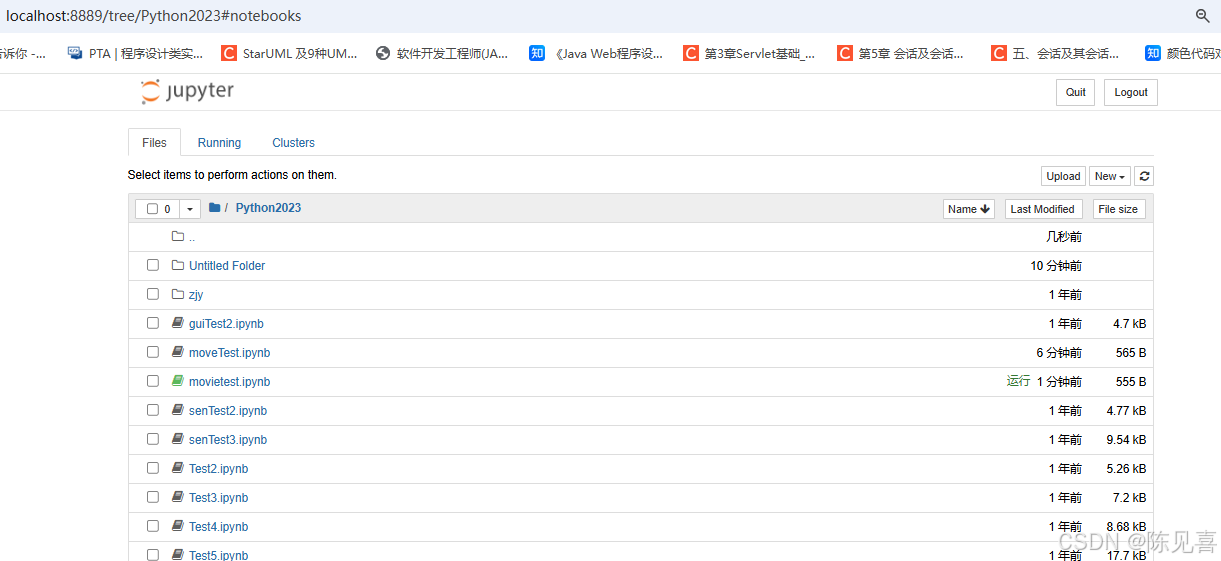
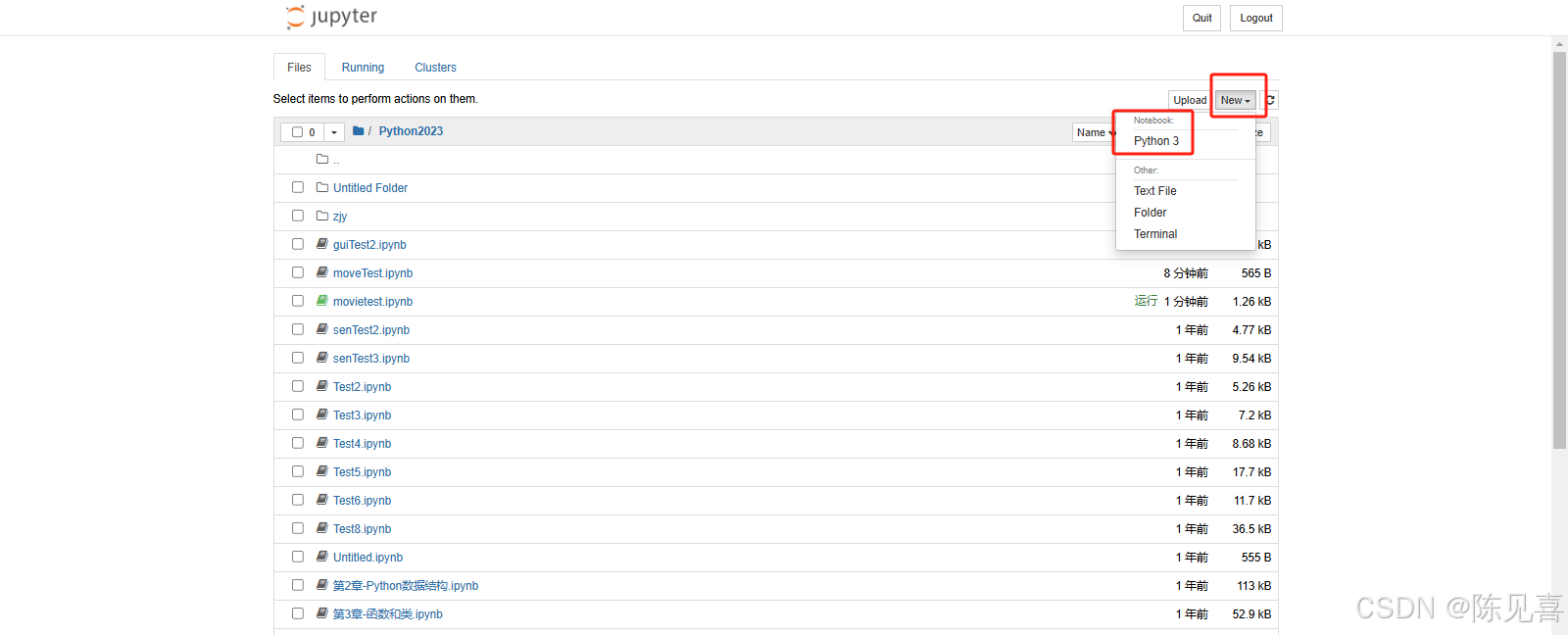
2 在浏览器右侧---New---下拉框中选择你的环境,新建一个Notebook
点击后会出现如下界面,可以直接将untitled 改名,在单元格中编写代码
3 (最终代码在图后)代码写好后,点 三角运行,查看结果,正确运行后下面会出现新的一条单元格
【我第一遍运行失败了,报错IndentationError(缩进错误),
原因:Python的import语句属于 模块级代码 ,必须写在 全局作用域 ,即不缩进
解决方法就是检查代码,如果使用的是代码编辑器,如VSCode,可以使用它的格式化代码功能,自动修正缩进】
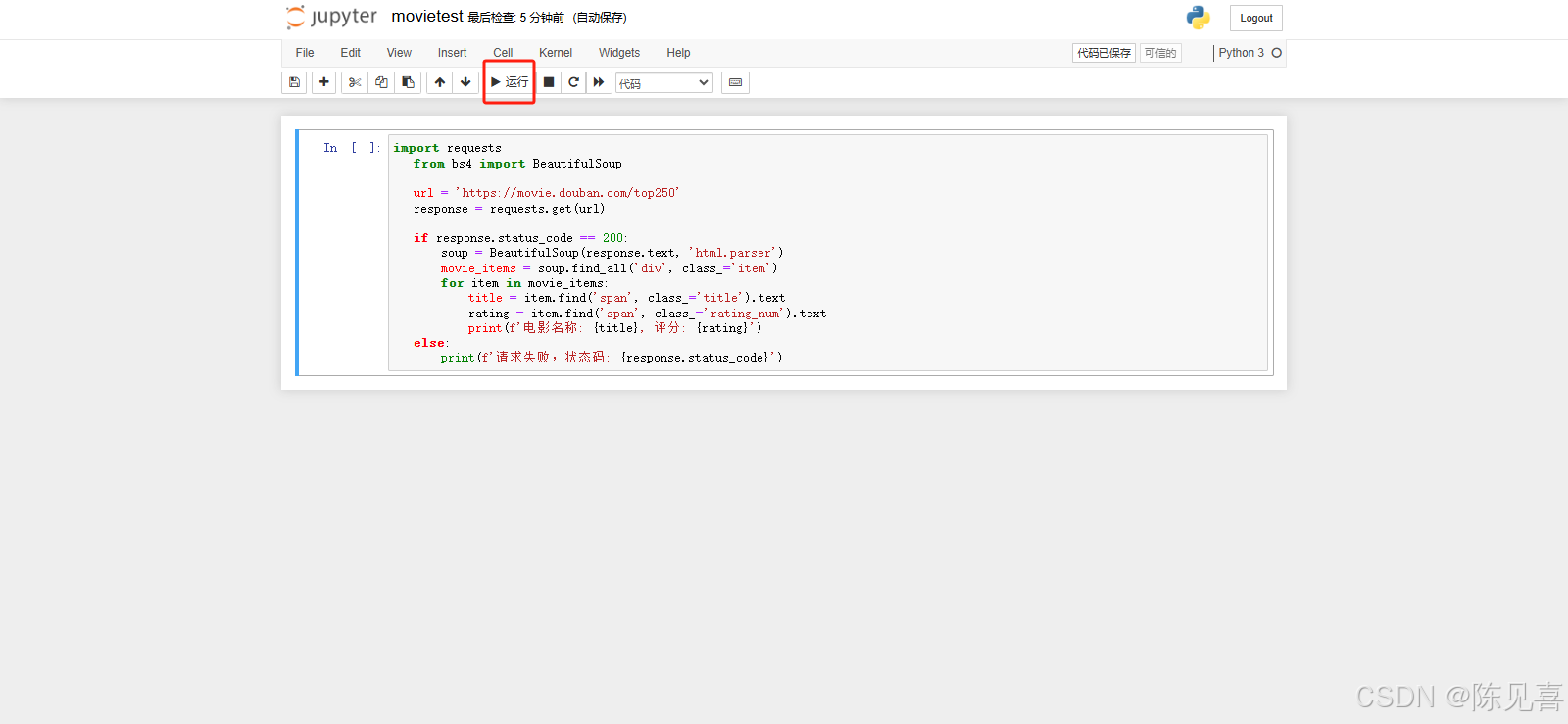
正确运行后,结果如下
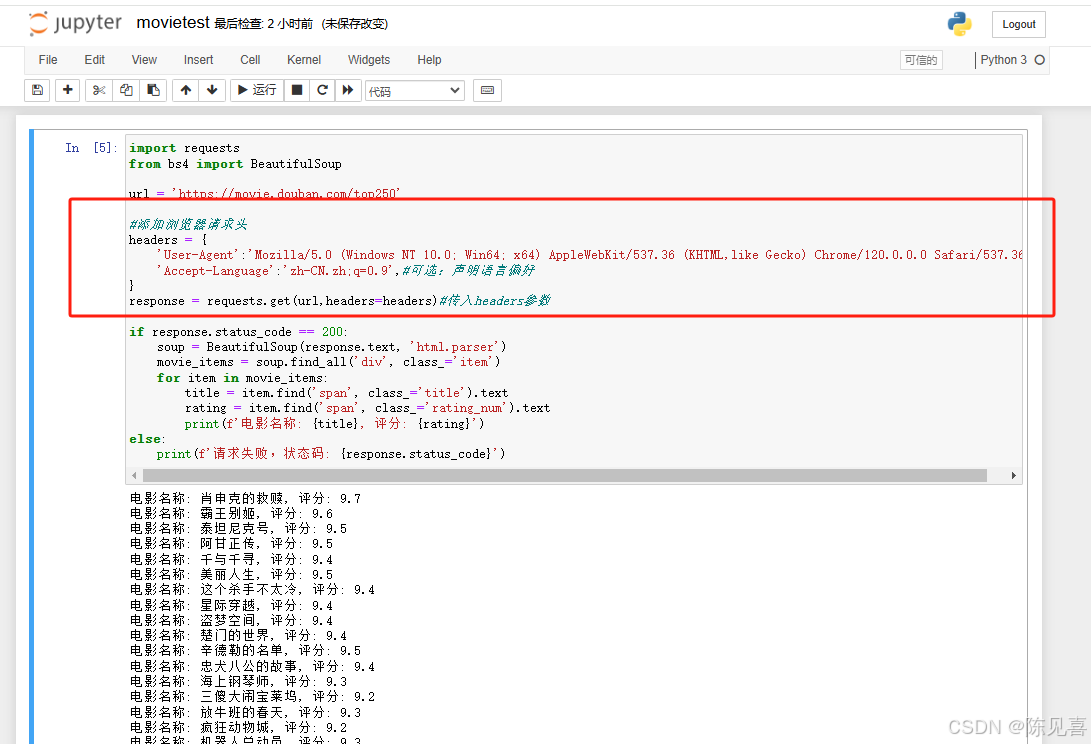
最终代码:
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/top250'
#添加浏览器请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language':'zh-CN.zh;q=0.9',#可选:声明语言偏好
}
response = requests.get(url,headers=headers)#传入headers参数if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
movie_items = soup.find_all('div', class_='item')
for item in movie_items:
title = item.find('span', class_='title').text
rating = item.find('span', class_='rating_num').text
print(f'电影名称: {title}, 评分: {rating}')
else:
print(f'请求失败,状态码: {response.status_code}')
另:问题及解决
我的第二遍运行:请求失败 418,这个表示 服务器识别到我们的请求是爬虫行为并拒绝响应
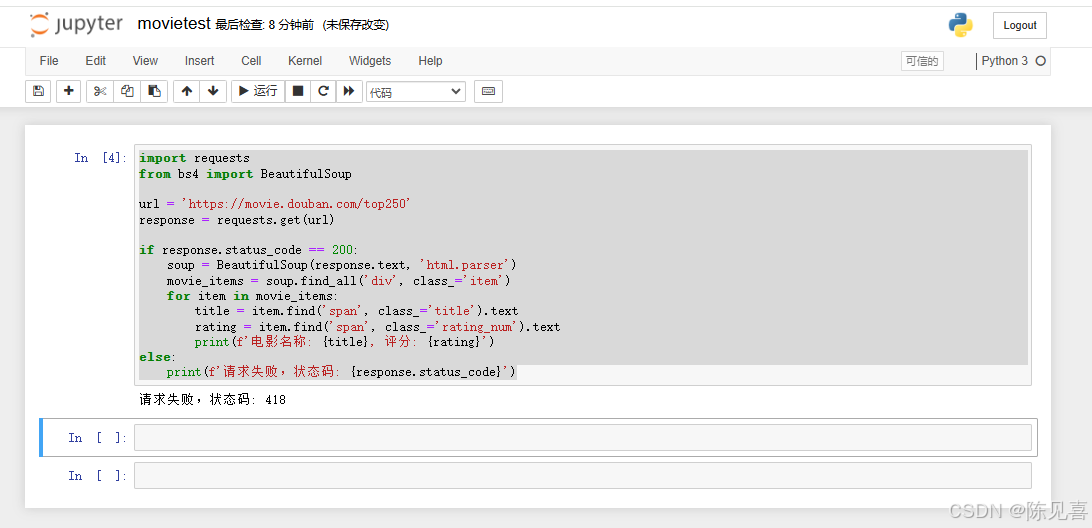
解决方法:
1.添加请求头(User-Agent)【我只试了这个方法,别的没试,不知道能不能行】
#添加浏览器请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language':'zh-CN.zh;q=0.9',#可选:声明语言偏好
}
response = requests.get(url,headers=headers)#传入headers参数
2.使用Session保持会话
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/top250'
# 创建 Session 对象并设置请求头
session = requests.Session()
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
})response = session.get(url) # 使用 session 发送请求
# 后续解析代码...
3.降低请求频率,添加随机延迟模拟人类操作
import time
import random# 每次请求后随机暂停 2~5 秒
time.sleep(random.uniform(2, 5))
4.处理动态Cookies或Token
部分网站会验证动态参数,需通过开发者工具(F12)手动提取
具体做法:
1)浏览器访问目标页面
2)按F12----NetWork,刷新页面
3)找到目标请求,复制请求头中的Cookie字段
4)将Cookie添加到代码中
headers = {
'User-Agent': '...',
'Cookie': '你的 Cookie 字符串', # 粘贴复制的 Cookie
}
5.使用代理IP
若IP被封禁,可通过代理服务器发送请求
proxies = {
'http': 'http://10.10.1.10:3128', # 替换为可用代理
'https': 'http://10.10.1.10:1080',
}response = requests.get(url, headers=headers, proxies=proxies)
6.模拟浏览器(Seleninum)
若以上方法均无效,可使用Seleninum控制真是浏览器绕过反爬
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from bs4 import BeautifulSoup# 配置 Chrome 驱动
service = Service('路径/chromedriver.exe') # 需下载对应驱动
driver = webdriver.Chrome(service=service)driver.get('https://movie.douban.com/top250')
soup = BeautifulSoup(driver.page_source, 'html.parser')# 解析代码...
driver.quit() # 关闭浏览器
注意事项:
发爬虫问题:确保爬虫行为符合网站robots.txt规则,避免法律风险。
代码执行顺序:jupyter单元格按顺序执行
ModuleNotFoundError 依赖库缺失:正确安装requests 和beautifulsoup4。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











