






目录
三、查看运行中的进程/任务、CPU、内存等的统计信息------pidstat
一、mpstat 命令描述
mpstat (multiprocessor state) 可以查看所有cpu的平均负载,也可以查看指定cpu的负载。所以mpstat其实就是主要查看CPU负载的一个工具。是一款常用的多核CPU性能分析工具,用来实时查询每个CPU的性能指标,以及所有CPU的平均指标。
1. 下载mpstat 的软件包
这个命令Linux缺省没有安装,它是Linux性能工具集sysstat中的一个工具,所以我们要装上sysstat,安装方法随不同的系统略有不同
sysstat是一个软件包,包含监测系统性能及效率的一组工具,这些工具对于我们收集系统性能数据,比如:CPU 使用率、硬盘和网络吞吐数据,这些数据的收集和分析,有利于我们判断系统是否正常运行。
centos 系统的安装方法

2、mpstat 的语法格式
mpstat 的语法:
mpstat [-p {ALL}] [ internal [count] ]
2.1 mpstat 命令参数:
p: 指定要吉安空哪个CPU,范围是【0~n~1】,ALL表示监控,所有CPU都监控
internal :相邻两次采样的间隔时间
Count:采样的次数
示例:
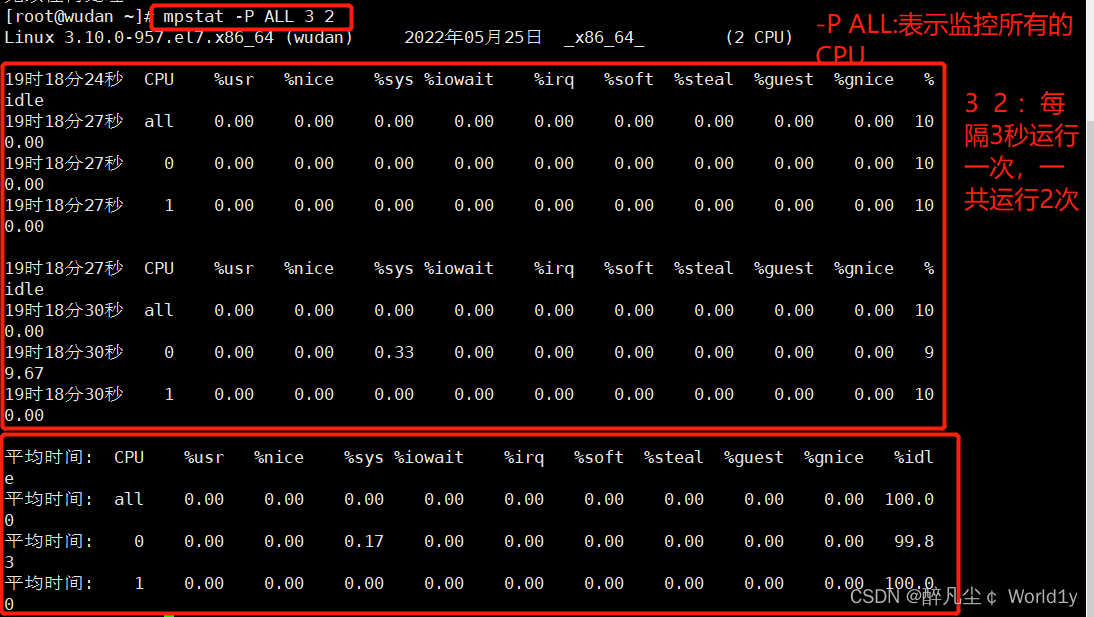
其中:
第一部分:输出首先显示了所有CPU的合计指标,然后显示了每个CPU各项的指标。
第二部分:在结尾处显示所有CPU的平均值
3、mpstat 命令的各列含义

| 显示参数 | 描述 |
| CPU | 显示的是某个CPU还是全部CPU all=全部 |
| %usr | 表示用户所有使用的CPU百分比 |
| %nice | 表示使用nice 值的cpu 的百分比 |
| %sys | 表示内核进程使用的cpu 百分比 |
| %iowait | 表示等待进行I/O 所使用的cpu时间百分比 |
| %irp | 表示用于处理系统终端的cpu百分比 |
| %soft | 表示用于软件中断的cpu百分比 |
| %steal | 虚拟机强制cpu 等待的时间百分比 |
| %guest | 虚拟机占用cpu 时间的百分比 |
| %gnice | cpu 运行niced guest 虚拟机所花费的时间百分比 |
| %idle | cpu 的空闲时间的百分比 |
mpstat主要用在当系统变慢,平均负载增大时,我们想判断到底是CPU的使用率增大了,还是IO压力增大的情况。
4、平均负载信息
当系统变慢,用top 或uptime 来了解系统的负载情况
系统平均负载是指在特定时间间隔内运行队列中的平均进程数
如果单个CPU内核的当前活动进程数不大于3的话,那么系统的性能是良好的

二、压力测试工具 stress
1、工具简介
stress是Linux下的一个压力测试工具,可以对cpu、memory(内存)、IO以及磁盘进行压力测试,可以指定负载的cpu个数
2、参数详解
-c : --cpu 产生n个进程,每个进程都反复不停的计算随机数的平方根
-i : --io 产生n个进程,每个进程反复调用 将内存上的内容写到硬盘上
-m :-vm 产生n个进程,每个进程不断分配和释放内存
-t : --timout 在n秒后结束进程
-d : --hadd 产生n个不断执行 write 和unlink函数的进程(创建文件、写入内容、删除文件)
3、 下载压力压力工具软件包
yum install -y epel-release 注:需要先下载所需要的依赖包否则直接下载stress软件包工具不成功

下载压力测试工具
yum install -y stress
三、查看运行中的进程/任务、CPU、内存等的统计信息------pidstat
1、 命令介绍
pidstat是sysstat工具中的一个命令,用于监控进程的cpu、内存、线程、IO及上下文切换等系统资源的占用情况。
2、格式
pidstat [ options ] [ <interval> [ <count> ] ]
分别是 选项 时间间隔 采集次数
3、常用参数
| -u | 默认的参数,显示各个进程的CPU使用统计 |
| -r | 显示各个进程的内存使用统计 |
| -d | 显示各个进程的IO使用情况 |
| -p | 指定进程号 |
| -w | 显示每个进程的上下文切换情况 |
| -t | 显示选择任务的线程的统计信息外的额外信息 |
| -V | 版本号 |
| -h | 在一行上显示了所有活动,这样其他程序可以容易解析 |
| -L | 在SMP环境,表示任务的CPU使用率/内核数量 |
| -l | 显示命令名和所有参数 |
4、输出信息含义
pidstat -u 查看本机全部进程的CPU使用情况
pidstat -u -p [PID] 2 3 每两秒输出一次进程号为PID的进程CPU使用情况,输出3次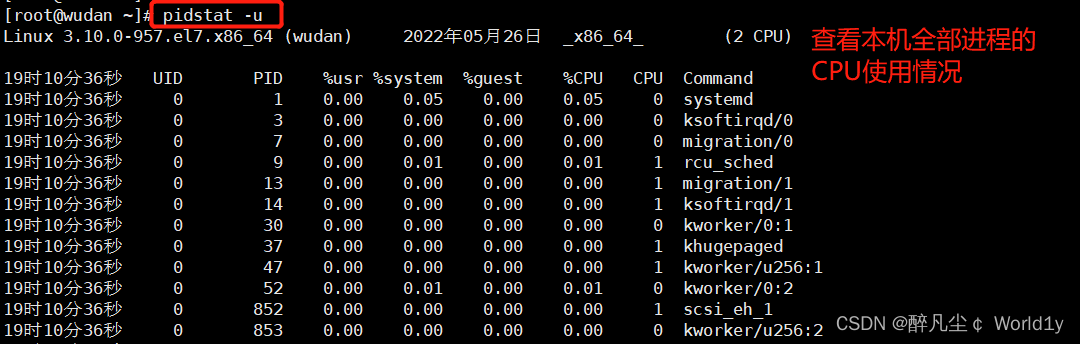
• UID:用户id
• PID:进程id
• %user:表示用户进程所使用cpu的百分比
• %system:表示内核进程所使用cpu的百分比
• %guest:表示运行CPU时所消耗的cpu时间百分比
• %wait:表示任务在等待运行时花费的cpu的百分比。
• %CPU:表示进程所使用cpu的百分比
• CPU:处理进程的cpu编号
• Command:进程对应的命令
注:运行pidstat不加任何选项,统计的信息为系统启动开始的各项统计信息
(1)使用-r选项统计进程内存使用情况
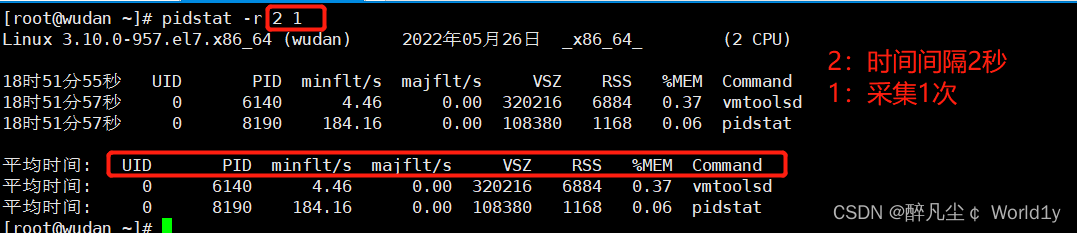
• minflt/s:从内存中加载数据时每秒出现的次要错误的数目,这些不要求从磁盘载入内存页面
• majflt/s:从内存中加载数据时每秒出现的主要错误的数目,这些要求从磁盘载入内存页面,一般在内存使用紧张时产生。
• VSZ:占用的虚拟内存大小,包括进入交换分区的内存
• RSS:占用的物理内存大小,不包括进入交换分区的内存
• %MEM:进程使用的物理内存百分比(2)使用-d选项统计进程IO使用情况

• kB_rd/s:进程每秒从磁盘读取的数据量(以kB为单位)
• kB_wr/s:进程每秒向磁盘写入的数据量(以kB为单位)
• kB_ccwr/s:任务写入磁盘被取消的速率(以kB为单位)
• iodelay:任务的I/O阻塞延迟,以时钟周期为单位,包括等待同步块 I/O 和换入块 I/O 结束的时间
(3)使用-w选项显示进程的上下文切换情况
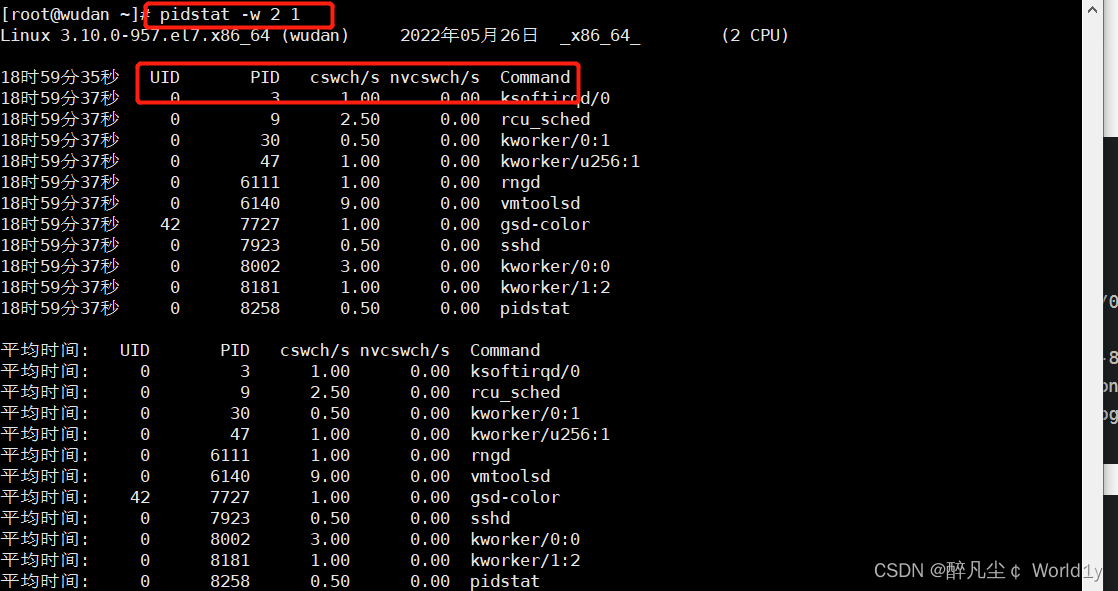
• cswch/s :表示每秒自愿上下文切换的次数
• nvcswch/s :表示每秒非自愿上下文切换的次数
注:所谓自愿上下文切换,是指进程无法获得所需的资源导致的上下文切换。
而非自愿上下文切换,则是指进程由于cpu分配的时间片耗尽,被系统强制调度导致的上下文切换
(4)使用-t和-p选项显示指定进程的线程
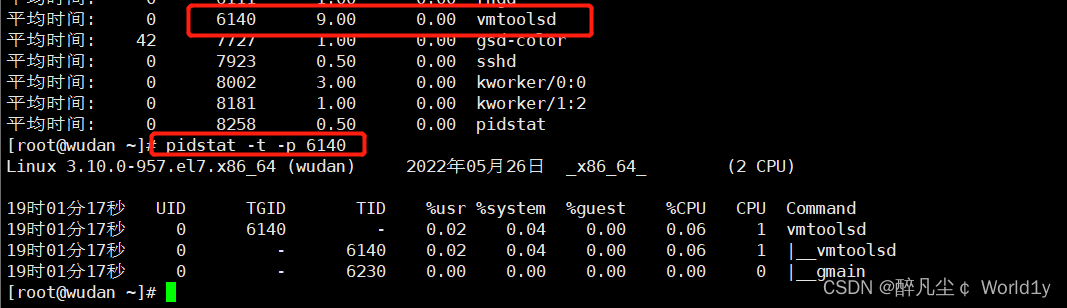
• TGID:主线程id
• TID: 线程id
(5)使用-C选项显示符合匹配的进程

四:实验
1、实验目的
采用stress压力测试工具,模拟CPU 负载的情况,高IO的情况,使用uptime查看平均负载,使用mpstat和pidstat工具,找出负载高的根源。
查看系统平均负载情况uptime
初始信息负载情况

2、压力测试查看CPU的使用率
模拟cpu 负载
压力测试前,cpu的使用率
使用stress工具进行压力测试
stress --cpu 2 --timeout 600
进行压力测试 对2快cpu 进行增压 持续600s

产生压力后的信息:显示用户进程 stress对cpu的使用率为100% cpu占用率过高,cpu负载
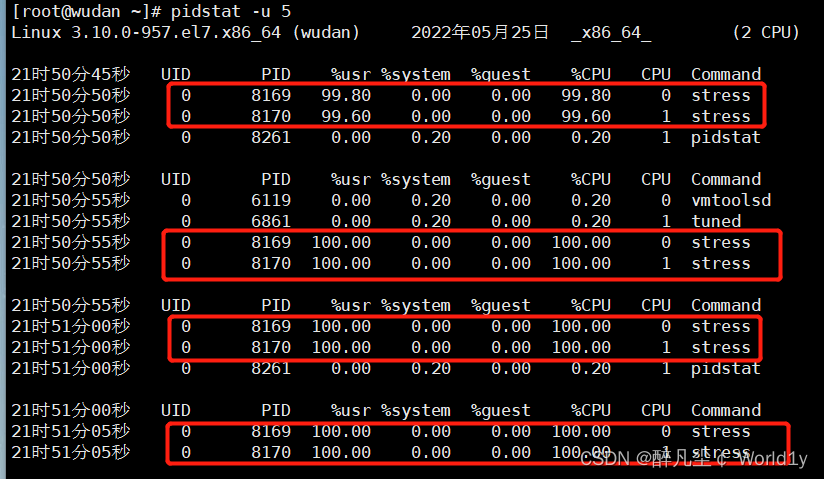
pidstat -u 5 查看运行中的进程和任务,每5秒刷新一次
查看运行中的进行和任务,stress对2快cpu使用率过高
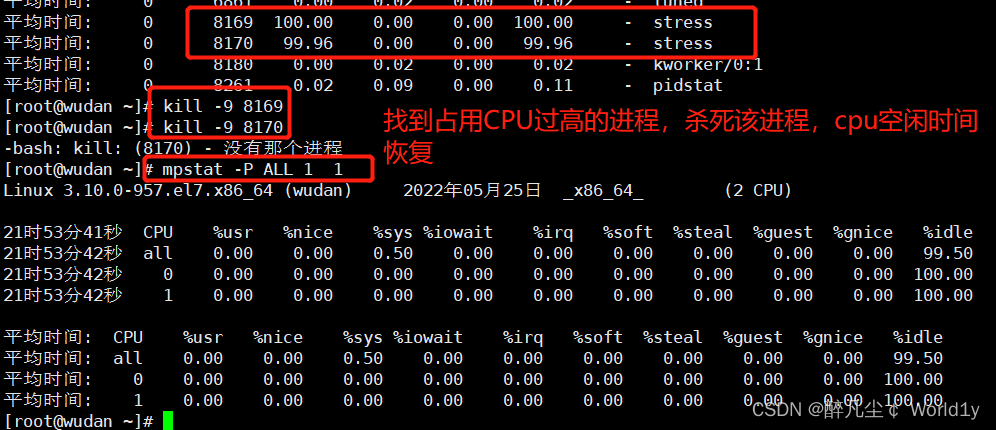
解决问题
kill -9 PID(号) 杀死相应负载过大的进程,释放cpu负载
3、模拟I/O负载
使用stress工具进行压力测试
stress --io 10 --timeout 600
进行压力测试,产生10个进程,持续600秒
-i : --io 产生n个进程,每个进程反复调用 将内存上的内容写到硬盘上

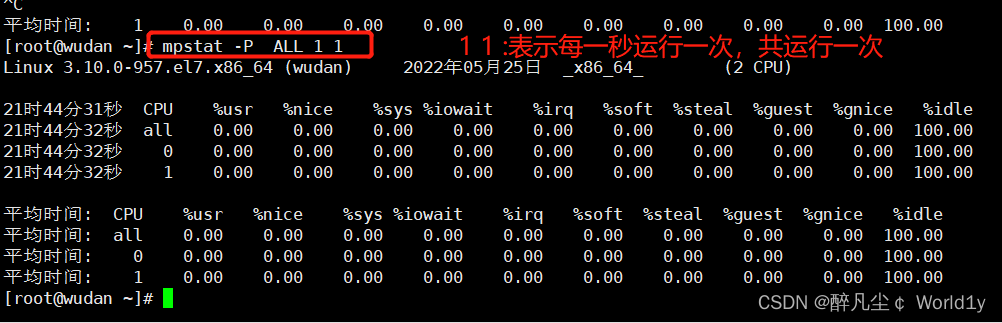
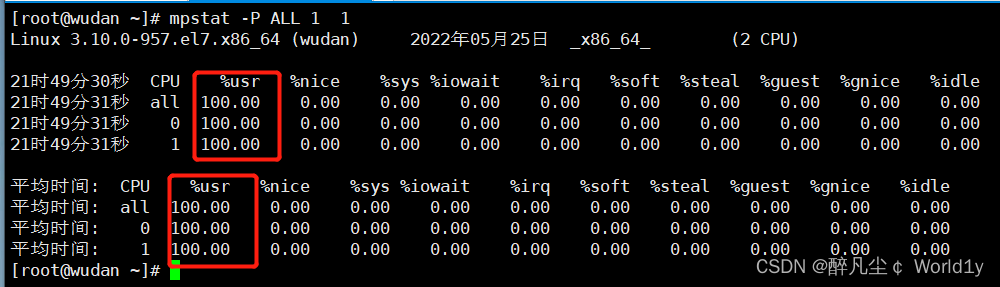
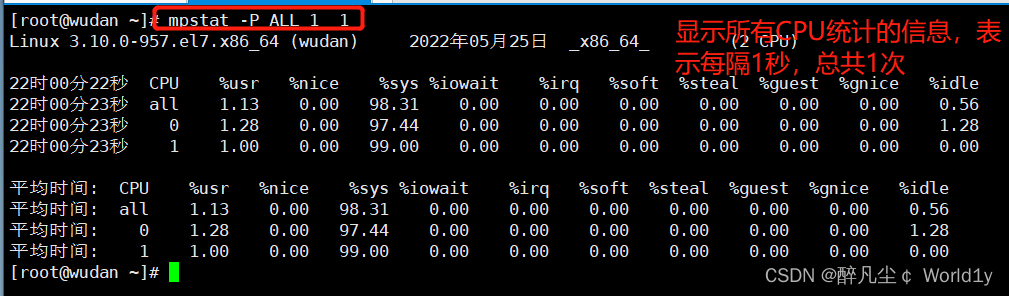
mpstat -P ALL 1 2
显示所有CPU统计的信息,表示每隔1秒,总共2次
注:使用stress无法模拟iowait升高,但sys(表示内核进程使用的 CPU 百分比。)升高。stress -i参数表示通过系统调用sync来模拟IO问题,但sync是刷新内存缓冲区数据到磁盘中,以确保同步。如果内存缓冲区内没多少数据,读写到磁盘中的数据也就不多,没法产生IO压力。使用SSD(固态硬盘)磁盘的环境中尤为明显,iowait一直为0,但因为大量系统调用,导致系统CPU使用率sys升高。
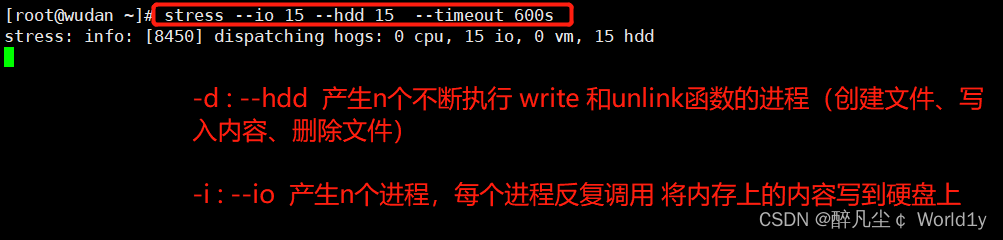
stress --io 15 --hdd 15 --timeout 600s
-d : --hdd 产生n个不断执行 write 和unlink函数的进程(创建文件、写入内容、删除文件)
-i : --io 产生n个进程,每个进程反复调用 将内存上的内容写到硬盘上
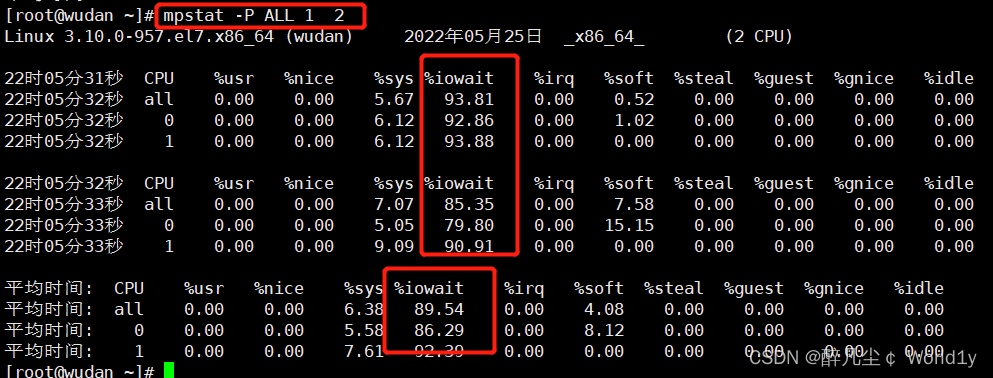
mpstat -P ALL 1 2
显示所有CPU统计的信息,表示每隔1秒,总共2次Io 读写占用百分比过高
查看正在进行的进程pid号
找到异常原因
查看是哪个进程导致I/O读写过高
pidstat -d 1 3(-d参数查看各进程io情况)
Stress 占用进程导致io读写过高
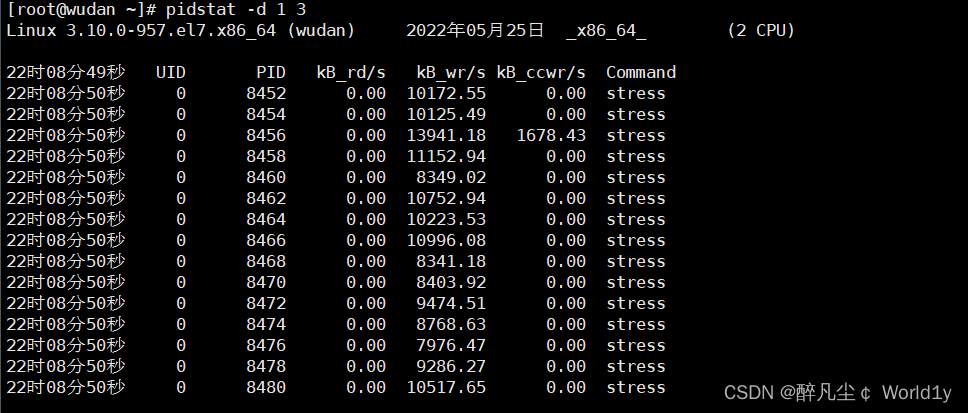
找到相应进程,将问题进程杀死
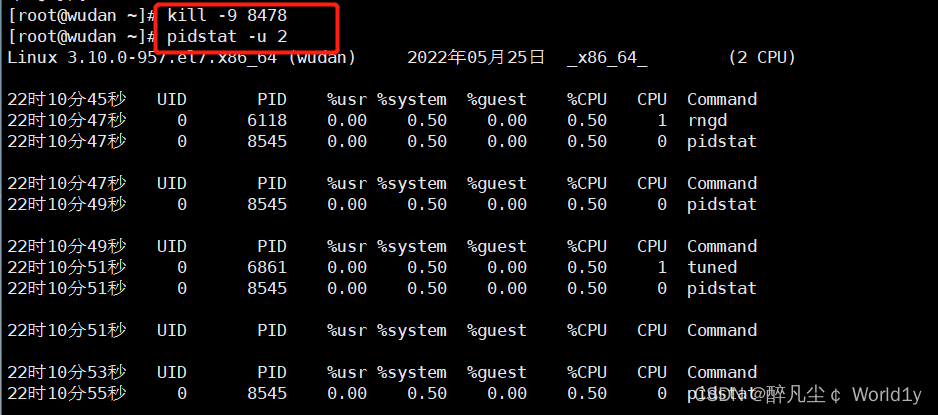
解决问题
杀死进程后,mpstat命令查看
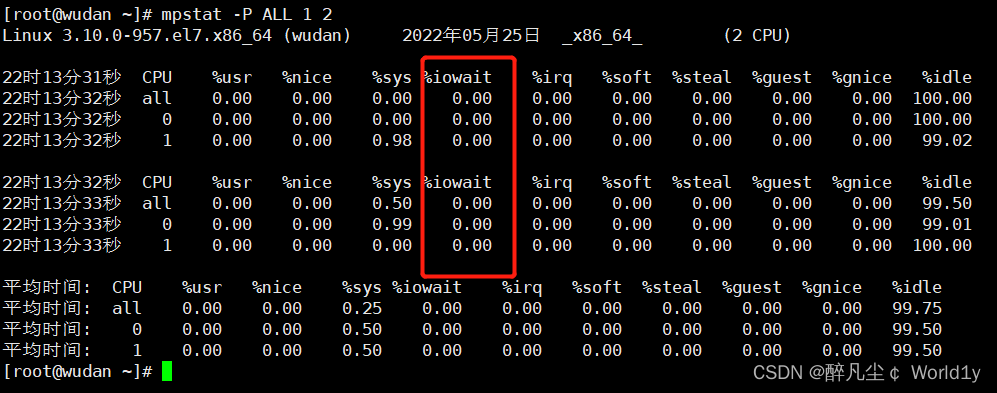
4、模拟大量进程场景
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。比如,我们还是使用 stress,但这次模拟的是 20 个进程

由于系统只有 2个 CPU,因而,系统的 CPU 处于严重过载状态,平均负载高达 16.

接着再运行 pidstat 来看一下进程的情况
pidstat -u 1 2
#显示各个进程的CPU使用统计 每1秒刷新一次,总共执行2次
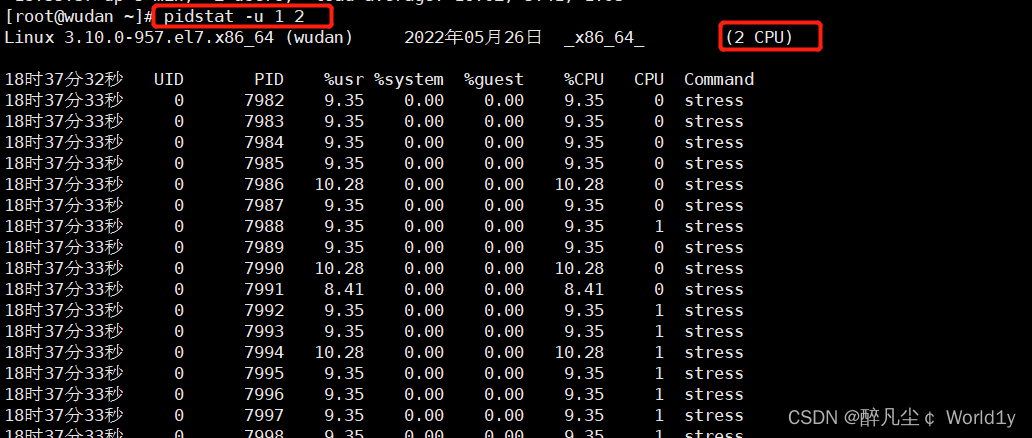
可以通过平均负载知道cpu是处于负载的状况。
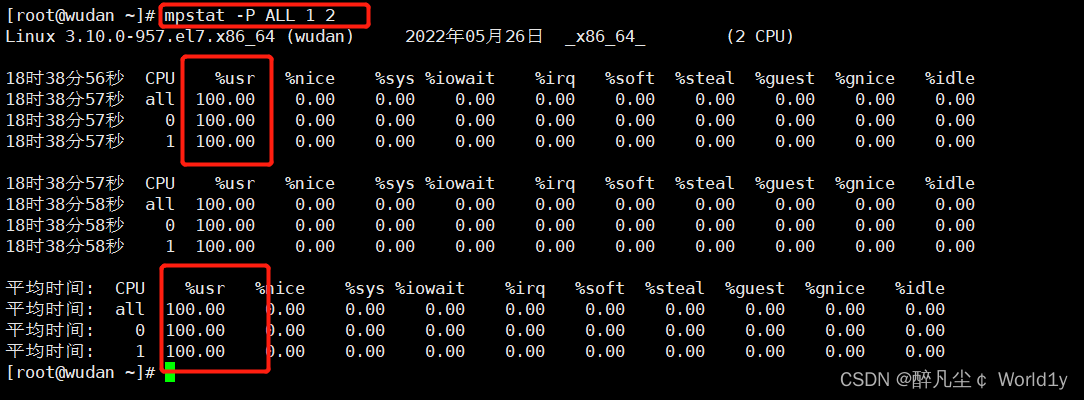
mpstat -P ALL 1 2
#-P 查看所有cpu 间隔1秒,执行2次
五、总结
cpu使用率是单位时间内cpu繁忙情况的统计,跟系统平均负载不一定完全对应,系统中存在大量等待cpu调度的进程,会使load average平均负载和cpu使用率都升高,mpstat的全称为Multiprocessor Statistics,是一款常用的多核CPU性能分析工具,用来实时查询每个CPU的性能指标,以及所有CPU的平均指标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









